ホーム » 統計検定1級 2019年 統計数理 (ページ 2)
「統計検定1級 2019年 統計数理」カテゴリーアーカイブ
2019 Q3(5)
関数の期待値がゼロになる条件を求めました。
コード
u(Y)を与え、E[u(Y)]を求めるシミュレーションをします。
まずは適当な を与え、
を与え、![E[u(Y)]](https://statistics.blue/wp-content/ql-cache/quicklatex.com-40e230ae5e7cd756a328a1ea1d5632a8_l3.png "Rendered by QuickLaTeX.com") を求めてみます。
を求めてみます。
# 2019 Q3(5) 2024.9.21
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
theta_true = 10 # 真のθ
n = 15 # サンプルサイズ
num_simulations = 10000 # シミュレーション回数
# 仮の関数 u(Y) を定義(θと期待値に基づいた関数)
def u(Y, theta, n):
# 例として、Y の関数として適当に定義(例えば u(Y) = Y^2 - 2Y)
return Y**2 - 2*Y
# シミュレーションでの最大値Yを格納するリスト
max_values = []
# シミュレーション開始
for _ in range(num_simulations):
# U(0, theta_true) から n 個の乱数を生成
samples = np.random.uniform(0, theta_true, n)
# その中での最大値Yを記録
max_values.append(np.max(samples))
# 関数 u(Y) に基づく E[u(Y)] を計算
u_values = [u(y, theta_true, n) for y in max_values]
expected_u_Y = np.mean(u_values)
# 結果の表示
print(f"シミュレーションによる E[u(Y)]: {expected_u_Y}")
# u(Y) の値のヒストグラムを描画
plt.hist(u_values, bins=30, density=True, alpha=0.7, color='blue', edgecolor='black', label='u(Y) のシミュレーション結果')
# 期待値の線を追加
plt.axvline(expected_u_Y, color='red', linestyle='--', label=f'期待値 E[u(Y)] = {expected_u_Y:.4f}')
# グラフ設定
plt.title('関数 u(Y) の分布と期待値')
plt.xlabel('u(Y) の値')
plt.ylabel('密度')
plt.legend()
plt.grid(True)
plt.show()シミュレーションによる E[u(Y)]: 69.66620056705366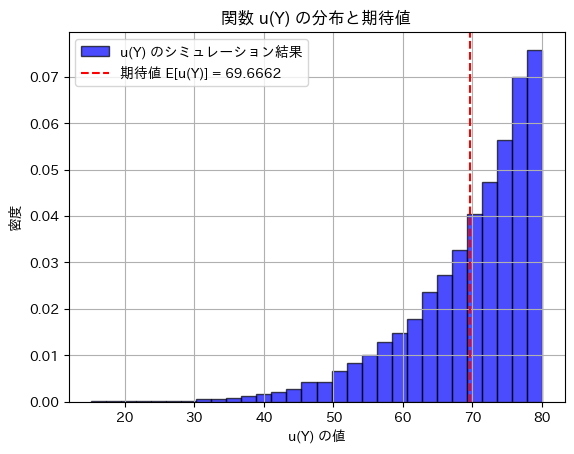
![E[u(Y)]=0](https://statistics.blue/wp-content/ql-cache/quicklatex.com-6d357b31db281f446404f46df97f452c_l3.png "Rendered by QuickLaTeX.com") にはなりませんでした。
にはなりませんでした。
次に を与え、を求めてみます。
を与え、を求めてみます。
# 2019 Q3(5) 2024.9.21
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
theta_true = 10 # 真のθ
n = 15 # サンプルサイズ
num_simulations = 10000 # シミュレーション回数
# 仮の関数 u(Y) を定義(θと期待値に基づいた関数)
def u(Y, theta, n):
# 例: 0
return 0
# シミュレーションでの最大値Yを格納するリスト
max_values = []
# シミュレーション開始
for _ in range(num_simulations):
# U(0, theta_true) から n 個の乱数を生成
samples = np.random.uniform(0, theta_true, n)
# その中での最大値Yを記録
max_values.append(np.max(samples))
# 関数 u(Y) に基づく E[u(Y)] を計算
u_values = [u(y, theta_true, n) for y in max_values]
expected_u_Y = np.mean(u_values)
# 結果の表示
print(f"シミュレーションによる E[u(Y)]: {expected_u_Y}")
# u(Y) の値のヒストグラムを描画
plt.hist(u_values, bins=30, density=True, alpha=0.7, color='blue', edgecolor='black', label='u(Y) のシミュレーション結果')
# 期待値の線を追加
plt.axvline(expected_u_Y, color='red', linestyle='--', label=f'期待値 E[u(Y)] = {expected_u_Y:.4f}')
# グラフ設定
plt.title('関数 u(Y) の分布と期待値')
plt.xlabel('u(Y) の値')
plt.ylabel('密度')
plt.legend()
plt.grid(True)
plt.show()シミュレーションによる E[u(Y)]: 0.0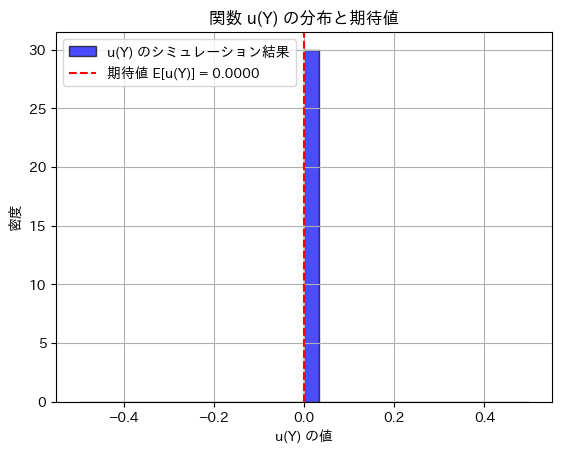
になりました。
次に を与え、を求めてみます。
を与え、を求めてみます。
# 2019 Q3(5) 2024.9.21
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
theta_true = 10 # 真のθ
n = 15 # サンプルサイズ
num_simulations = 10000 # シミュレーション回数
# 仮の関数 u(Y) を定義(θと期待値に基づいた関数)
def u(Y, theta, n):
# 例: Y - n/(n+1) * θ
return Y - (n / (n + 1)) * theta
# シミュレーションでの最大値Yを格納するリスト
max_values = []
# シミュレーション開始
for _ in range(num_simulations):
# U(0, theta_true) から n 個の乱数を生成
samples = np.random.uniform(0, theta_true, n)
# その中での最大値Yを記録
max_values.append(np.max(samples))
# 関数 u(Y) に基づく E[u(Y)] を計算
u_values = [u(y, theta_true, n) for y in max_values]
expected_u_Y = np.mean(u_values)
# 結果の表示
print(f"シミュレーションによる E[u(Y)]: {expected_u_Y}")
# u(Y) の値のヒストグラムを描画
plt.hist(u_values, bins=30, density=True, alpha=0.7, color='blue', edgecolor='black', label='u(Y) のシミュレーション結果')
# 期待値の線を追加
plt.axvline(expected_u_Y, color='red', linestyle='--', label=f'期待値 E[u(Y)] = {expected_u_Y:.4f}')
# グラフ設定
plt.title('関数 u(Y) の分布と期待値')
plt.xlabel('u(Y) の値')
plt.ylabel('密度')
plt.legend()
plt.grid(True)
plt.show()シミュレーションによる E[u(Y)]: -0.0069045066145089744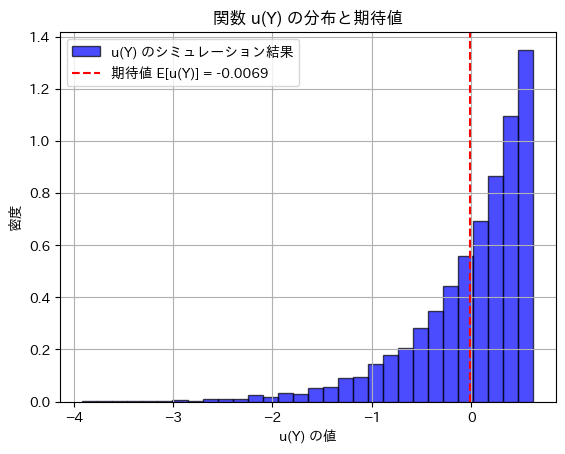
に近い値を取りました。でなくてもになるのはなぜでしょうか。おそらくこの問は にθが含まれない前提になっているのでしょう。
にθが含まれない前提になっているのでしょう。
2019 Q3(4)
一様分布に従う複数の確率変数がとる最大値の期待値と、その最大値から上限θの不偏推定量を求めました。
コード
数式を使って期待値E(Y)とθの不偏推定量を求めます。
# 2019 Q3(4) 2024.9.20
import sympy as sp
# シンボリック変数の定義
y, theta, n = sp.symbols('y theta n', positive=True, real=True)
# 最大値Yの確率密度関数 f_Y(y)
f_Y = (n / theta**n) * y**(n-1)
# 期待値 E[Y] の定義
E_Y = sp.integrate(y * f_Y, (y, 0, theta))
# 期待値 E[Y] の表示
print(f"E[Y] の導出結果:")
display(sp.simplify(E_Y))
# 改行を追加
print()
# 新しいシンボリック変数Yの定義
Y = sp.symbols('Y', positive=True, real=True)
# 理論的な E[Y] の式(E[Y] = n/(n+1) * theta)
theoretical_E_Y = (n / (n + 1)) * theta
# Y を基にして theta を求める方程式を解く
theta_hat = sp.solve(Y - theoretical_E_Y, theta)[0]
# 不偏推定量の結果表示
print(f"不偏推定量 θ̂ の導出結果:")
display(theta_hat)
式の形は少し違いますが正しいですね。
次に、数値シミュレーションにより期待値E(Y)とθの不偏推定量求め理論値と比較します。
# 2019 Q3(4) 2024.9.20
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
theta_true = 10 # 真のθ
n = 15 # サンプルサイズ
num_simulations = 10000 # シミュレーション回数
# シミュレーションでの最大値Yを格納するリスト
max_values = []
# シミュレーション開始
for _ in range(num_simulations):
# U(0, theta_true) から n 個の乱数を生成
samples = np.random.uniform(0, theta_true, n)
# その中での最大値Yを記録
max_values.append(np.max(samples))
# シミュレーションによる期待値E[Y]を計算
simulated_E_Y = np.mean(max_values)
# 理論値E[Y]を計算
theoretical_E_Y = (n / (n + 1)) * theta_true
# 不偏推定量のシミュレーション
theta_hat_simulated = (n + 1) / n * np.mean(max_values)
# 結果の表示
print(f"シミュレーションによる E[Y]: {simulated_E_Y}")
print(f"理論値 E[Y]: {theoretical_E_Y}")
print(f"シミュレーションによる不偏推定量 θ̂: {theta_hat_simulated}")
print(f"真の θ: {theta_true}")
# ヒストグラムを描画して結果を視覚化
plt.hist(max_values, bins=30, density=True, alpha=0.7, color='blue', edgecolor='black', label='シミュレーション結果')
plt.axvline(simulated_E_Y, color='red', linestyle='--', label=f'シミュレーション E[Y] = {simulated_E_Y:.2f}')
plt.axvline(theoretical_E_Y, color='green', linestyle='--', label=f'理論値 E[Y] = {theoretical_E_Y:.2f}')
# グラフ設定
plt.title('最大値Yの分布とE[Y]')
plt.xlabel('Y の値')
plt.ylabel('密度')
plt.legend()
plt.grid(True)
plt.show()シミュレーションによる E[Y]: 9.384118720046189
理論値 E[Y]: 9.375
シミュレーションによる不偏推定量 θ̂: 10.009726634715935
真の θ: 10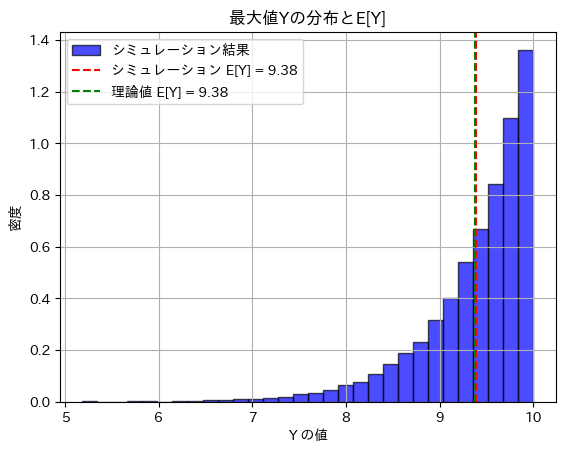
期待値E(Y)とθの不偏推定量は理論値に近い値を取りました。
2019 Q3(3)
一様分布の最大値を条件とする条件付き同時確率密度関数の問題をやりました。

コード
一様分布の最大値を条件とする条件付き同時確率密度関数が

となるかをシミュレーションで確認しました。Yを1~10に変化させて、Y以下の乱数を発生させてカーネル密度推定で同時確率密度を計算します。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gaussian_kde
# パラメータ設定
n = 15 # サンプルサイズ
num_simulations = 10000 # シミュレーション回数
Y_values = np.arange(1, 11, 1) # Y を 1 から 10 に変化させる
# シミュレーション結果を格納するリスト
simulated_f_values = [] # シミュレーションによる f の値
theoretical_f_values = [] # 理論値 f(x_1, ..., x_{n-1} | Y=y)
# シミュレーション開始
for Y in Y_values:
f_sim_sum = 0 # f(x_1, ..., x_{n-1} | Y=y) の合計
for _ in range(num_simulations):
# Y より小さい範囲で n-1 個のサンプルを生成し、観測された最大値 Y を追加
samples = np.random.uniform(0, Y, n-1)
samples = np.append(samples, Y) # 観測値としての Y を追加
# カーネル密度推定を実行
kde = gaussian_kde(samples) # サンプルに基づいてKDEを実行
# samples から Y (最後の要素) を除いた部分で密度を計算
f_sim = np.prod(kde.evaluate(samples[:-1])) # サンプルごとの確率密度を掛け合わせる
# f(y) = 1 として扱う(条件付き分布)
f_sim_sum += f_sim
# シミュレーション結果の平均をリストに追加
simulated_f_values.append(f_sim_sum / num_simulations)
# 理論値 1 / Y^(n-1) を計算
theoretical_f_values.append(1 / Y**(n-1))
# グラフ描画
plt.plot(Y_values, simulated_f_values, 'bo-', label='シミュレーション結果')
plt.plot(Y_values, theoretical_f_values, 'r--', label='理論値 1/Y^(n-1)')
# 縦軸を対数スケールに変更
plt.yscale('log')
# グラフ設定
plt.title(f'f(x1, ..., xn-1 | Y=y) のシミュレーション結果と理論値 (n={n})')
plt.xlabel('Y の値')
plt.ylabel('f(x1, ..., xn-1 | Y=y)')
plt.legend()
plt.grid(True)
plt.show()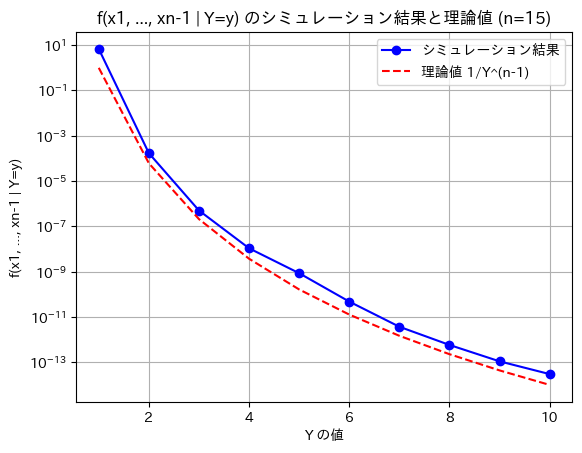
概ね理論値と一致しました。カーネル密度推定の誤差により、シミュレーションの値は理論値より少し大きくなっていると思われます。
2019 Q3(2)
一様分布の最大値をとる確率変数の確率密度関数を求めました。
コード
数式を使って確率密度関数g(y)を求めます。
# 2019 Q3(2) 2024.9.18
import sympy as sp
# 変数を定義
y, theta, n = sp.symbols('y theta n')
# 累積分布関数 F_Y(y) を定義
F_Y = (y / theta)**n # F_Y(y) = (y / θ)^n
# 確率密度関数 g(y) を F_Y(y) の y に関する微分として計算
g_y = sp.diff(F_Y, y)
# 簡略化
g_y_simplified = sp.simplify(g_y)
# 結果を表示
display(g_y_simplified)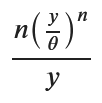
形は少し違いますが、正しいです。
得られた確率密度関数g(y)と数値シミュレーションによる分布と比較します。
import numpy as np
import matplotlib.pyplot as plt
# パラメータ
n = 10 # サンプルサイズ(n個の一様分布からのサンプル)
theta = 10 # 一様分布の上限
num_simulations = 10000 # シミュレーション回数
# 最大値 Y のリスト
Y_values = []
# シミュレーション
for _ in range(num_simulations):
samples = np.random.uniform(0, theta, n) # (0, θ)の範囲からn個のサンプルを生成
Y = np.max(samples) # 最大値を計算
Y_values.append(Y)
# ヒストグラムを描画
plt.hist(Y_values, bins=30, density=True, alpha=0.7, color='blue', edgecolor='black', label='シミュレーション結果')
# 理論上の確率密度関数を描画
y = np.linspace(0, theta, 1000)
g_y = (n / theta**n) * y**(n-1)
plt.plot(y, g_y, color='red', label='理論的な分布')
# グラフの設定
plt.title(f'最大値 Y の分布と理論的分布 (n={n}, θ={theta})')
plt.xlabel('最大値 Y')
plt.ylabel('確率密度')
plt.legend()
plt.show()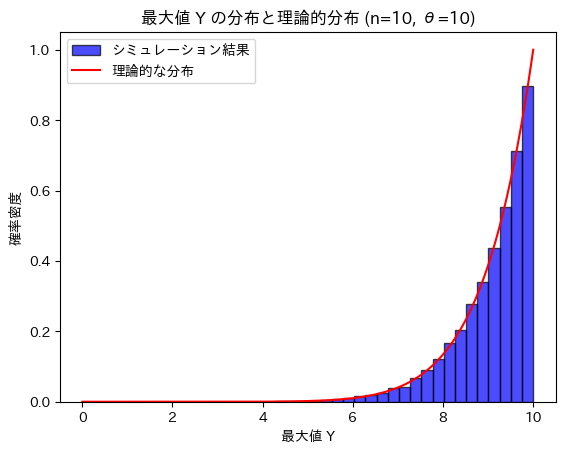
確率密度関数g(y)と数値シミュレーションによる分布は一致することが確認できました。
2019 Q3(1)
一様分布に於いて最大値が十分統計量であることを示しました。

コード
一様分布の最大値Yを元に、不偏推定量 を計算します。
を計算します。
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションパラメータ
n = 10 # サンプルサイズ
theta_true = 10 # 真のθ
num_simulations = 1000 # シミュレーション回数
# θの推定値を格納するリスト
theta_estimates = []
# シミュレーション開始
for _ in range(num_simulations):
# (0, theta_true) の一様分布からn個のサンプルを生成
samples = np.random.uniform(0, theta_true, n)
# 最大値 Y = max(X_1, ..., X_n)
Y = np.max(samples)
# Y から θ を推定 (最大値を使って推定)
theta_hat = Y * (n / (n - 1)) # 推定式: Y * n / (n-1)
# 推定されたθをリストに保存
theta_estimates.append(theta_hat)
# θの推定値の平均を計算
theta_mean = np.mean(theta_estimates)
# 推定結果をヒストグラムで表示
plt.hist(theta_estimates, bins=30, alpha=0.7, color='blue', edgecolor='black', label='推定されたθ')
plt.axvline(x=theta_true, color='red', linestyle='--', label=f'真のθ = {theta_true}')
plt.axvline(x=theta_mean, color='green', linestyle='--', label=f'推定されたθの平均 = {theta_mean:.2f}')
plt.title(f'Y (最大値) に基づく θ の推定値のヒストグラム ({n} サンプル)')
plt.xlabel('推定された θ')
plt.ylabel('頻度')
plt.legend()
plt.show()
# 推定結果をテキストで表示
print(f'真のθ: {theta_true}')
print(f'推定されたθの平均: {theta_mean:.2f}')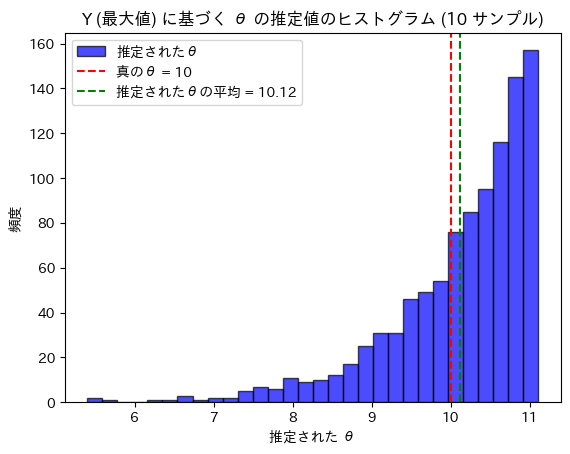
真のθ: 10
推定されたθの平均: 10.12推定されたθは真のθに近い値を取りました。最大値Yだけを用いてθが正確に推定できたので、Yはθに関する十分統計量であることが確認できました。
2019 Q2(4)
損失関数の期待値を導出しそれが最小となるパラメータαを求める問題をやりました。
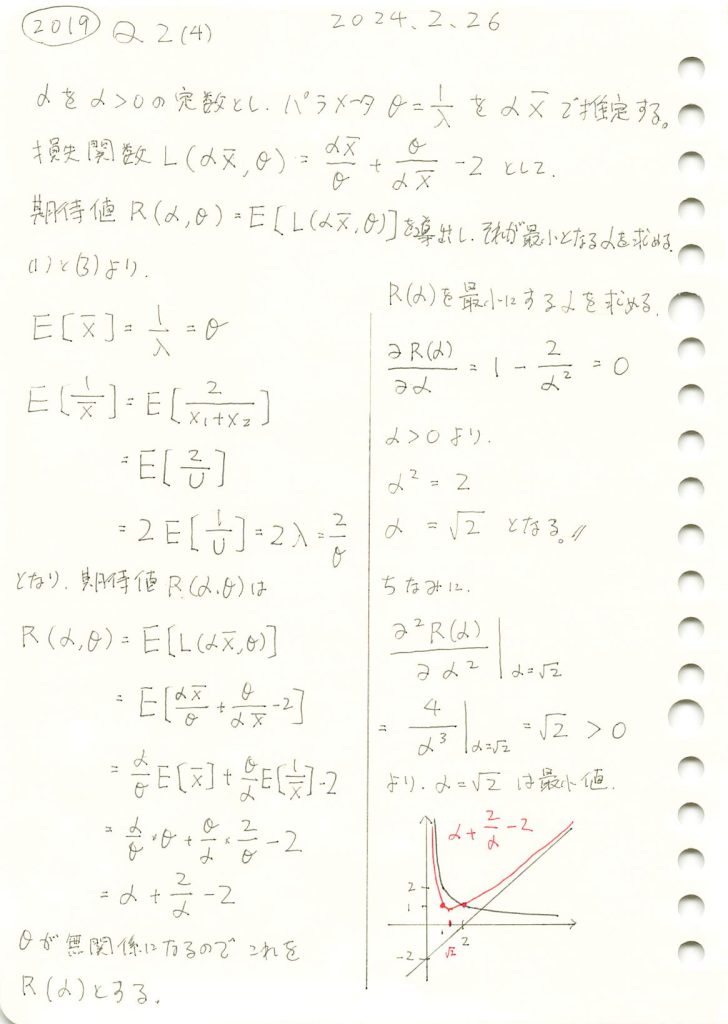
コード
数値シミュレーションによりR(α)が最小値になるαを見つけます。
# 2019 Q2(4) 2024.9.16
import numpy as np
import matplotlib.pyplot as plt
# 損失関数 R(α) の定義
def R(alpha):
return alpha + 2 / alpha - 2
# α の範囲を設定 (0.1 から 3 まで、細かいステップで計算)
alpha_range = np.linspace(0.1, 3, 1000)
# 損失関数 R(α) の計算
R_values = R(alpha_range)
# 最小値を取る α の確認 (numpy の argmin を使って最小値を見つける)
min_index = np.argmin(R_values)
min_alpha = alpha_range[min_index]
min_R = R_values[min_index]
# グラフのプロット
plt.figure(figsize=(8, 6))
plt.plot(alpha_range, R_values, label='R(α)')
plt.axvline(np.sqrt(2), color='red', linestyle='--', label=r'$\alpha = \sqrt{2}$')
plt.scatter(min_alpha, min_R, color='red', zorder=5, label=f'最小値: α={min_alpha:.2f}, R(α)={min_R:.2f}')
plt.xlabel(r'$\alpha$')
plt.ylabel(r'$R(\alpha)$')
plt.title(r'$R(\alpha)$ の最小値確認 (数値シミュレーション)')
plt.legend()
plt.grid(True)
plt.show()
# 最小値の表示
print(f'数値シミュレーションでの最小値 α: {min_alpha}, R(α): {min_R}')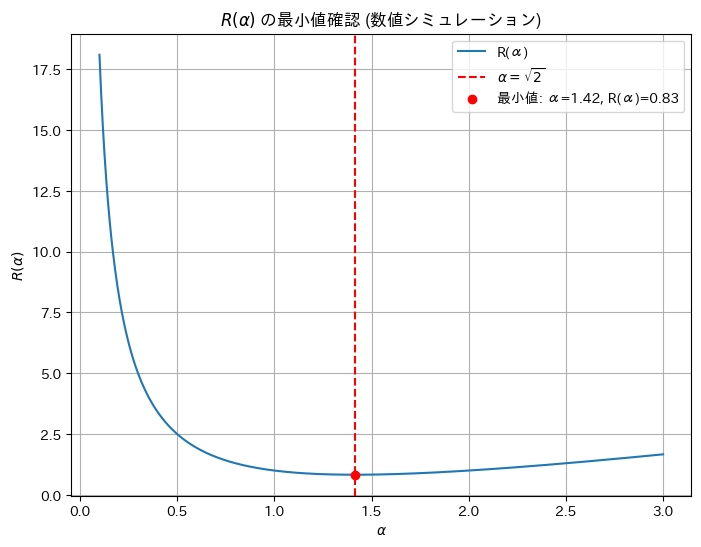
数値シミュレーションでの最小値 α: 1.4150150150150151, R(α): 0.8284275786822475手計算と近い値になりました。
極値付近が少し平らなので、αの範囲を1.0~2.0に変更し拡大してみます。
import numpy as np
import matplotlib.pyplot as plt
# 損失関数 R(α) の定義
def R(alpha):
return alpha + 2 / alpha - 2
# α の範囲を 1 から 2 に設定
alpha_range = np.linspace(1, 2, 1000)
# 損失関数 R(α) の計算
R_values = R(alpha_range)
# 最小値を取る α の確認 (numpy の argmin を使って最小値を見つける)
min_index = np.argmin(R_values)
min_alpha = alpha_range[min_index]
min_R = R_values[min_index]
# グラフのプロット
plt.figure(figsize=(8, 6))
plt.plot(alpha_range, R_values, label='R(α)')
plt.axvline(np.sqrt(2), color='red', linestyle='--', label=r'$\alpha = \sqrt{2}$')
plt.scatter(min_alpha, min_R, color='red', zorder=5, label=f'最小値: α={min_alpha:.4f}, R(α)={min_R:.4f}')
plt.xlabel(r'$\alpha$')
plt.ylabel(r'$R(\alpha)$')
plt.title(r'$R(\alpha)$ の最小値確認 (αの範囲: 1 から 2)')
plt.legend()
plt.grid(True)
plt.show()
# 最小値の表示
print(f'数値シミュレーションでの最小値 α: {min_alpha}, R(α): {min_R}')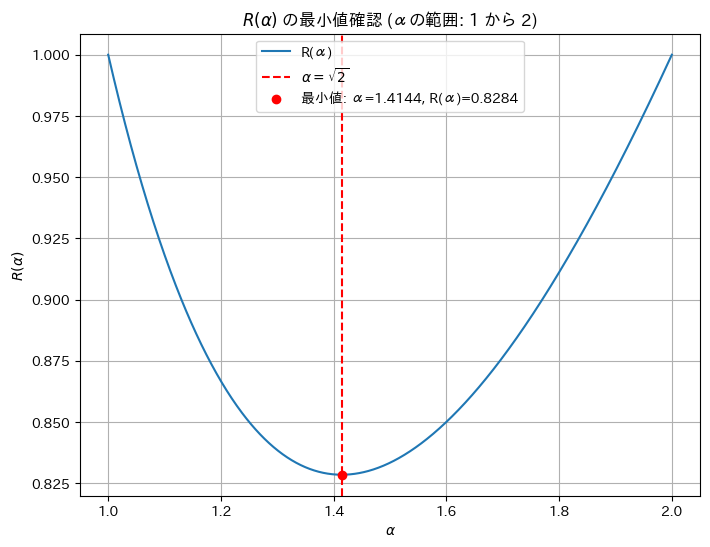
数値シミュレーションでの最小値 α: 1.4144144144144144, R(α): 0.8284271532679175最小値が取れていることが分かりました。
2019 Q2(3)
(2)で求めた確率密度関数において確率変数Uの逆数の期待値を求めました。
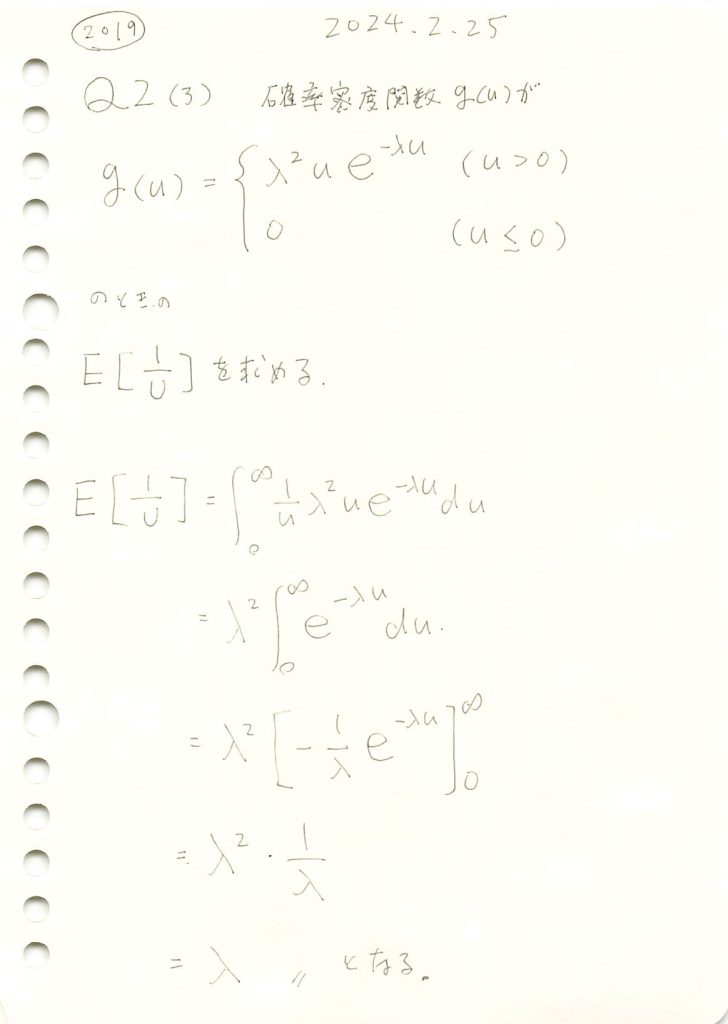
コード
数式を使って1/Uの期待値を求めます。
# 2019 Q2(3) 2024.9.15
import sympy as sp
# 変数の定義
u, lambda_value = sp.symbols('u lambda', positive=True, real=True)
# ガンマ分布の確率密度関数 g(u) = λ^2 * u * exp(-λ * u)
g_u = lambda_value**2 * u * sp.exp(-lambda_value * u)
# 1/U の期待値の積分
integrand = (1/u) * g_u # 1/u * g(u)
# 積分の実行
expectation = sp.integrate(integrand, (u, 0, sp.oo))
# 結果の簡略化
expectation_simplified = sp.simplify(expectation)
# 結果の表示
display(expectation_simplified)
手計算と一致します。
次に、数値シミュレーションを行います。
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
lambda_value = 2 # λ=2
num_samples = 100000 # サンプルの数
# 指数分布に従う乱数 X1, X2 を生成
X1 = np.random.exponential(scale=1/lambda_value, size=num_samples)
X2 = np.random.exponential(scale=1/lambda_value, size=num_samples)
# U = X1 + X2 の計算
U = X1 + X2
# 1/U の計算
inv_U = 1 / U
# シミュレーションの結果からの平均値
simulation_result = np.mean(inv_U)
# 理論値 E[1/U] = λ
theoretical_value = lambda_value
# 結果の表示
print(f'シミュレーションによる E[1/U]: {simulation_result}')
print(f'理論値 E[1/U]: {theoretical_value}')
# ヒストグラムの描画
plt.hist(inv_U, bins=50, density=True, alpha=0.7, label='シミュレーション結果')
plt.axvline(theoretical_value, color='r', linestyle='--', label=f'理論値 E[1/U] = {theoretical_value}')
plt.xlabel('1/U')
plt.ylabel('確率密度')
plt.title('シミュレーションによる 1/U の分布と理論値の比較')
plt.legend()
plt.show()シミュレーションによる E[1/U]: 1.9928303711222939
理論値 E[1/U]: 2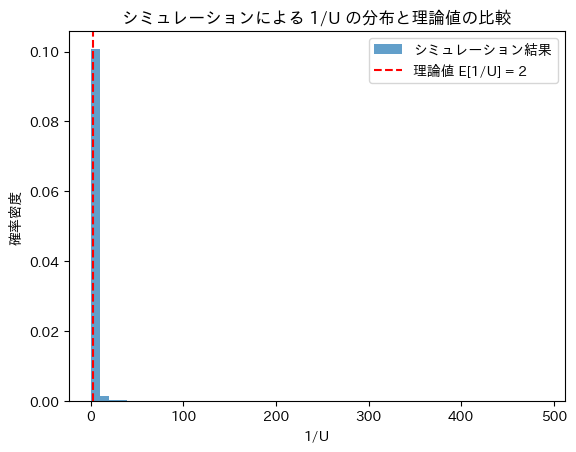
シミュレーションによりE[1/U]は理論値に近づきました。分散は発散するためヒストグラムにすると大きなバラつきが見られます。
2019 Q2(2)
独立な指数分布に従う2変数の和の確率密度関数を求めました。

コード
数式を使ってUの確率密度関数を求めます。
# 2019 Q2(2) 2024.9.14
import sympy as sp
# 変数の定義
x, u, lambda_value = sp.symbols('x u lambda', positive=True, real=True)
# 指数分布の確率密度関数 (PDF) f(x)
f_x = lambda_value * sp.exp(-lambda_value * x)
# 畳み込み積分を計算して、g(u) = f(x) * f(u - x) の形式にする
g_u = sp.integrate(f_x * lambda_value * sp.exp(-lambda_value * (u - x)), (x, 0, u))
# 簡略化
g_u_simplified = sp.simplify(g_u)
# 結果の表示
display(g_u_simplified)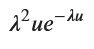
X1 (X2)と、Uの確率密度関数を重ねて描画してみます。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
# パラメータ設定
lambda_value = 2 # λ=2
x_range = np.linspace(0, 5, 1000) # X1, X2 の範囲
# X1, X2 の指数分布の確率密度関数 (PDF) - 同じなので1つにまとめる
pdf_X1_X2 = lambda_value * np.exp(-lambda_value * x_range)
# U = X1 + X2 は形状パラメータk=2、スケールパラメータθ=1/λのガンマ分布
u_range = np.linspace(0, 10, 1000)
pdf_U = gamma.pdf(u_range, a=2, scale=1/lambda_value)
# グラフのプロット
plt.figure(figsize=(8, 6))
# X1 (X2) の指数分布の描画
plt.plot(x_range, pdf_X1_X2, label='X1 (X2) (指数分布)', color='blue', linestyle='--')
# U のガンマ分布の描画
plt.plot(u_range, pdf_U, label='U = X1 + X2 (ガンマ分布)', color='red')
# グラフの装飾
plt.title('X1 (X2) と U の確率密度関数の比較')
plt.xlabel('値')
plt.ylabel('確率密度')
plt.legend()
# グラフの表示
plt.show()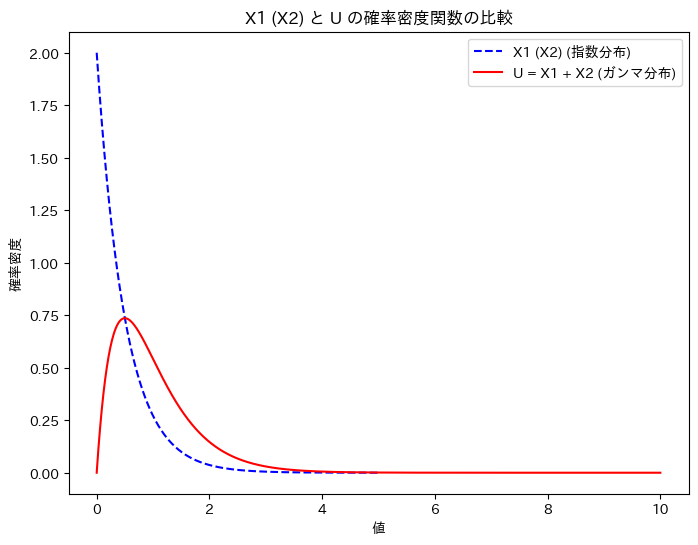
グラフの形状から、U = X1 + X2の関係は想像しづらいですね。
ガンマ分布の形状パラメータを1~2に変化させて、X1 (X2)からUへの変化を確認します。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
# パラメータ設定
lambda_value = 2 # λ=2
x_range = np.linspace(0, 5, 1000) # X1, X2, U の範囲を0~5に設定
# ガンマ分布の形状パラメータを1から2まで0.1ずつ変化させる
shape_params = np.arange(1, 2.1, 0.1) # 1から2までの形状パラメータを0.1ステップで変化
# グラフのプロット
plt.figure(figsize=(8, 6))
# 形状パラメータが1から2に変化するガンマ分布の描画
for k in shape_params:
gamma_pdf = gamma.pdf(x_range, a=k, scale=1/lambda_value)
plt.plot(x_range, gamma_pdf, label=f'形状パラメータ k={k:.1f}')
# X1 (X2) の指数分布の描画 - 同じなので1つにまとめる
pdf_X1_X2 = lambda_value * np.exp(-lambda_value * x_range)
plt.plot(x_range, pdf_X1_X2, label='X1 (X2) (指数分布)', color='blue', linestyle='--')
# グラフの装飾
plt.title('指数分布からガンマ分布への変化 (形状パラメータの0.1ステップ変化)')
plt.xlabel('値')
plt.ylabel('確率密度')
plt.legend()
# グラフの表示
plt.show()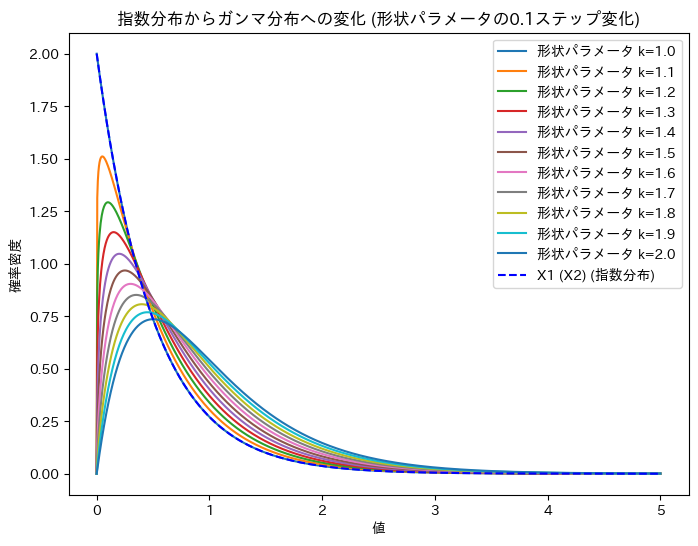
X1 (X2)からUへの変化が可視化できました。
次に、X1 (X2)と、Uの累積分布関数を重ねて描画してみます。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import expon, gamma
# パラメータ設定
lambda_value = 2 # λ=2
x_range = np.linspace(0, 5, 1000) # X1, X2 の範囲
# X1, X2 の指数分布の累積分布関数 (CDF) - 同じなので1つにまとめる
cdf_X1_X2 = expon.cdf(x_range, scale=1/lambda_value)
# U = X1 + X2 は形状パラメータk=2、スケールパラメータθ=1/λのガンマ分布
u_range = np.linspace(0, 10, 1000)
cdf_U = gamma.cdf(u_range, a=2, scale=1/lambda_value)
# グラフのプロット
plt.figure(figsize=(8, 6))
# X1 (X2) の指数分布のCDFの描画
plt.plot(x_range, cdf_X1_X2, label='X1 (X2) (指数分布 CDF)', color='blue', linestyle='--')
# U のガンマ分布のCDFの描画
plt.plot(u_range, cdf_U, label='U = X1 + X2 (ガンマ分布 CDF)', color='red')
# グラフの装飾
plt.title('X1 (X2) と U の累積分布関数 (CDF) の比較')
plt.xlabel('値')
plt.ylabel('累積確率')
plt.legend()
# グラフの表示
plt.show()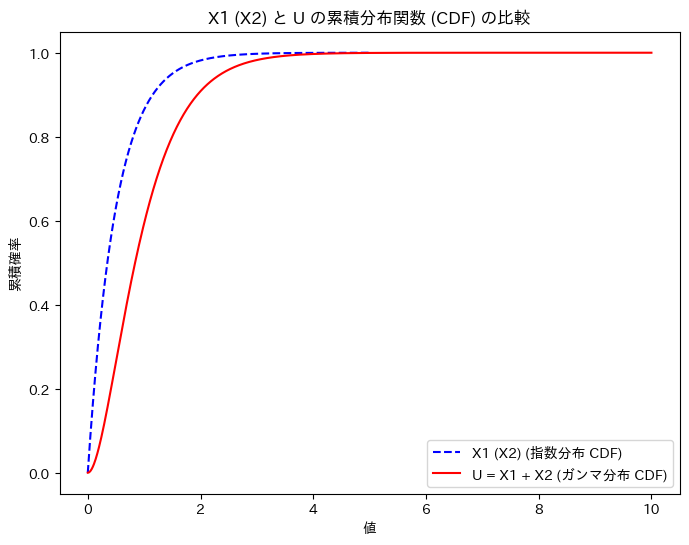
グラフの形状から、U = X1 + X2の関係を想像しやすくなりました。
2019 Q2(1)
独立な指数分布に従う2変数の和の期待値を求めました。
コード
数式を使ってUの期待値を求めます
import sympy as sp
# 変数の定義
x = sp.Symbol('x', positive=True)
lambda_value = sp.Symbol('lambda', positive=True)
# 指数分布の確率密度関数 (PDF)
f_x = lambda_value * sp.exp(-lambda_value * x)
# 期待値の式を計算 (積分)
E_X1 = sp.integrate(x * f_x, (x, 0, sp.oo))
# 期待値
E_X1_simplified = sp.simplify(E_X1)
# X1 + X2 の場合 (独立性より)
E_U = 2 * E_X1_simplified
# 結果の表示
display(E_U)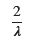
手計算と一致します
次にUに従う乱数を生成し分布を確認します。また形状パラメータ2のガンマ分布と重ねて描画します。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
# パラメータ設定
lambda_value = 2 # 例としてλ=2
num_samples = 1000 # サンプルの数
# 指数分布に従う乱数の生成
X1 = np.random.exponential(scale=1/lambda_value, size=num_samples)
X2 = np.random.exponential(scale=1/lambda_value, size=num_samples)
# U = X1 + X2 の計算
U = X1 + X2
# 理論的な期待値
expected_value = 2 / lambda_value
# シミュレーション結果のヒストグラムのプロット (確率密度にスケール)
plt.hist(U, bins=30, density=True, alpha=0.7, label='シミュレーション結果')
# ガンマ分布 (形状パラメータ k=2, スケールパラメータ θ=1/λ) の確率密度関数 (PDF) を計算
k = 2 # 形状パラメータ (k = 2)
theta = 1 / lambda_value # スケールパラメータ (θ = 1/λ)
# ガンマ分布に基づくx軸の範囲
x = np.linspace(0, max(U), 1000)
# ガンマ分布の確率密度関数 (PDF) を計算
gamma_pdf = gamma.pdf(x, a=k, scale=theta)
# ガンマ分布の折れ線グラフをプロット
plt.plot(x, gamma_pdf, 'r-', label=f'ガンマ分布 (k={k}, θ={theta:.2f})')
# グラフの装飾
plt.axvline(expected_value, color='g', linestyle='--', label=f'理論値 = {expected_value:.2f}')
plt.xlabel('U = X1 + X2')
plt.ylabel('確率密度')
plt.title('Uの分布とガンマ分布の比較')
plt.legend()
plt.show()
# 実際のサンプル平均値と理論的期待値の比較
print(f'理論的な期待値: {expected_value}')
print(f'シミュレーションからの平均値: {np.mean(U)}')
理論的な期待値: 1.0
シミュレーションからの平均値: 0.9902440726761544Uの分布と形状パラメータ2のガンマ分布は重なりました。Uはガンマ分布に従うことが分かります。
2019 Q1(4)
二項分布に従う確率変数Xの不等式が成り立つことの証明をやりました。
コード
Xが二項分布B(n,p)に従うとき、不等式 が成り立つのか可視化して確認しました。
が成り立つのか可視化して確認しました。
# 2019 Q1(4) 2024.9.12
import numpy as np
from scipy.stats import binom
import matplotlib.pyplot as plt
# パラメータ設定
n_values = [10, 30, 50] # 試行回数 n のリスト
p_values = [0.3, 0.5, 0.7] # 成功確率 p のリスト
a_values = np.linspace(0.01, 0.99, 50) # a の範囲
# サブプロットの作成
fig, axes = plt.subplots(3, 3, figsize=(15, 15)) # 3x3のグリッドでグラフを描画
# グラフの描画ループ
for i, n in enumerate(n_values):
for j, p in enumerate(p_values):
# 左辺と右辺の値を格納するリスト
left_side_values = []
right_side_values = []
for a in a_values:
# 左辺:P(X <= an) の計算
k = int(np.floor(a * n))
left_side = binom.cdf(k, n, p)
left_side_values.append(left_side)
# 右辺の計算
right_side = (p / a) ** (a * n) * ((1 - p) / (1 - a)) ** ((1 - a) * n)
right_side_values.append(right_side)
# グラフの描画(対数スケール)
ax = axes[i, j]
ax.plot(a_values, left_side_values, label='左辺 $P(X \leq an)$', color='blue')
ax.plot(a_values, right_side_values, label='右辺', color='red', linestyle='--')
# 0 < a < p の範囲に色を塗る
ax.axvspan(0, p, color='yellow', alpha=0.3, label="0<a<pの範囲")
ax.set_title(f'n={n}, p={p}')
ax.set_xlabel('$a$')
ax.set_ylabel('値 (対数スケール)')
ax.set_yscale('log') # 縦軸を対数スケールに設定
ax.legend()
ax.grid(True, which="both", ls="--") # 対数スケールのグリッド
# サブプロット間のレイアウト調整
plt.tight_layout()
plt.show()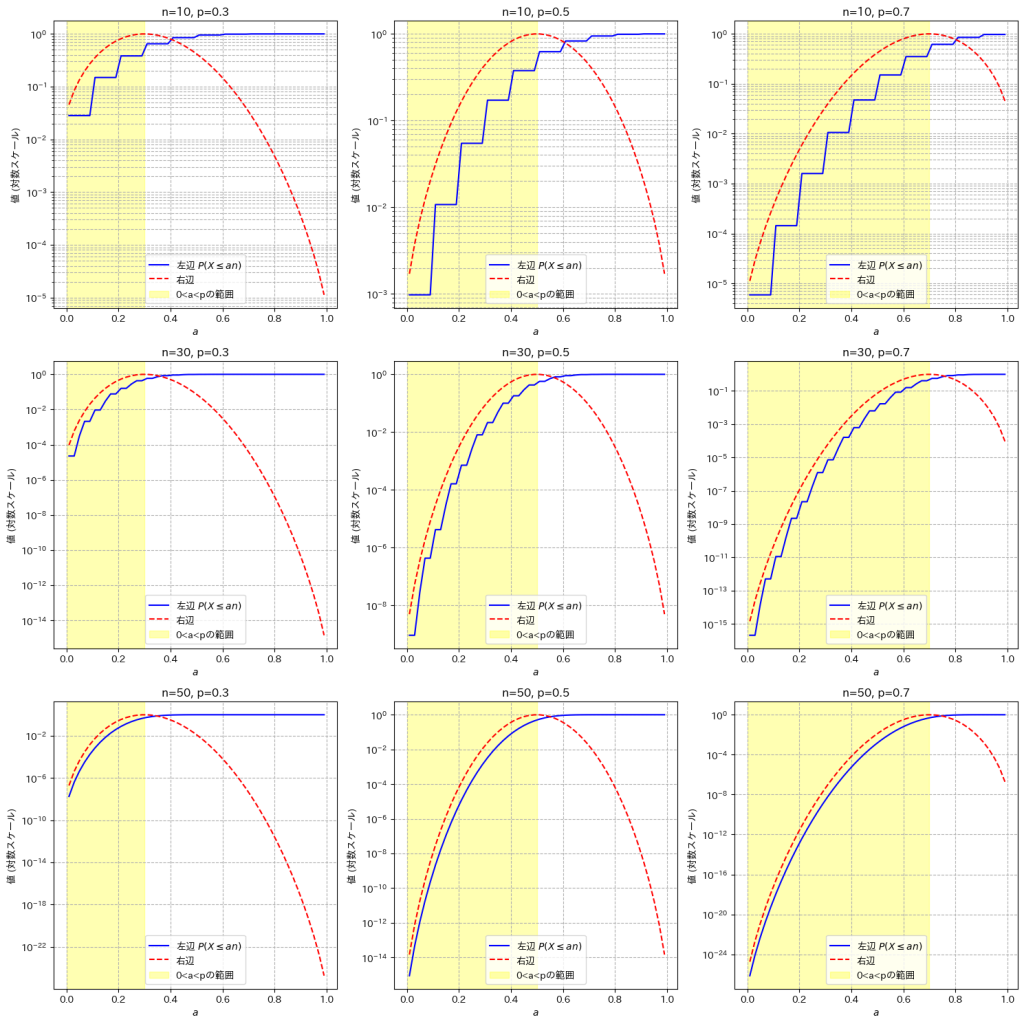
不等式は0<a<pの範囲で成り立っていることが確認できました