ホーム » 統計検定1級 2017年 統計数理 (ページ 2)
「統計検定1級 2017年 統計数理」カテゴリーアーカイブ
2017 Q2(3)
サンプルデータの最大値の(n+1)/n倍が一様分布の上限値の不偏推定量であることの証明をしました。
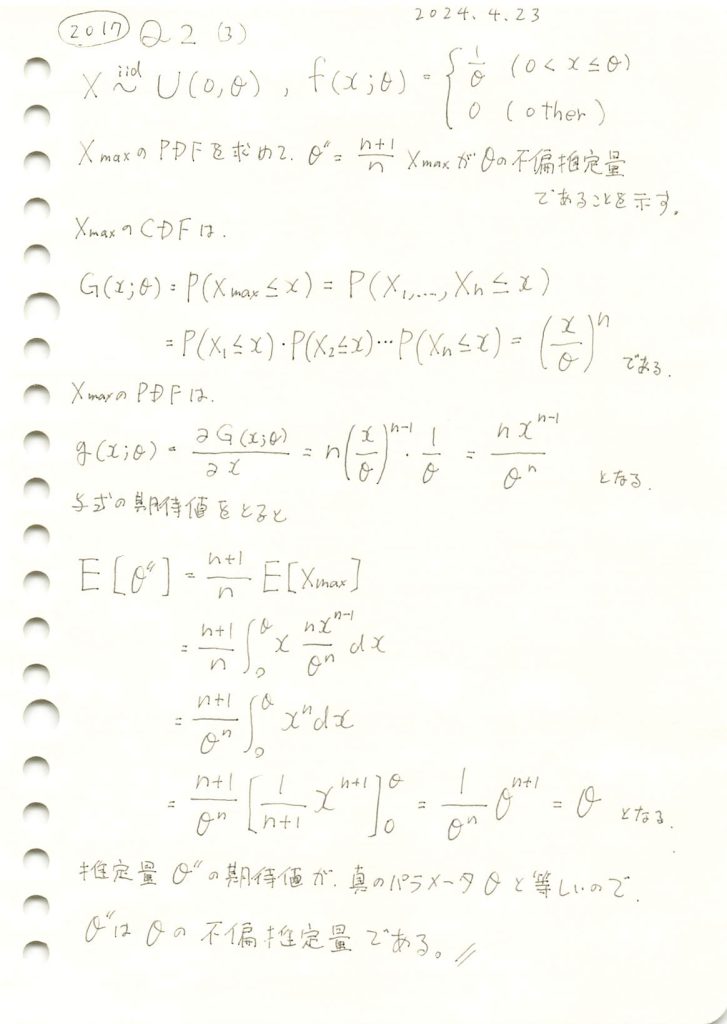
コード
θ=10,n=20としてシミュレーションを行い、θ’’の分布を見てみます。
# 2017 Q2(3) 2024.10.31
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
theta_true = 10 # 真の θ の値
n = 20 # サンプルサイズ
num_trials = 1000 # シミュレーションの試行回数
# シミュレーションを実行
theta_double_prime_estimates = []
for _ in range(num_trials):
# 一様分布 U(0, theta_true) から n 個のサンプルを生成
samples = np.random.uniform(0, theta_true, n)
# サンプルの最大値 X_max を計算し、それを用いて θ'' を計算
theta_double_prime = (n + 1) / n * np.max(samples)
theta_double_prime_estimates.append(theta_double_prime)
# θ'' の分布をヒストグラムで表示
plt.hist(theta_double_prime_estimates, bins=30, edgecolor='black', density=True)
plt.axvline(theta_true, color='red', linestyle='dashed', linewidth=1, label=f"真の θ = {theta_true}")
plt.xlabel(r'$\theta\'\' = \frac{n + 1}{n} X_{\max}$')
plt.ylabel('密度')
plt.title(r'$\theta\'\' = \frac{n + 1}{n} X_{\max}$ の分布')
plt.legend()
plt.show()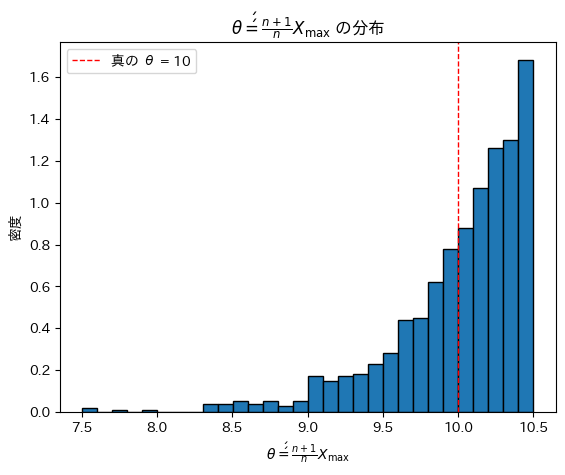
θ’’は、元となるXmaxの分布を右にずらした形状を取っています。期待値は真のθに一致しているようです。
次にサンプルサイズnを変化させて不偏推定量θ’’がどうなるのか確認をします。
# 2017 Q2(3) 2024.10.31
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
theta_true = 10 # 真の θ の値
max_n = 100 # 最大サンプルサイズ
num_trials_per_n = 100 # 各サンプルサイズでの試行回数
# 各サンプルサイズにおける θ'' の平均を記録
theta_double_prime_means = []
# サンプルサイズ n を 1 から max_n まで増やしながらシミュレーション
for n in range(1, max_n + 1):
theta_double_prime_estimates = []
for _ in range(num_trials_per_n):
# 一様分布 U(0, theta_true) から n 個のサンプルを生成
samples = np.random.uniform(0, theta_true, n)
# サンプルの最大値 X_max を計算し、それを用いて θ'' を計算
theta_double_prime = (n + 1) / n * np.max(samples)
theta_double_prime_estimates.append(theta_double_prime)
# 各 n に対する θ'' の平均を保存
theta_double_prime_means.append(np.mean(theta_double_prime_estimates))
# グラフ描画
plt.plot(range(1, max_n + 1), theta_double_prime_means, label=r'$\mathbb{E}[\theta\'\']$')
plt.axhline(theta_true, color='red', linestyle='dashed', linewidth=1, label=f"真の θ = {theta_true}")
plt.xlabel(r'サンプルサイズ $n$')
plt.ylabel(r'推定量 $\theta\'\' = \frac{n + 1}{n} X_{\max}$ の平均')
plt.title(r'サンプルサイズ $n$ と $\theta\'\' = \frac{n + 1}{n} X_{\max}$ の関係')
plt.legend()
plt.show()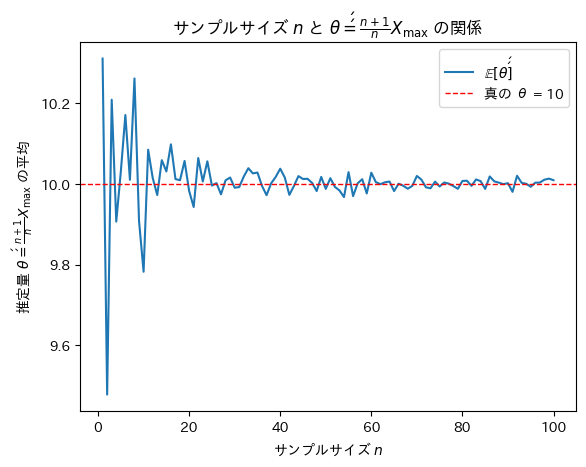
サンプルサイズnが増加するにつれて不偏推定量θ’’は真のθに近づくことが確認できました。
2017 Q2(2)
標本平均の2倍が一様分布の上限値の不偏推定量であることの証明をしました。

コード
θ=10,n=20としてシミュレーションを行い、θ’の分布を見てみます。
# 2017 Q2(2) 2024.10.30
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションのパラメータ
theta_true = 10 # 真の θ の値
n = 20 # 1試行あたりのサンプル数
num_trials = 1000 # シミュレーションの試行回数
# シミュレーションを実行
theta_prime_estimates = []
for _ in range(num_trials):
# 一様分布 U(0, theta_true) から n 個のサンプルを生成
samples = np.random.uniform(0, theta_true, n)
# サンプル平均 X̄ を計算し、それを用いて θ' を計算
theta_prime = 2 * np.mean(samples)
theta_prime_estimates.append(theta_prime)
# θ' の分布をヒストグラムで表示
plt.hist(theta_prime_estimates, bins=30, edgecolor='black', density=True)
plt.axvline(theta_true, color='red', linestyle='dashed', linewidth=1, label=f"真の θ = {theta_true}")
plt.xlabel(r'$\theta\' = 2\bar{X}$')
plt.ylabel('密度')
plt.title(r'$\theta\' = 2\bar{X}$ の分布')
plt.legend()
plt.show()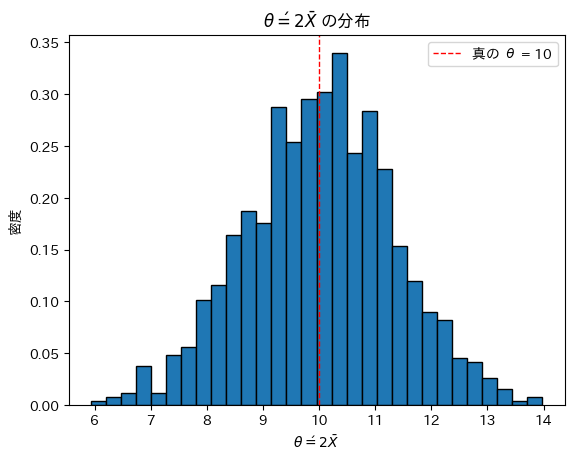
θ’は真のθを中心に左右対称にバラついています。θ’は不偏であるように見えます。
次にサンプルサイズnを変化させて不偏推定量θ’がどうなるのか確認をします。
# 2017 Q2(2) 2024.10.30
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
theta_true = 10 # 真の θ の値
max_n = 100 # 最大サンプルサイズ
num_trials_per_n = 100 # 各サンプルサイズでの試行回数
# 各サンプルサイズにおける θ' の平均を記録
theta_prime_means = []
# サンプルサイズ n を 1 から max_n まで増やしながらシミュレーション
for n in range(1, max_n + 1):
theta_prime_estimates = []
for _ in range(num_trials_per_n):
# 一様分布 U(0, theta_true) から n 個のサンプルを生成
samples = np.random.uniform(0, theta_true, n)
# サンプル平均 X̄ を計算し、それを用いて θ' を計算
theta_prime = 2 * np.mean(samples)
theta_prime_estimates.append(theta_prime)
# 各 n に対する θ' の平均を保存
theta_prime_means.append(np.mean(theta_prime_estimates))
# グラフ描画
plt.plot(range(1, max_n + 1), theta_prime_means, label=r'$\mathbb{E}[\theta\']$')
plt.axhline(theta_true, color='red', linestyle='dashed', linewidth=1, label=f"真の θ = {theta_true}")
plt.xlabel(r'サンプルサイズ $n$')
plt.ylabel(r'推定量 $\theta\' = 2 \bar{X}$ の平均')
plt.title(r'サンプルサイズ $n$ と $\theta\' = 2 \bar{X}$ の関係')
plt.legend()
plt.show()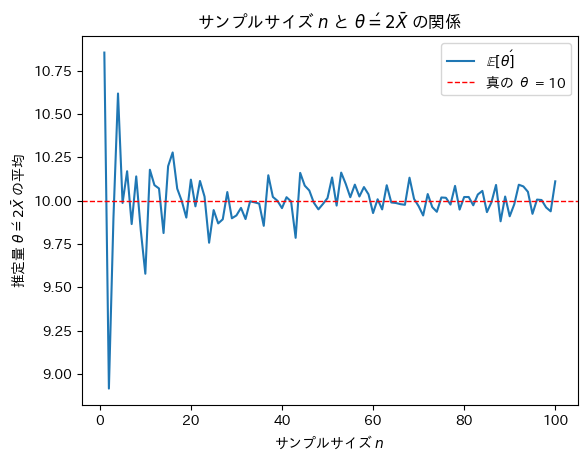
サンプルサイズnが増加するにつれて不偏推定量θ’は真のθに近づくことが確認できました。
2017 Q2(1)
一様分布の上限の最尤推定量を求めました。

コード
θ=10,n=20としてシミュレーションを行い、 の分布を見てみます。
の分布を見てみます。
# 2017 Q2(1) 2024.10.29
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションのパラメータ
theta_true = 10 # 真の θ の値
n = 20 # 1試行あたりのサンプル数
num_trials = 1000 # シミュレーションの試行回数
# シミュレーションを実行
theta_estimates = []
for _ in range(num_trials):
# 一様分布 U(0, theta_true) から n 個のサンプルを生成
samples = np.random.uniform(0, theta_true, n)
# サンプルの最大値を推定値 θ_hat として記録
theta_hat = np.max(samples)
theta_estimates.append(theta_hat)
# 推定値の分布をヒストグラムで表示
plt.hist(theta_estimates, bins=30, edgecolor='black', density=True)
plt.axvline(theta_true, color='red', linestyle='dashed', linewidth=1, label=f"真の θ = {theta_true}")
plt.xlabel(r'$\hat{\theta}$')
plt.ylabel('密度')
plt.title(r'$\hat{\theta} = X_{\max}$ の分布')
plt.legend()
plt.show()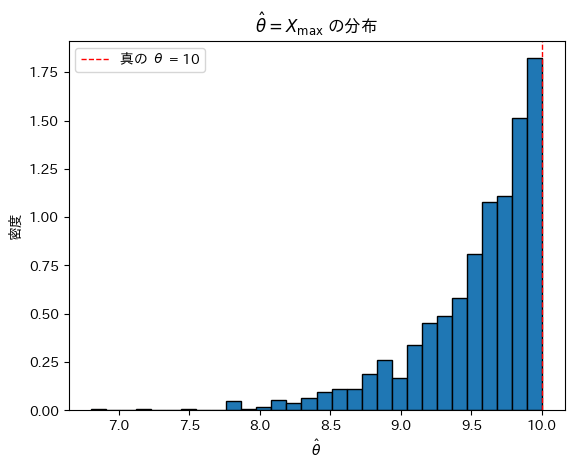
は真のθより大きくならないため、結果としてθよりやや小さな値を取っているように見えます。
次にサンプルサイズnを変化させて最尤推定量がどうなるのか確認をします。
# 2017 Q2(1) 2024.10.29
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
theta_true = 10 # 真の θ の値
max_n = 100 # 最大サンプルサイズ
num_trials_per_n = 100 # 各サンプルサイズでの試行回数
# 各サンプルサイズにおける θ^ の平均を記録
theta_hat_means = []
# サンプルサイズ n を 1 から max_n まで増やしながらシミュレーション
for n in range(1, max_n + 1):
theta_estimates = []
for _ in range(num_trials_per_n):
# 一様分布 U(0, theta_true) から n 個のサンプルを生成
samples = np.random.uniform(0, theta_true, n)
# サンプルの最大値を推定値 θ_hat として記録
theta_hat = np.max(samples)
theta_estimates.append(theta_hat)
# 各 n に対する θ^ の平均を保存
theta_hat_means.append(np.mean(theta_estimates))
# グラフ描画
plt.plot(range(1, max_n + 1), theta_hat_means, label=r'$\mathbb{E}[\hat{\theta}]$')
plt.axhline(theta_true, color='red', linestyle='dashed', linewidth=1, label=f"真の θ = {theta_true}")
plt.xlabel(r'サンプルサイズ $n$')
plt.ylabel(r'推定量 $\hat{\theta}$ の平均')
plt.title(r'サンプルサイズ $n$ と $\hat{\theta}$ の関係')
plt.legend()
plt.show()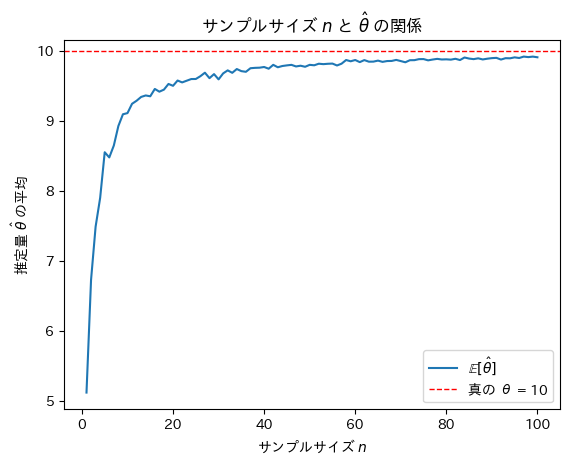
サンプルサイズnが増加するにつれて最尤推定量は真のθに近づくことが確認できました。
2017 Q1(5)
正規分布の分散の最尤推定量を母平均が既知の場合と未知の場合でそれぞれ求めましまた。

コード
サンプルサイズnを50に固定し尤度関数を可視化します。また最尤推定量  と
と をプロットしてみます。
をプロットしてみます。
# 2017 Q1(5) 2024.10.28
# 最尤推定量 (T^2, S^2) の計算と尤度関数の可視化
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# シミュレーションパラメータの設定
mu = 5.0 # 母平均(既知)
sigma = 2.0 # 母標準偏差(√母分散)
selected_sample_size = 50 # 固定サンプルサイズ
true_variance = sigma**2 # 母分散
# 正規分布からのサンプル生成(サンプルサイズは selected_sample_size で固定)
sample = np.random.normal(mu, sigma, selected_sample_size) # 固定サンプル生成
# 最尤推定量の計算
T2 = np.sum((sample - mu) ** 2) / selected_sample_size # 最尤推定量 T^2 の計算 (μが既知)
sample_mean = np.mean(sample)
S2 = np.sum((sample - sample_mean) ** 2) / (selected_sample_size - 1) # 最尤推定量 S^2 の計算 (μが未知)
# 尤度関数のプロットのためのパラメータ設定
sigma_squared_trial_values = np.linspace(0.1, 5.0, 100) # σ^2 の値を試行的に設定
likelihoods = [] # 尤度関数の値を保存するリスト
# 尤度関数の計算(固定サンプルに基づく)
for sigma_squared_trial in sigma_squared_trial_values:
likelihood = np.prod(norm.pdf(sample, loc=mu, scale=np.sqrt(sigma_squared_trial))) # 尤度関数の値を計算
likelihoods.append(likelihood)
# グラフの作成
plt.figure(figsize=(10, 6))
plt.plot(sigma_squared_trial_values, likelihoods, label='尤度関数', color='blue')
plt.axvline(x=T2, color='green', linestyle='--', label='$T^2$ (最尤推定量, μが既知)', linewidth=2)
plt.axvline(x=S2, color='orange', linestyle='--', label='$S^2$ (最尤推定量, μが未知)', linewidth=2)
plt.axvline(x=true_variance, color='red', linestyle='-.', label='母分散 $\\sigma^2$', linewidth=2)
plt.title(f'サンプルサイズ {selected_sample_size} における尤度関数と推定量の比較')
plt.xlabel('$\sigma^2$ の試行値')
plt.ylabel('尤度')
plt.legend()
plt.grid(True)
# グラフの表示
plt.tight_layout()
plt.show()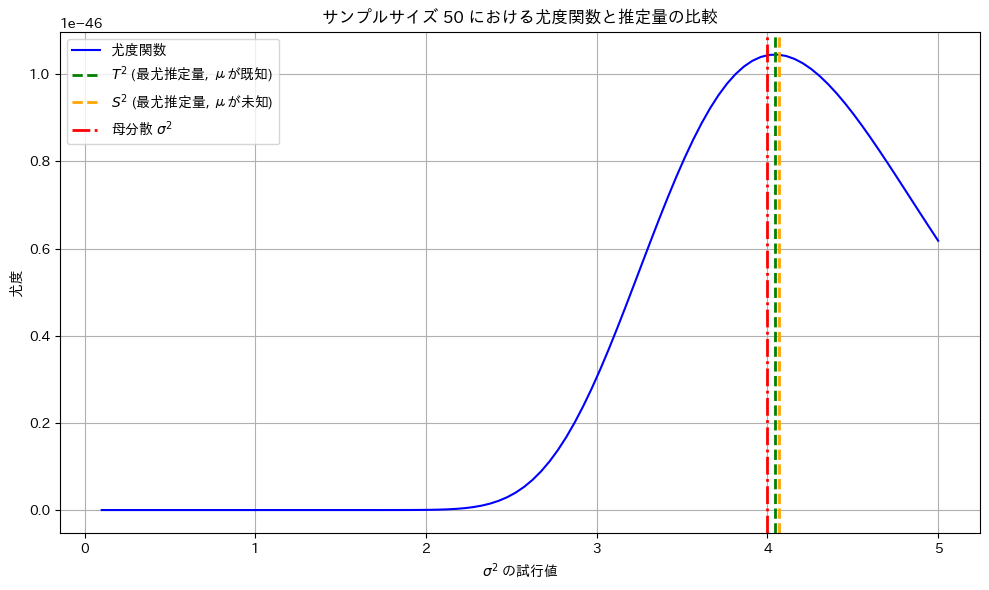
最尤推定量  と
と は尤度が最大となる
は尤度が最大となる の値を取っています。
の値を取っています。
もう一度実行してみます。
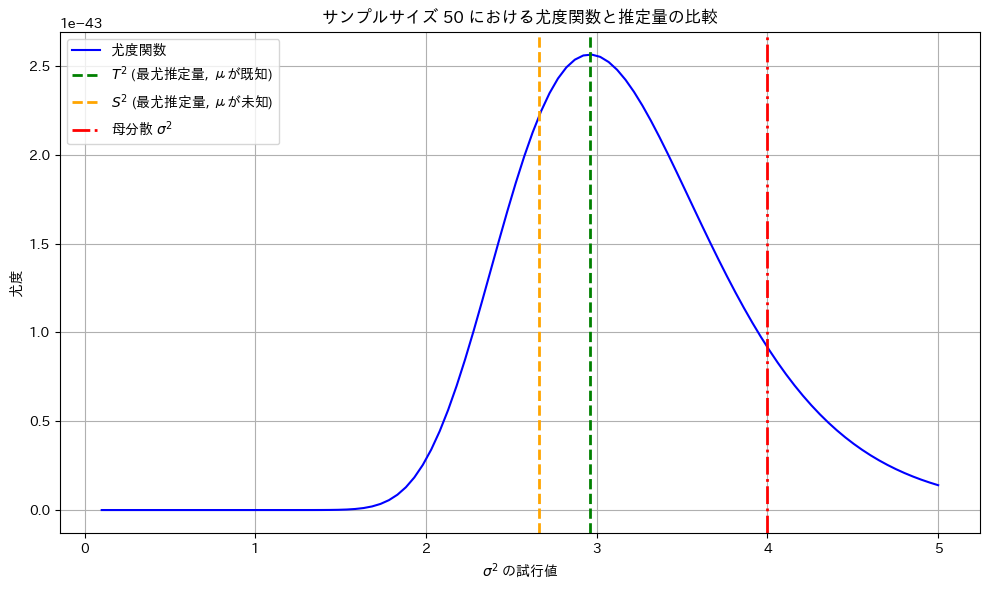
サンプルによっては最尤推定量とはから乖離する場合もあります。
次に、サンプルサイズを大きくすることで母分散に近づくことを確認します。
# 2017 Q1(5) 2024.10.28
from scipy.stats import norm
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションパラメータの設定
mu = 5.0 # 母平均(既知)
sigma = 2.0 # 母標準偏差(√母分散)
true_variance = sigma**2 # 母分散
sample_sizes = range(50, 10050, 50) # サンプルサイズを設定
# シミュレーション結果を保存するリスト
T2_estimates = [] # μが既知の場合の推定量 T^2
S2_estimates = [] # μが未知の場合の推定量 S^2
# 各サンプルサイズでのシミュレーションの実行
for n in sample_sizes:
# 正規分布からサンプルを抽出
sample = np.random.normal(mu, sigma, n)
# μが既知の場合の最尤推定量 T^2
T2 = np.sum((sample - mu) ** 2) / n
# μが未知の場合の最尤推定量 S^2
sample_mean = np.mean(sample)
S2 = np.sum((sample - sample_mean) ** 2) / (n - 1)
# 推定量をリストに保存
T2_estimates.append(T2)
S2_estimates.append(S2)
# グラフの作成(理論値を追加)
plt.figure(figsize=(12, 8))
# μが既知の場合のプロット (緑)
plt.plot(sample_sizes, T2_estimates, marker='o', color='green', label='$T^2$ (μが既知の場合)', linestyle='--')
# μが未知の場合のプロット (オレンジ)
plt.plot(sample_sizes, S2_estimates, marker='x', color='orange', label='$S^2$ (μが未知の場合)', linestyle='--')
# 理論値の線を追加 (赤)
plt.axhline(y=true_variance, color='red', linestyle='-.', label='理論値: $\sigma^2$', linewidth=2)
# グラフの設定
plt.title('最尤推定量 $T^2$ と $S^2$ のサンプルサイズごとの結果')
plt.xlabel('サンプルサイズ $n$')
plt.ylabel('推定量')
plt.legend()
plt.grid(True)
# グラフの表示
plt.tight_layout()
plt.show()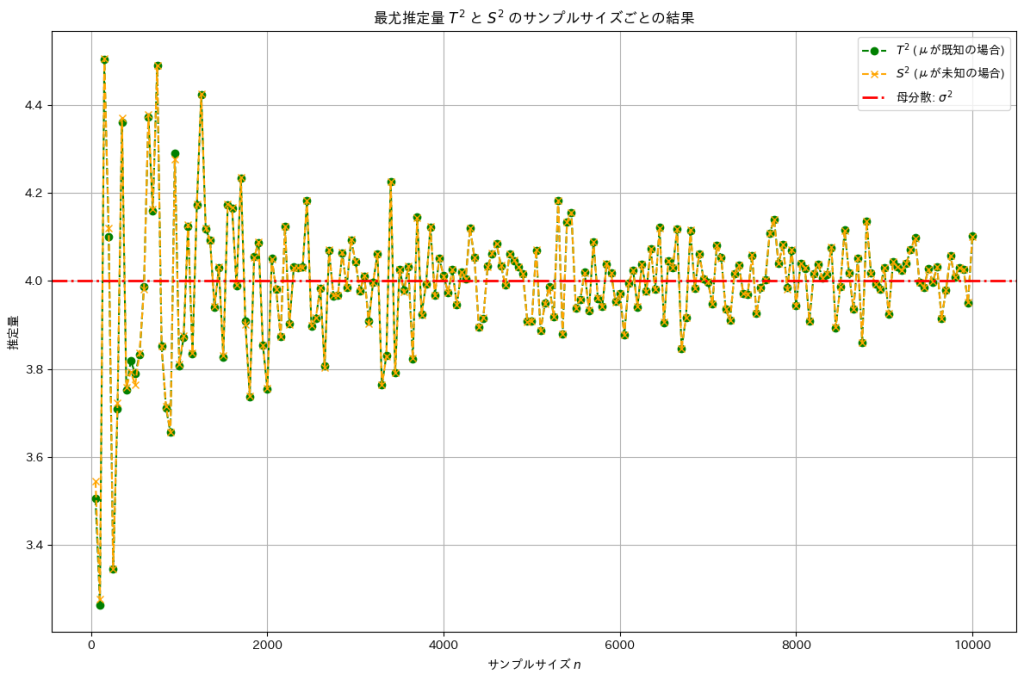
サンプルサイズを大きくすることで最尤推定量とは母分散に近づきました。
2017 Q1(4)
サンプル数が十分に大きい時のサンプル平均の歪度と尖度がどのようになるか考察した。

コード
Xの標本平均の歪度と尖度(過剰尖度)はサンプルサイズnが十分大きいときにどう変化するのか確認します。
# 2017 Q1(4) 2024.10.27
from scipy.stats import skew, kurtosis, gamma
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションパラメータの設定
#np.random.seed(42) # 再現性のためのシード
num_simulations = 300000 # シミュレーションの繰り返し回数
sample_sizes = range(10, 1100, 50) # サンプルサイズを広げて設定
# 歪度と尖度を持つ母集団分布としてガンマ分布を使用(shape=2で正の歪度と尖度を持つ)
shape_param = 2.0 # ガンマ分布のshapeパラメータ
scale_param = 2.0 # ガンマ分布のscaleパラメータ
population_dist = gamma(a=shape_param, scale=scale_param)
# シミュレーション結果を保存するリスト
sample_mean_skewness = []
sample_mean_kurtosis = []
# 各サンプルサイズでのシミュレーションの実行
for n in sample_sizes:
skew_values = []
kurt_values = []
# シミュレーションを繰り返し
for _ in range(num_simulations):
sample = population_dist.rvs(size=n) # サンプルを抽出
sample_mean = np.mean(sample) # 標本平均
# 標本平均をリストに保存
skew_values.append(sample_mean)
kurt_values.append(sample_mean)
# 標本平均の歪度と尖度を計算
skewness_of_sample_mean = skew(skew_values)
kurtosis_of_sample_mean = kurtosis(kurt_values, fisher=False) - 3 # 過剰尖度に変換
# 結果を保存
sample_mean_skewness.append(skewness_of_sample_mean)
sample_mean_kurtosis.append(kurtosis_of_sample_mean)
# グラフの作成
plt.figure(figsize=(12, 6))
# 歪度のプロット
plt.subplot(1, 2, 1)
plt.plot(sample_sizes, sample_mean_skewness, marker='o', label='歪度')
plt.axhline(y=0, color='r', linestyle='--', label='理論値: 0')
plt.title('サンプルサイズと歪度の関係')
plt.xlabel('サンプルサイズ $n$')
plt.ylabel('歪度 ($\\bar{X}$)')
plt.legend()
plt.grid(True)
# 尖度のプロット
plt.subplot(1, 2, 2)
plt.plot(sample_sizes, sample_mean_kurtosis, marker='o', label='尖度(過剰尖度)')
plt.axhline(y=0, color='r', linestyle='--', label='理論値: 0')
plt.title('サンプルサイズと尖度の関係')
plt.xlabel('サンプルサイズ $n$')
plt.ylabel('尖度 ($\\bar{X}$)')
plt.legend()
plt.grid(True)
# グラフの表示
plt.tight_layout()
plt.show()
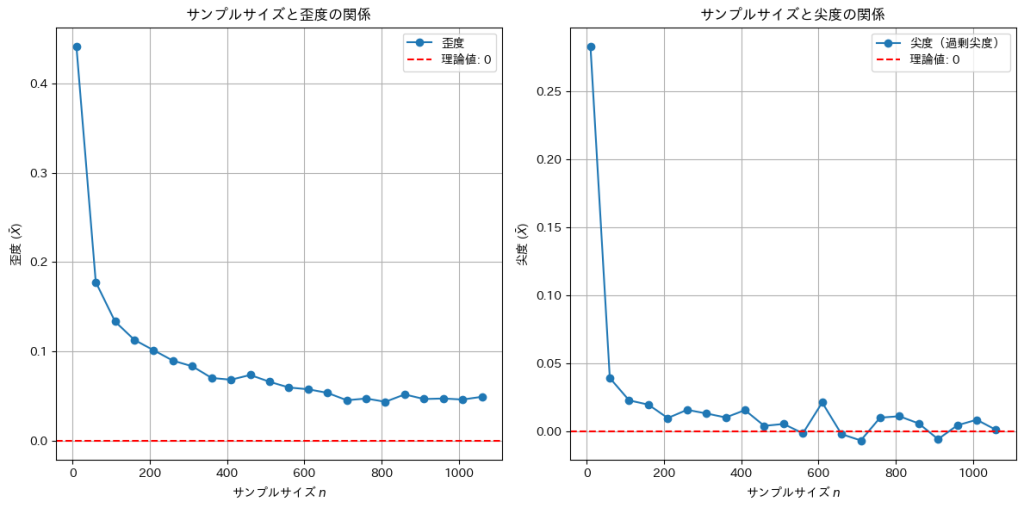
Xの標本平均の尖度(過剰尖度)はサンプルサイズnが大きくなると0に近づくことが確認できました。しかし歪度は0に近づくスピードは遅いです。Xが従うガンマ分布は元々歪度を持つ非対称な分布なので、そのようになります。サンプルサイズnを10,000まで大きくしてみます。
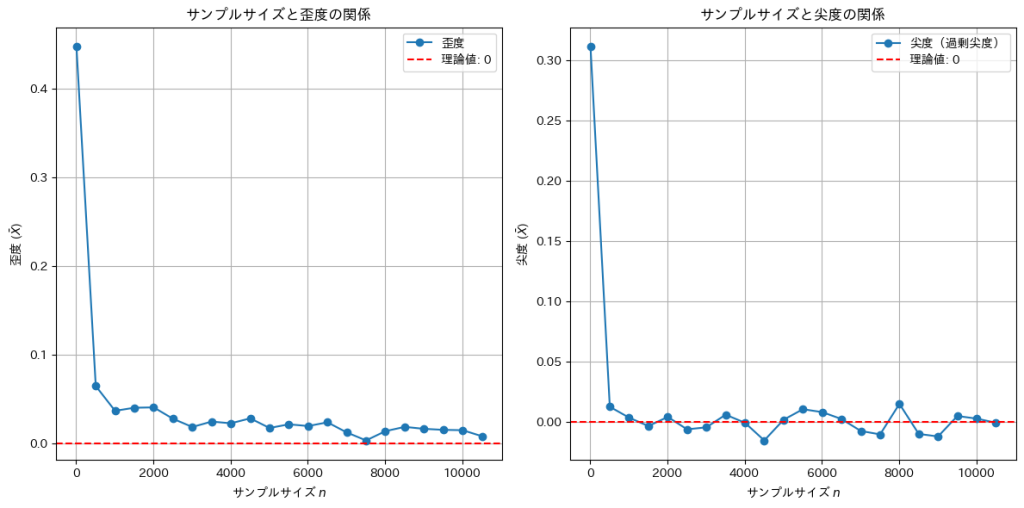
nが十分に大きくなったので歪度も0に近づきました。
次に、サンプルサイズnに伴う標本平均の分布が正規分布に近づく様子を確認します。
# 2017 Q1(4) 2024.10.27
import seaborn as sns
from scipy.stats import norm
# サンプルサイズの設定
selected_sample_sizes = [5, 20, 100, 200] # 表示するサンプルサイズの選択
num_simulations = 10000 # シミュレーションの繰り返し回数
# グラフの作成
plt.figure(figsize=(14, 10))
# 各サンプルサイズでのシミュレーションとヒストグラムの描画
for idx, n in enumerate(selected_sample_sizes):
sample_means = []
# シミュレーションの実行
for _ in range(num_simulations):
sample = population_dist.rvs(size=n) # サンプルを抽出
sample_mean = np.mean(sample) # 標本平均を計算
sample_means.append(sample_mean)
# ヒストグラムのプロット
plt.subplot(2, 2, idx + 1)
sns.histplot(sample_means, bins=30, kde=True, stat="density", color='blue', label='標本平均の分布')
# 正規分布のプロット
mean_of_means = np.mean(sample_means)
std_of_means = np.std(sample_means)
x = np.linspace(min(sample_means), max(sample_means), 100)
plt.plot(x, norm.pdf(x, mean_of_means, std_of_means), 'r--', label='正規分布')
# グラフの設定
plt.title(f'サンプルサイズ {n} の標本平均の分布')
plt.xlabel('標本平均')
plt.ylabel('密度')
plt.legend()
plt.grid(True)
# グラフの表示
plt.tight_layout()
plt.show()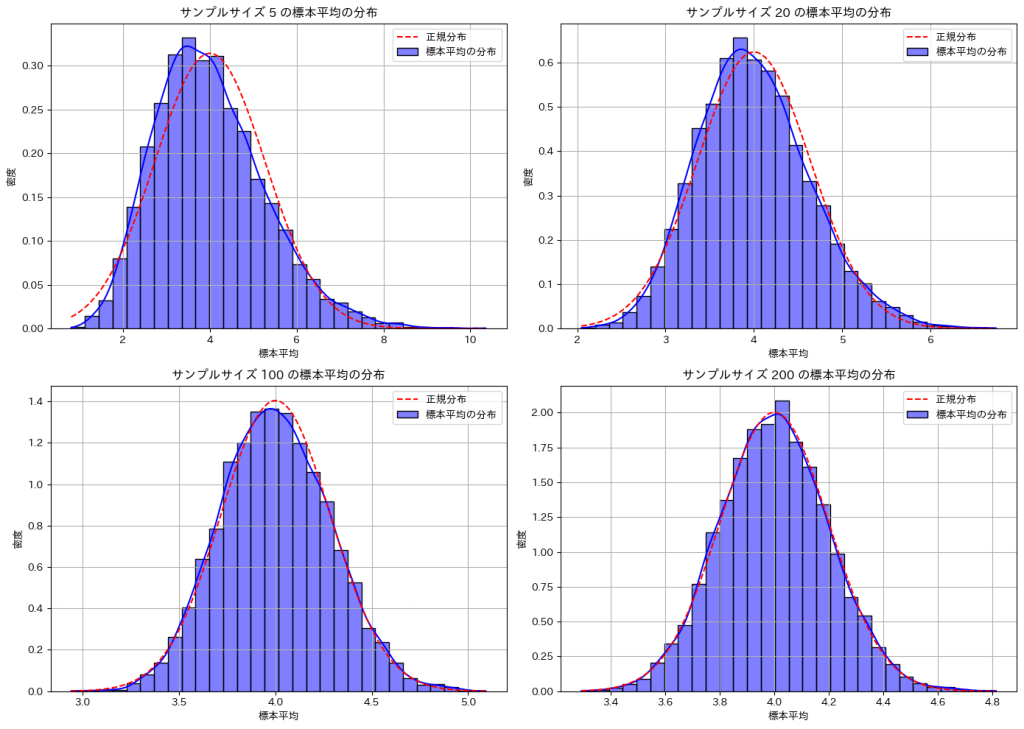
サンプルサイズnが大きくなるほど標本平均の分布は正規分布に近づくことが確認できました。
2017 Q1(3)
この前と同じ問ですが、解き方が間違っていたので、再チャレンジです。
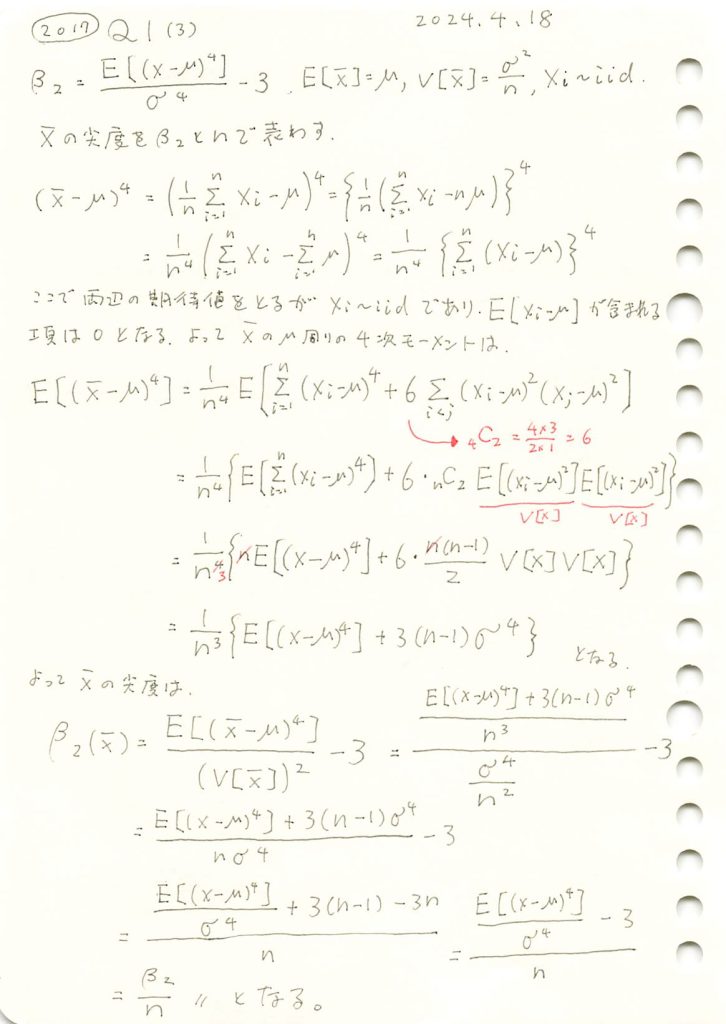
コード
Xの標本平均の尖度(過剰尖度)が になるか確認するためにシミュレーションを行います。母集団分布はガンマ分布とします。比較のためシミュレーション回数は前問(歪度)と同じ回数とする。
になるか確認するためにシミュレーションを行います。母集団分布はガンマ分布とします。比較のためシミュレーション回数は前問(歪度)と同じ回数とする。
# 2017 Q1(3) 2024.10.26
from scipy.stats import kurtosis, gamma
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションパラメータの設定
num_simulations = 30000 # シミュレーションの繰り返し回数
sample_sizes = range(10, 110, 10) # サンプルサイズの設定
# 尖度を持つ母集団分布としてガンマ分布を使用(shape=2で正の尖度を持つ)
shape_param = 2.0 # ガンマ分布のshapeパラメータ
scale_param = 2.0 # ガンマ分布のscaleパラメータ
population_dist = gamma(a=shape_param, scale=scale_param)
# 理論的な過剰尖度(ガンマ分布の尖度の計算)
beta_2_theoretical = 6 / shape_param # ガンマ分布の過剰尖度
# シミュレーション結果を保存するリスト
sample_mean_excess_kurtosis = []
# 各サンプルサイズでのシミュレーションの実行
for n in sample_sizes:
kurt_values = []
# シミュレーションを繰り返し
for _ in range(num_simulations):
sample = population_dist.rvs(size=n) # サンプルを抽出
sample_mean = np.mean(sample) # 標本平均
kurt_values.append(sample_mean)
# 標本平均の尖度を計算し、過剰尖度に変換(-3)
kurtosis_of_sample_mean = kurtosis(kurt_values, fisher=False) - 3 # 尖度を計算し、過剰尖度に変換
sample_mean_excess_kurtosis.append(kurtosis_of_sample_mean)
# 理論値の計算
theoretical_excess_kurtosis = [beta_2_theoretical / n for n in sample_sizes]
# グラフの作成
plt.figure(figsize=(10, 6))
# シミュレーション結果のプロット
plt.plot(sample_sizes, sample_mean_excess_kurtosis, marker='o', label='シミュレーション結果 (過剰尖度)')
plt.plot(sample_sizes, theoretical_excess_kurtosis, color='r', linestyle='--', label='理論値: $\\frac{\\beta_2}{n}$')
plt.title('$\\bar{X}$ の過剰尖度のシミュレーションと理論値の比較')
plt.xlabel('サンプルサイズ $n$')
plt.ylabel('$\\bar{X}$ の過剰尖度')
plt.legend()
plt.grid(True)
# グラフの表示
plt.tight_layout()
plt.show()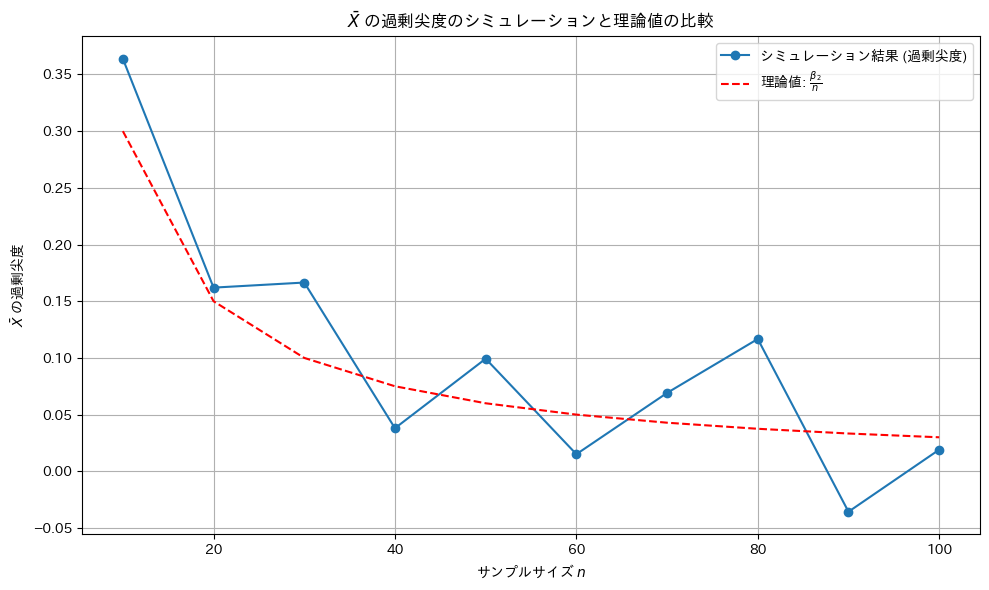
尖度は理論値に沿うものの、歪度(前問)より更に外れ値の影響を受けやすいため分散が大きい。
シミュレーション回数を10倍にしてみます。
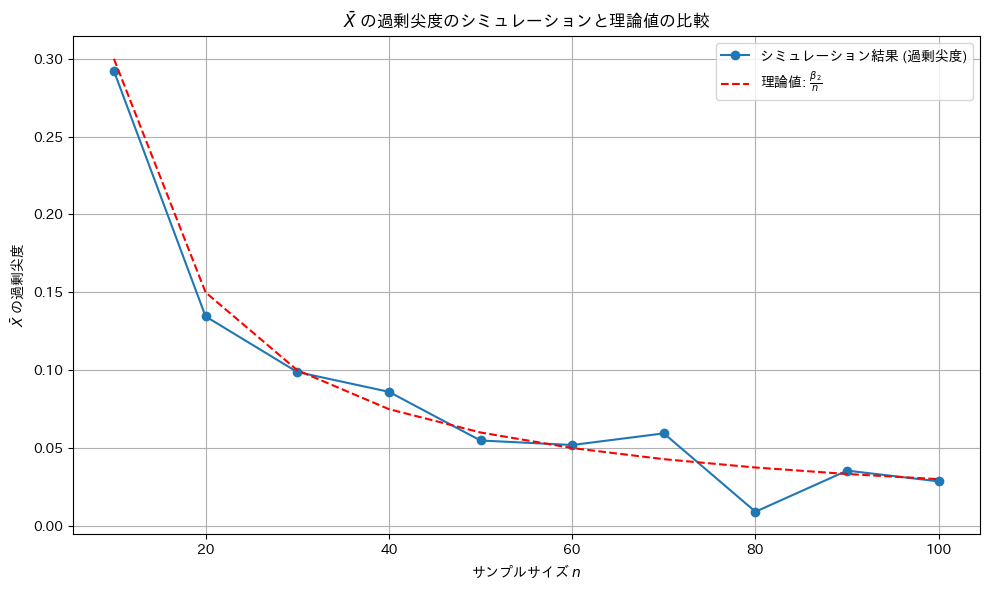
尖度は理論値に近づきました。
2017 Q1(2)
標本平均の歪度を求めました。

コード
Xの標本平均の歪度が になるか確認するためにシミュレーションを行います。母集団分布はガンマ分布とします。
になるか確認するためにシミュレーションを行います。母集団分布はガンマ分布とします。
from scipy.stats import skew, gamma
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションパラメータの設定
num_simulations = 30000 # シミュレーションの繰り返し回数
sample_sizes = range(10, 110, 10) # サンプルサイズの設定
# 歪度を持つ母集団分布としてガンマ分布を使用(shape=2で正の歪度を持つ)
shape_param = 2.0 # ガンマ分布のshapeパラメータ
scale_param = 2.0 # ガンマ分布のscaleパラメータ
population_dist = gamma(a=shape_param, scale=scale_param)
# 理論的な歪度(ガンマ分布の歪度の計算)
beta_1_theoretical = 2 / np.sqrt(shape_param) # ガンマ分布の理論的な歪度
# シミュレーション結果を保存するリスト
sample_mean_skewness = []
# 各サンプルサイズでのシミュレーションの実行
for n in sample_sizes:
skew_values = []
# シミュレーションを繰り返し
for _ in range(num_simulations):
sample = population_dist.rvs(size=n) # サンプルを抽出
sample_mean = np.mean(sample) # 標本平均
skew_values.append(sample_mean)
# 標本平均の歪度を計算
skewness_of_sample_mean = skew(skew_values)
sample_mean_skewness.append(skewness_of_sample_mean)
# 理論値の計算
theoretical_skewness = [beta_1_theoretical / np.sqrt(n) for n in sample_sizes]
# グラフの作成
plt.figure(figsize=(10, 6))
# シミュレーション結果のプロット
plt.plot(sample_sizes, sample_mean_skewness, marker='o', label='シミュレーション結果')
plt.plot(sample_sizes, theoretical_skewness, color='r', linestyle='--', label='理論値: $\\frac{\\beta_1}{\sqrt{n}}$')
plt.title('$\\bar{X}$ の歪度のシミュレーションと理論値の比較')
plt.xlabel('サンプルサイズ $n$')
plt.ylabel('$\\bar{X}$ の歪度')
plt.legend()
plt.grid(True)
# グラフの表示
plt.tight_layout()
plt.show()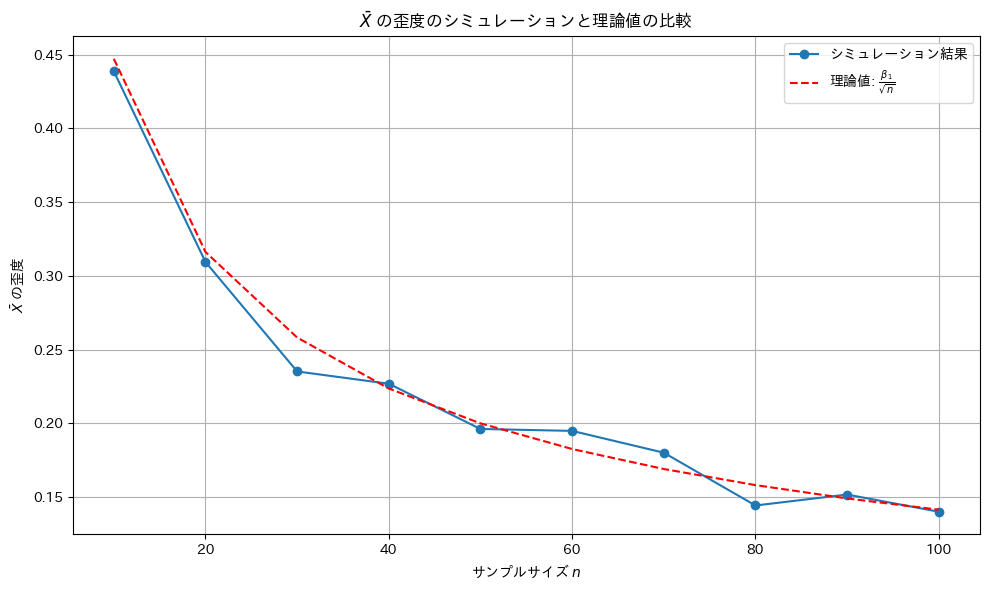
歪度は外れ値の影響を受けやすいものの概ね理論値と一致しました。
2017 Q1(1)
不偏分散が母分散の不偏推定量であることを示しました。
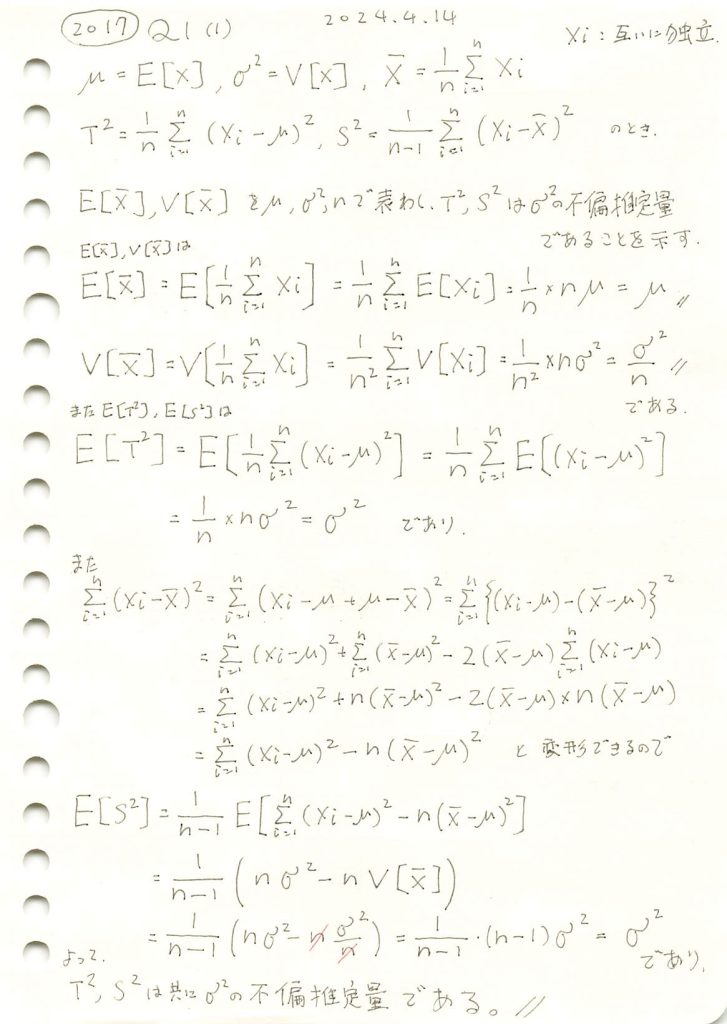
コード
サンプルサイズnを変化させて![E[\bar{X}]](https://statistics.blue/wp-content/ql-cache/quicklatex.com-4db35c1a5c217a383cfd1423c7c9efc0_l3.png "Rendered by QuickLaTeX.com") ,
,![V[\bar{X}]](https://statistics.blue/wp-content/ql-cache/quicklatex.com-8c5c0129b6b396e8b63388ee657fe4ef_l3.png "Rendered by QuickLaTeX.com") ,
,![E[T^2]](https://statistics.blue/wp-content/ql-cache/quicklatex.com-9cf91c6663a1962458fe251ccf26524d_l3.png "Rendered by QuickLaTeX.com") ,
,![E[S^2]](https://statistics.blue/wp-content/ql-cache/quicklatex.com-c3b45b1942cdefbc728efa1bf385b765_l3.png "Rendered by QuickLaTeX.com") をそれぞれシミュレーションして描画します。
をそれぞれシミュレーションして描画します。
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションパラメータの設定
mu = 5.0 # 母平均
sigma = 2.0 # 母標準偏差
num_simulations = 1000 # シミュレーションの繰り返し回数
# n の範囲を設定 (100 から 10000 まで 100 刻み)
n_values = range(100, 10100, 100)
# 各 n に対する統計量を保存するリスト
E_X_bar_list = []
V_X_bar_list = []
E_T2_list = []
E_S2_list = []
# 各 n に対するシミュレーションの実行
for n in n_values:
sample_means = []
T2_values = []
S2_values = []
# シミュレーションの実行
for _ in range(num_simulations):
sample = np.random.normal(mu, sigma, n)
sample_mean = np.mean(sample)
sample_means.append(sample_mean)
# T^2 計算 (母平均使用)
T2 = np.mean((sample - mu) ** 2)
T2_values.append(T2)
# S^2 計算 (標本平均使用)
S2 = np.var(sample, ddof=1)
S2_values.append(S2)
# 結果をリストに保存
E_X_bar_list.append(np.mean(sample_means))
V_X_bar_list.append(np.var(sample_means))
E_T2_list.append(np.mean(T2_values))
E_S2_list.append(np.mean(S2_values))
# グラフの作成(理論値を追加)
plt.figure(figsize=(14, 10))
# 理論値
theoretical_mean = mu # E[X_bar] の理論値
theoretical_variance = sigma**2 / np.array(n_values) # V[X_bar] の理論値
theoretical_variance_true = sigma**2 # 母分散
# E[X_bar] のプロット
plt.subplot(2, 2, 1)
plt.plot(n_values, E_X_bar_list, marker='o', label='シミュレーション')
plt.axhline(y=theoretical_mean, color='r', linestyle='--', label='理論値: $E[\overline{X}] = \mu$')
plt.title('$E[\overline{X}]$')
plt.xlabel('サンプルサイズ $n$')
plt.ylabel('$E[\overline{X}]$')
plt.legend()
# V[X_bar] のプロット
plt.subplot(2, 2, 2)
plt.plot(n_values, V_X_bar_list, marker='o', label='シミュレーション')
plt.plot(n_values, theoretical_variance, color='r', linestyle='--', label='理論値: $V[\overline{X}] = \\frac{\sigma^2}{n}$')
plt.title('$V[\overline{X}]$')
plt.xlabel('サンプルサイズ $n$')
plt.ylabel('$V[\overline{X}]$')
plt.legend()
# E[T^2] のプロット
plt.subplot(2, 2, 3)
plt.plot(n_values, E_T2_list, marker='o', label='シミュレーション')
plt.axhline(y=theoretical_variance_true, color='r', linestyle='--', label='理論値: $E[T^2] = \sigma^2$')
plt.title('$E[T^2]$')
plt.xlabel('サンプルサイズ $n$')
plt.ylabel('$E[T^2]$')
plt.legend()
# E[S^2] のプロット
plt.subplot(2, 2, 4)
plt.plot(n_values, E_S2_list, marker='o', label='シミュレーション')
plt.axhline(y=theoretical_variance_true, color='r', linestyle='--', label='理論値: $E[S^2] = \sigma^2$')
plt.title('$E[S^2]$')
plt.xlabel('サンプルサイズ $n$')
plt.ylabel('$E[S^2]$')
plt.legend()
# グラフの表示
plt.tight_layout()
plt.show()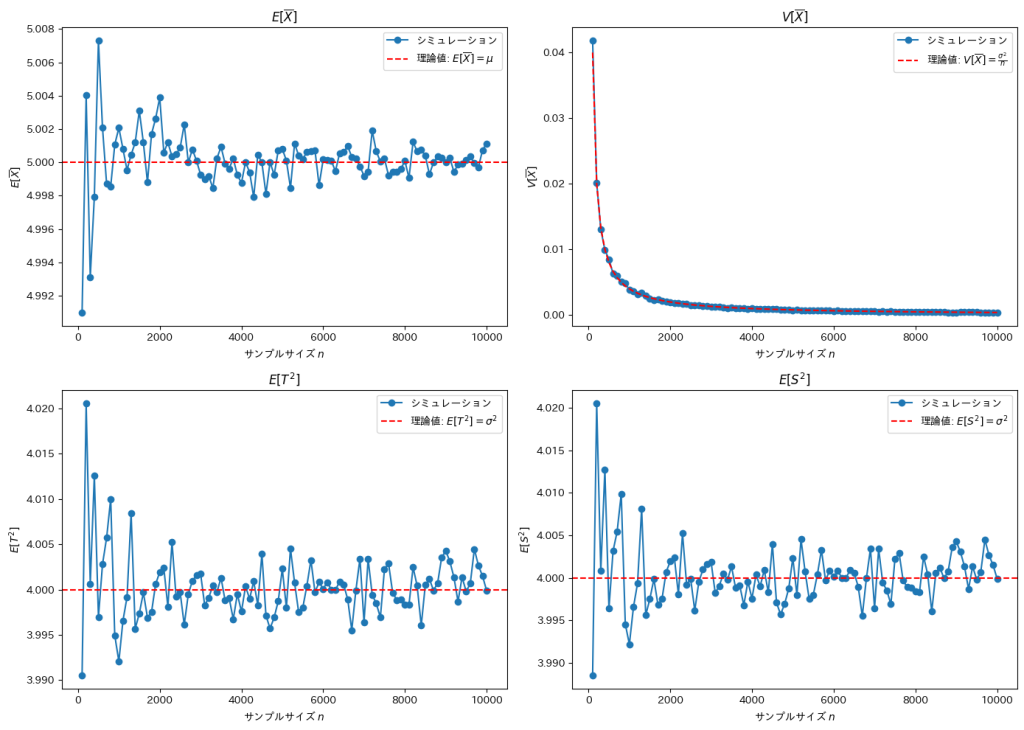
サンプルサイズnが増加するほど、各推定量は理論値に収束していく傾向に見えます。とは外れ値の影響を受けやすいため収束速度が緩やかです。