ホーム » 統計検定1級 2016年 統計数理 (ページ 2)
「統計検定1級 2016年 統計数理」カテゴリーアーカイブ
2016 Q3(2)
線形モデルの未知の母数βの最小二乗推定量を求め、それが不偏推定量であることを確認しました。
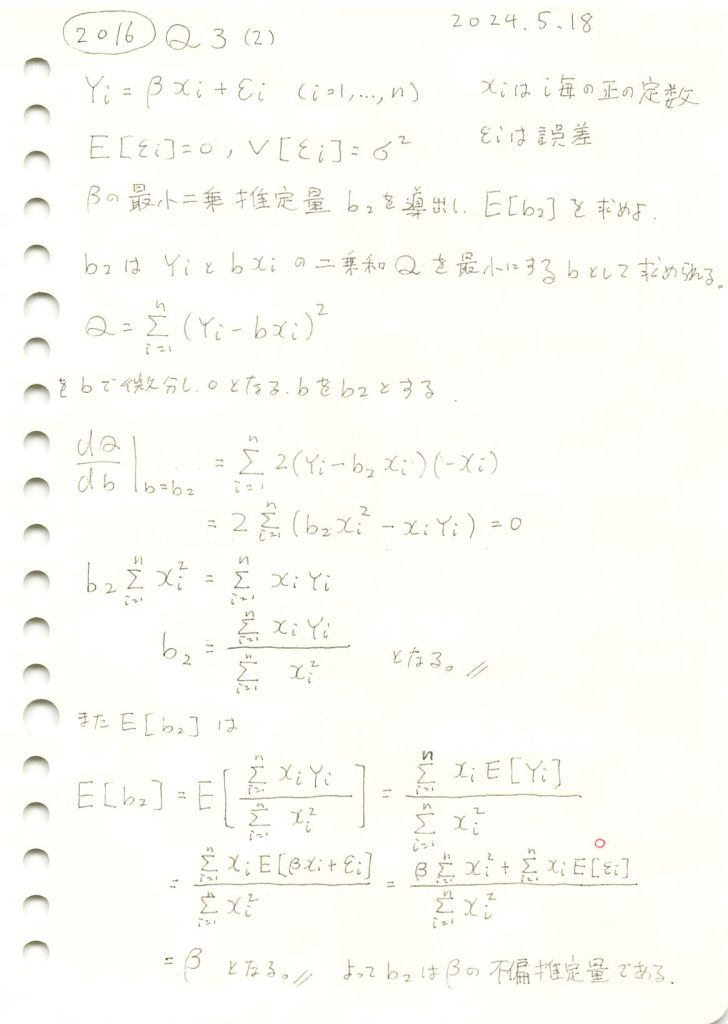
コード
乱数を発生させて線形モデルのパラメータβの推定量b0,b1,b2をそれぞれ計算し、観測データとともにプロットしてみます。推定された直線と真の直線がどのように異なるか視覚的に確認してみます。(b0,b1は前問参照)
# 2016 Q3(2) 2024.11.21
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
n = 10 # サンプルサイズ
true_beta = 2 # 真のβ
sigma = 5 # 誤差の標準偏差
# 1. xi を一様分布から生成
xi = np.random.uniform(1, 10, n)
# 2. εi を正規分布から生成
epsilon_i = np.random.normal(0, sigma, n)
# 3. Yi を計算
Yi = true_beta * xi + epsilon_i
# 4. 推定量 b0, b1 を計算
b0 = np.mean(Yi / xi)
b1 = np.sum(Yi) / np.sum(xi)
# 5. 最小二乗推定量 b2 を計算
b2 = np.sum(xi * Yi) / np.sum(xi**2)
# プロット
plt.figure(figsize=(10, 6))
plt.scatter(xi, Yi, label='観測データ ($Y_i$)', color='blue', marker='x') # マーカーを 'x' に変更
plt.plot(np.sort(xi), true_beta * np.sort(xi), label=f'真の直線 ($\\beta={true_beta}$)', color='green', linestyle='dashed')
plt.plot(np.sort(xi), b0 * np.sort(xi), label=f'推定直線 ($b_0={b0:.2f}$)', color='red')
plt.plot(np.sort(xi), b1 * np.sort(xi), label=f'推定直線 ($b_1={b1:.2f}$)', color='orange')
plt.plot(np.sort(xi), b2 * np.sort(xi), label=f'推定直線 ($b_2={b2:.2f}$)', color='purple')
plt.xlabel('$x_i$')
plt.ylabel('$Y_i$')
plt.title('線形モデルの推定')
plt.legend()
plt.grid(True)
plt.show()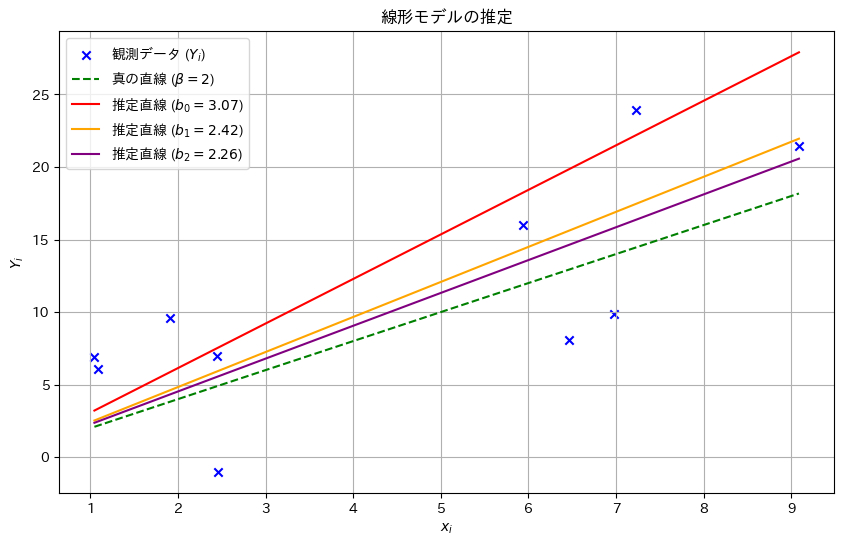
推定量b2,b1,b0の順に真のβに近い値を取りました。
次に、サンプル数nを変化させて、推定量b0,b1,b2がどのように変化するのか観察します
# 2016 Q3(2) 2024.11.21
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
sigma = 5 # 誤差の標準偏差
true_beta = 2 # 真のβ
sample_sizes = np.arange(5, 101, 5) # n を 5 から 100 まで 5 刻みで変化
simulations = 1000 # 各 n に対してのシミュレーション回数
b0_means = []
b1_means = []
b2_means = [] # b2 の期待値を記録
# 各サンプルサイズ n に対してシミュレーションを実行
for n in sample_sizes:
b0_samples = []
b1_samples = []
b2_samples = [] # b2 を記録
for _ in range(simulations):
xi = np.random.uniform(1, 10, n)
epsilon_i = np.random.normal(0, sigma, n)
Yi = true_beta * xi + epsilon_i
b0_samples.append(np.mean(Yi / xi))
b1_samples.append(np.sum(Yi) / np.sum(xi))
b2_samples.append(np.sum(xi * Yi) / np.sum(xi**2)) # b2 を計算
b0_means.append(np.mean(b0_samples))
b1_means.append(np.mean(b1_samples))
b2_means.append(np.mean(b2_samples)) # b2 の期待値を記録
# 結果をプロット
plt.figure(figsize=(10, 6))
plt.plot(sample_sizes, b0_means, label='$b_0$の期待値', marker='o', linestyle='dashed', color='red')
plt.plot(sample_sizes, b1_means, label='$b_1$の期待値', marker='x', linestyle='dashed', color='orange')
plt.plot(sample_sizes, b2_means, label='$b_2$の期待値', marker='s', linestyle='dashed', color='purple') # b2 を追加
plt.axhline(y=true_beta, color='green', linestyle='solid', label='真の値 $\\beta=2$')
plt.xlabel('サンプルサイズ $n$')
plt.ylabel('推定量の期待値')
plt.title('推定量 $b_0, b_1, b_2$ の期待値とサンプルサイズの関係')
plt.legend()
plt.grid(True)
plt.show()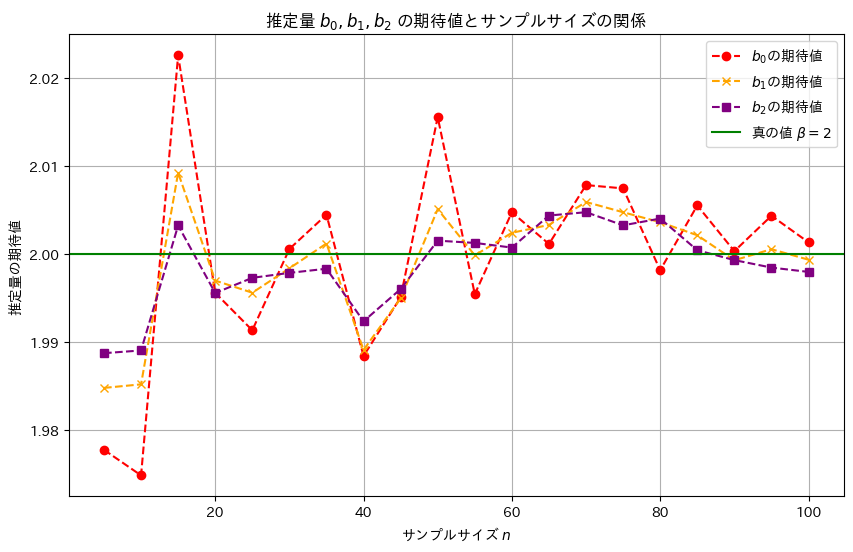
サンプルサイズnが大きくなるほど、推定量b0,b1,b2は真の値βに近づくことが確認できました。また、推定量b2,b1,b0の順に分散は小さく見え、b2,b1,b0の順により安定した推定量のようです。
次に、推定量b0,b1,b2の分布を確認してみます。それぞれのヒストグラムを重ねて表示してみます。
# 2016 Q3(2) 2024.11.21
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
n = 100 # サンプルサイズ
true_beta = 2 # 真のβ
sigma = 1 # 誤差の標準偏差
simulations = 10000 # シミュレーション回数
b0_samples = []
b1_samples = []
b2_samples = [] # b2 の分布を記録
# シミュレーションを実施
for _ in range(simulations):
xi = np.random.uniform(1, 10, n)
epsilon_i = np.random.normal(0, sigma, n)
Yi = true_beta * xi + epsilon_i
b0_samples.append(np.mean(Yi / xi))
b1_samples.append(np.sum(Yi) / np.sum(xi))
b2_samples.append(np.sum(xi * Yi) / np.sum(xi**2)) # b2 を計算
# b0, b1, b2 の分布を重ねてプロット
plt.figure(figsize=(10, 6))
plt.hist(b0_samples, bins=30, density=True, color='red', alpha=0.5, label='$b_0$')
plt.hist(b1_samples, bins=30, density=True, color='orange', alpha=0.5, label='$b_1$')
plt.hist(b2_samples, bins=30, density=True, color='purple', alpha=0.5, label='$b_2$') # b2 を追加
plt.axvline(x=true_beta, color='green', linestyle='dashed', label='真の値 $\\beta=2$')
plt.title('$b_0$, $b_1$, $b_2$ の分布 (n=100)')
plt.xlabel('推定値')
plt.ylabel('頻度')
plt.legend()
plt.grid(True)
plt.show()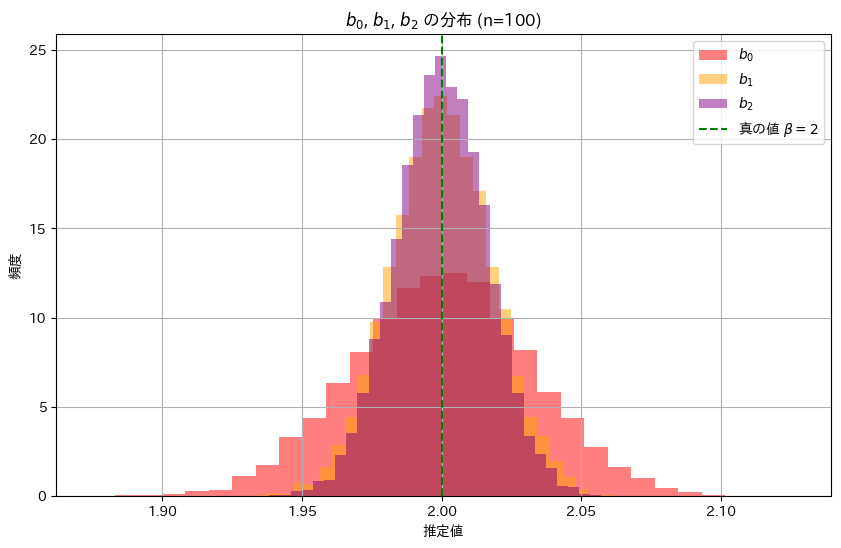
推定量b2,b1,b0の順に幅が狭く、分散が小さいことが確認できました。これにより推定量b2,b1,b0の順に安定した推定であることが分かりました。
2016 Q3(1)
線形モデルの未知の母数βの2つの推定量が不偏推定量であることを確認しました。

コード
乱数を発生させて線形モデルのパラメータβの推定量b0,b1をそれぞれ求め、観測データとともにプロットしてみます。推定された直線と真の直線がどのように異なるか視覚的に確認してみます。
# 2016 Q3(1) 2024.11.20
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
n = 50 # サンプルサイズ
true_beta = 2 # 真のβ
sigma = 5 # 誤差の標準偏差
# 1. xi を一様分布から生成
xi = np.random.uniform(1, 10, n)
# 2. εi を正規分布から生成
epsilon_i = np.random.normal(0, sigma, n)
# 3. Yi を計算
Yi = true_beta * xi + epsilon_i
# 4. 推定量 b0, b1 を計算
b0 = np.mean(Yi / xi)
b1 = np.sum(Yi) / np.sum(xi)
# プロット
plt.figure(figsize=(10, 6))
plt.scatter(xi, Yi, label='観測データ ($Y_i$)', color='blue', marker='x')
plt.plot(np.sort(xi), true_beta * np.sort(xi), label=f'真の直線 ($\\beta={true_beta}$)', color='green', linestyle='dashed')
plt.plot(np.sort(xi), b0 * np.sort(xi), label=f'推定直線 ($b_0={b0:.2f}$)', color='red')
plt.plot(np.sort(xi), b1 * np.sort(xi), label=f'推定直線 ($b_1={b1:.2f}$)', color='orange')
plt.xlabel('$x_i$')
plt.ylabel('$Y_i$')
plt.title('線形モデルの推定')
plt.legend()
plt.grid(True)
plt.show()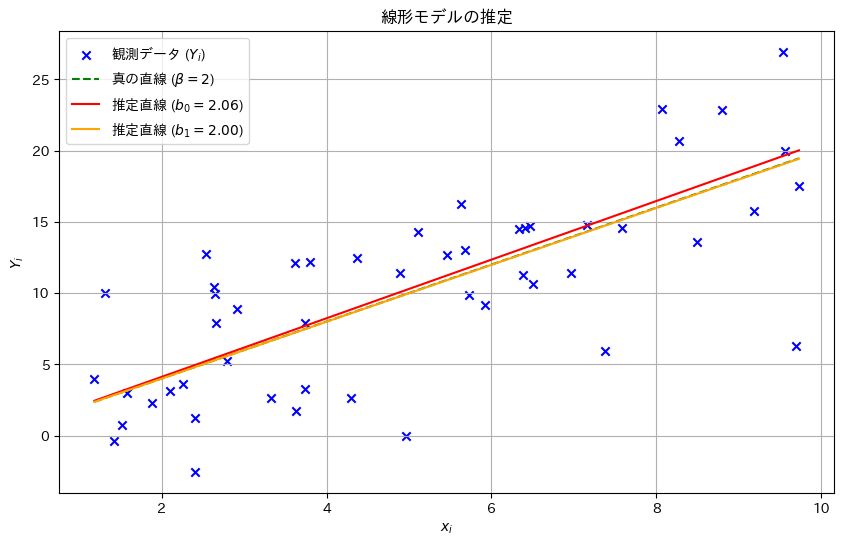
b0とb1は真のβに近い値を取り、直線は概ね一致しました。
次に、サンプル数nを変化させて、推定量b0,b1がどのように変化するのか観察します
# 2016 Q3(1) 2024.11.20
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
n = 50 # サンプルサイズ
true_beta = 2 # 真のβ
sigma = 5 # 誤差の標準偏差
# サンプルサイズを変化させて b0, b1 の期待値を検証
sample_sizes = np.arange(5, 101, 5) # n を 5 から 100 まで 5 刻みで変化
true_beta = 2 # 真のβ
simulations = 1000 # 各 n に対してのシミュレーション回数
b0_means = []
b1_means = []
# 各サンプルサイズ n に対してシミュレーションを実行
for n in sample_sizes:
b0_samples = []
b1_samples = []
for _ in range(simulations):
xi = np.random.uniform(1, 10, n)
epsilon_i = np.random.normal(0, sigma, n)
Yi = true_beta * xi + epsilon_i
b0_samples.append(np.mean(Yi / xi))
b1_samples.append(np.sum(Yi) / np.sum(xi))
b0_means.append(np.mean(b0_samples))
b1_means.append(np.mean(b1_samples))
# 結果をプロット
plt.figure(figsize=(10, 6))
plt.plot(sample_sizes, b0_means, label='$b_0$の期待値', marker='o', linestyle='dashed', color='red')
plt.plot(sample_sizes, b1_means, label='$b_1$の期待値', marker='x', linestyle='dashed', color='orange')
plt.axhline(y=true_beta, color='green', linestyle='solid', label='真の値 $\\beta=2$')
plt.xlabel('サンプルサイズ $n$')
plt.ylabel('推定量の期待値')
plt.title('推定量 $b_0, b_1$ の期待値とサンプルサイズの関係')
plt.legend()
plt.grid(True)
plt.show()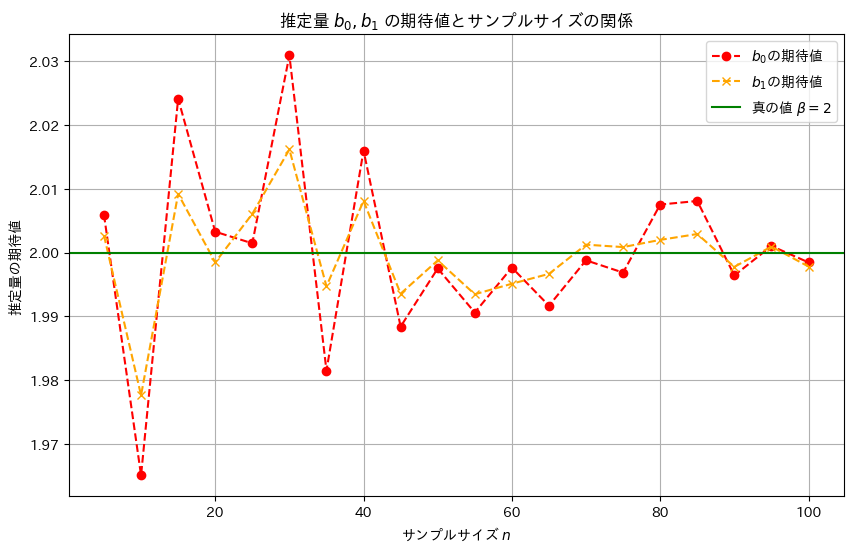
サンプルサイズnが大きくなるほど、推定量b0,b1は真の値βに近づくことが確認できました。また、b1の分散はb0の分散より小さく見え、b1はb0より安定した推定量のようです。
次に、推定量b0,b1の分布を確認してみます。それぞれのヒストグラムを重ねて表示してみます。
# 2016 Q3(1) 2024.11.20
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
n = 100 # サンプルサイズ
true_beta = 2 # 真のβ
sigma = 1 # 誤差の標準偏差
simulations = 10000 # シミュレーション回数
b0_samples = []
b1_samples = []
# シミュレーションを実施
for _ in range(simulations):
xi = np.random.uniform(1, 10, n)
epsilon_i = np.random.normal(0, sigma, n)
Yi = true_beta * xi + epsilon_i
b0_samples.append(np.mean(Yi / xi))
b1_samples.append(np.sum(Yi) / np.sum(xi))
# b0 と b1 の分布を重ねてプロット
plt.figure(figsize=(10, 6))
plt.hist(b0_samples, bins=30, density=True, color='red', alpha=0.5, label='$b_0$')
plt.hist(b1_samples, bins=30, density=True, color='orange', alpha=0.5, label='$b_1$')
plt.axvline(x=true_beta, color='green', linestyle='dashed', label='真の値 $\\beta=2$')
plt.title('$b_0$ と $b_1$ の分布 (n=100)')
plt.xlabel('推定値')
plt.ylabel('頻度')
plt.legend()
plt.grid(True)
plt.show()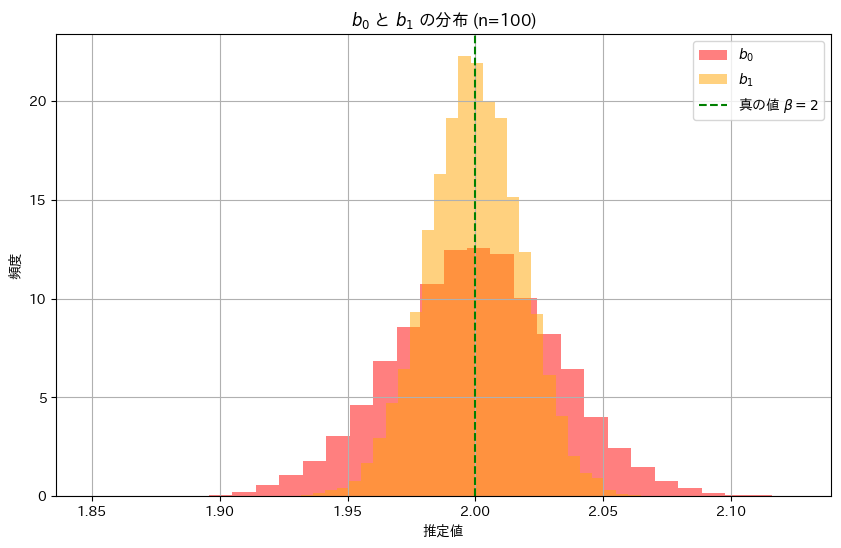
推定量b1の分布は、推定量b0の分布に比べて幅が狭く、b1の分散のほうがb0よりも小さく、安定した推定であることが分かりました。
2016 Q2(4)
指数分布の上側確率の推定量が、ガンマ分布に従う確率変数の式で表され、それが不偏推定量であることを示しました。

コード
 はnによらず
はnによらず に近づきます。nを1~20に変化させてシミュレーションして確認してみます。
に近づきます。nを1~20に変化させてシミュレーションして確認してみます。
# 2016 Q2(4) 2024.11.19
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
lambda_value = 2 # 固定されたλ
c = 1.0 # 定数c
n_values = range(1, 21) # nを1から20まで変化させる
sample_size = 1000 # シミュレーションのサンプルサイズ
simulated_expectations = [] # シミュレーション期待値を格納するリスト
theoretical_expectations = [] # 理論値を格納するリスト
# 修正版コード
for n in n_values:
# ガンマ分布のサンプルを生成 (Y ~ Gamma(n, λ))
Y_samples = np.random.gamma(shape=n, scale=1/lambda_value, size=sample_size)
# 条件付きで (1 - c/Y)^(n-1) を計算
values = np.where(Y_samples >= c, (1 - c / Y_samples)**(n - 1), 0)
# シミュレーション期待値を計算
simulated_expectations.append(np.mean(values))
# 理論値 e^(-λc) を計算
theoretical_expectations.append(np.exp(-lambda_value * c))
# グラフの描画
plt.figure(figsize=(10, 6))
plt.plot(n_values, theoretical_expectations, 'r-o', label='理論値: e^(-λc)', linewidth=2)
plt.plot(n_values, simulated_expectations, 'b-s', label='シミュレーション期待値', linewidth=2)
# グラフの設定
plt.title('理論値とシミュレーション期待値の比較 (n を変化)', fontsize=16)
plt.xlabel('n (形状パラメータ)', fontsize=14)
plt.ylabel('期待値', fontsize=14)
plt.legend(fontsize=12)
plt.grid(True)
# プロットの表示
plt.show()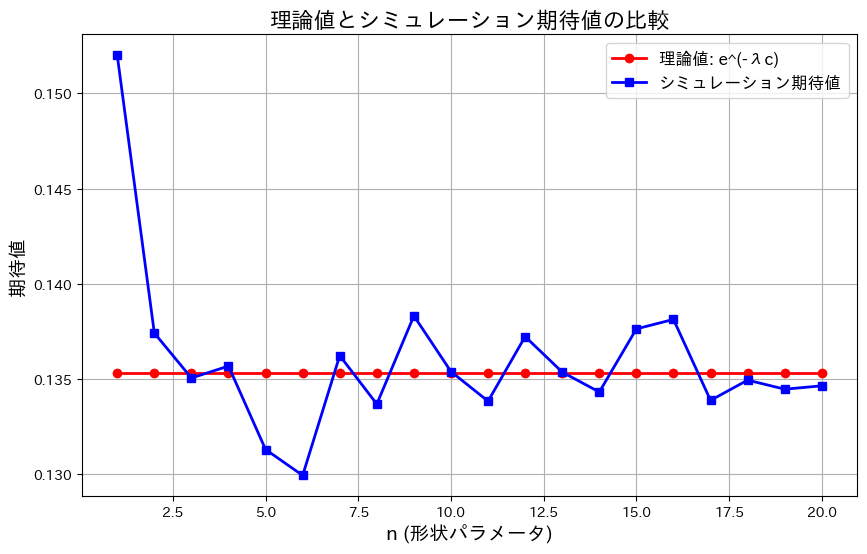
はnによらずに近づきました。グラフの縦軸の範囲が0.13~0.15と非常に狭いため、誤差が拡大して表示されているように見えます。実際の差異はごくわずかです。
2016 Q2(4)
指数分布の和がガンマ分布になることを示しました。

コード
指数分布に従う確率変数X1~Xnの和がガンマ分布に従うのをかを確かめるため、シミュレーションを行いました。この実験では、まずn=5の場合について確かめました。
# 2016 Q2(4) 2024.11.18
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
# パラメータ設定
lambda_value = 2 # 真のλ
n = 5 # 指数分布の和の数 (ガンマ分布の形状パラメータ)
sample_size = 10000 # シミュレーションのサンプルサイズ
# 1. 指数分布の和をシミュレーション
sum_of_exponentials = np.sum(np.random.exponential(scale=1/lambda_value, size=(sample_size, n)), axis=1)
# 2. ガンマ分布の理論値を計算
x = np.linspace(0, max(sum_of_exponentials), 1000)
gamma_pdf = gamma.pdf(x, a=n, scale=1/lambda_value)
# 3. ヒストグラムと理論的なガンマ分布をプロット
plt.figure(figsize=(10, 6))
plt.hist(sum_of_exponentials, bins=50, density=True, alpha=0.6, color='skyblue', label='シミュレーション (指数分布の和)')
plt.plot(x, gamma_pdf, 'r-', label='理論的なガンマ分布', linewidth=2)
# グラフの設定
plt.title('指数分布の和 (n=5) とガンマ分布の比較', fontsize=16)
plt.xlabel('値', fontsize=14)
plt.ylabel('密度', fontsize=14)
plt.legend(fontsize=12)
plt.grid(True)
# プロット表示
plt.show()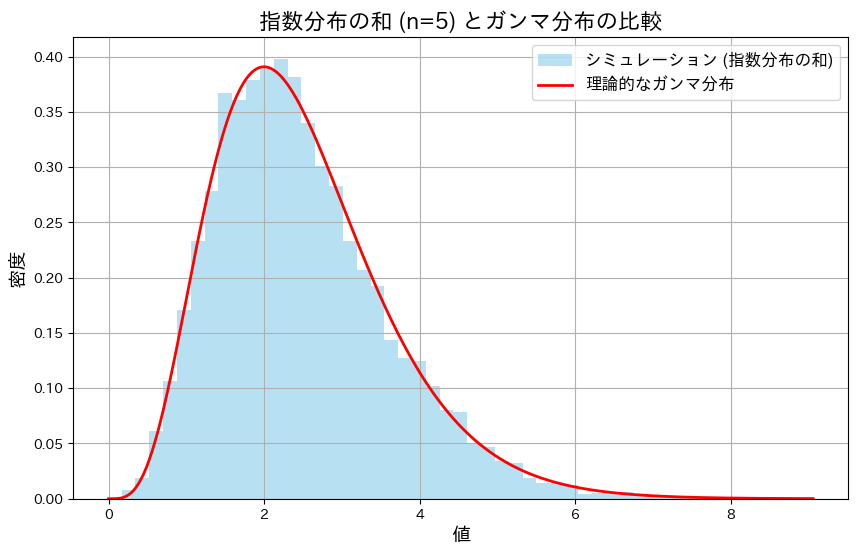
5つの指数分布の和は、形状パラメータが5のガンマ分布に一致することが確認できました。
次に、nを変化させてシミュレーションを行い、分布の形状の変化を観察します。また、それらの分布がガンマ分布と一致するかを確認します。
# 2016 Q2(4) 2024.11.18
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
# パラメータ設定
lambda_value = 2 # 真のλ
n_values = [2, 5, 10, 20] # nの値を変化させる
sample_size = 10000 # シミュレーションのサンプルサイズ
# 2x2のグリッドでプロット
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
axes = axes.flatten()
for i, n in enumerate(n_values):
# 指数分布の和をシミュレーション
sum_of_exponentials = np.sum(np.random.exponential(scale=1/lambda_value, size=(sample_size, n)), axis=1)
# ガンマ分布の理論値を計算
x = np.linspace(0, 20, 1000) # 横軸の範囲を0~20に設定
gamma_pdf = gamma.pdf(x, a=n, scale=1/lambda_value)
# ヒストグラムと理論的なガンマ分布をプロット
ax = axes[i]
ax.hist(sum_of_exponentials, bins=50, range=(0, 20), density=True, alpha=0.6, color='skyblue', label='シミュレーション (指数分布の和)')
ax.plot(x, gamma_pdf, 'r-', label='理論的なガンマ分布', linewidth=2)
# グラフの設定
ax.set_title(f'n={n}', fontsize=14)
ax.set_xlabel('値', fontsize=12)
ax.set_ylabel('密度', fontsize=12)
ax.legend(fontsize=10)
ax.grid(True)
# 全体のレイアウト調整
plt.suptitle('nを変化させた指数分布の和とガンマ分布の比較', fontsize=16)
plt.tight_layout(rect=[0, 0, 1, 0.96])
plt.show()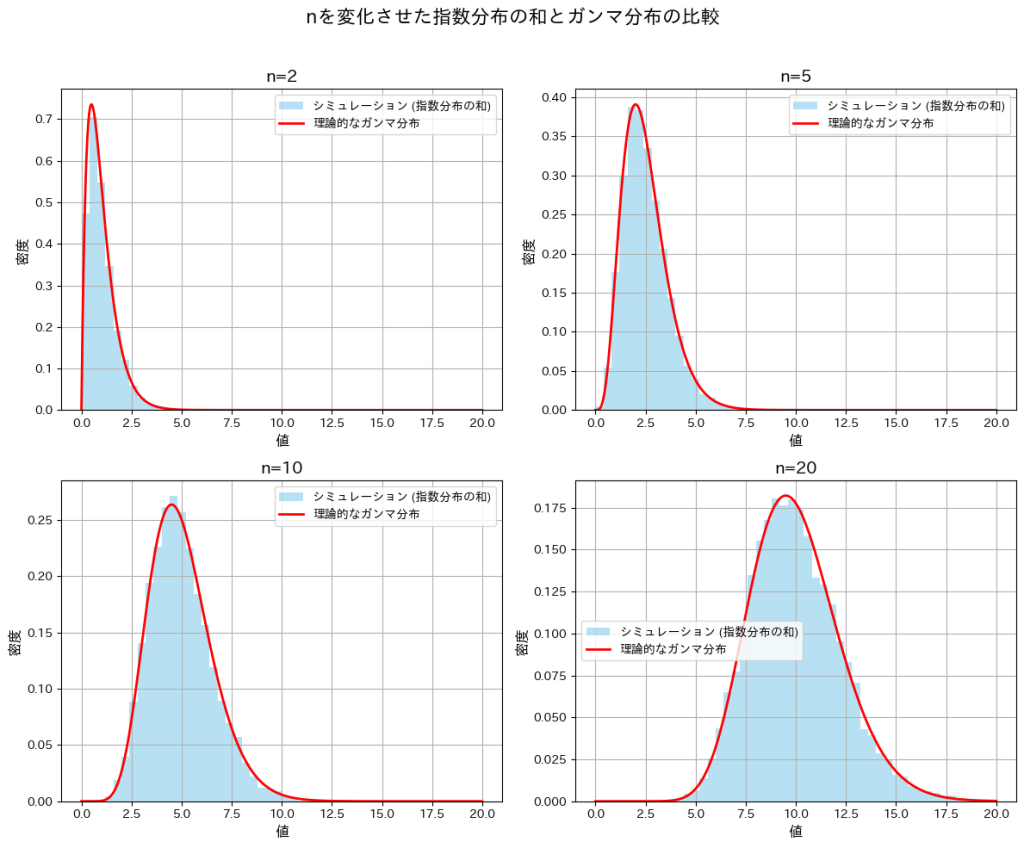
nが小さいときは分布が右に裾が長くなり、nが大きくなるにつれて左右対称に近づいています。また、どのnにおいても形状パラメータnのガンマ分布とよく一致していることが確認できました。
2016 Q2(3)
指数分布のλと、上側α点を返す関数の最尤推定量を求め、不偏であるか確認しました。

コード
最尤推定量 をシミュレーションし、理論値
をシミュレーションし、理論値 と比較します。共にグラフに描画し、どの程度一致しているか確認します。
と比較します。共にグラフに描画し、どの程度一致しているか確認します。
# 2016 Q2(3) 2024.11.17
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
lambda_value = 2 # 真のλ
n = 100 # サンプル数
c = 1.0 # Q(c) を計算するための c の値
alpha_values = [0.1, 0.25, 0.5, 0.75, 0.9] # αの値
# 1. 指数分布からサンプルを生成
samples = np.random.exponential(scale=1/lambda_value, size=n)
# 2. λの最尤推定量を計算
lambda_hat = n / np.sum(samples)
# 3. Q(c) の最尤推定量を計算
Q_hat_c = np.exp(-lambda_hat * c)
Q_theoretical_c = np.exp(-lambda_value * c)
# 4. u(α) の最尤推定量を計算
u_hat_alpha = [-np.mean(samples) * np.log(alpha) for alpha in alpha_values]
u_theoretical_alpha = [-np.log(alpha) / lambda_value for alpha in alpha_values]
# グラフ作成部分
plt.figure(figsize=(10, 6))
# 理論値と最尤推定量の u(α) をプロット
plt.plot(alpha_values, u_theoretical_alpha, 'r-o', label='u(α) 理論値', linewidth=2)
plt.plot(alpha_values, u_hat_alpha, 'b--s', label='u(α) 最尤推定量', linewidth=2) # 'b--s' で破線とマーカーを指定
# グラフの設定
plt.title('u(α) の理論値と最尤推定量の比較', fontsize=16)
plt.xlabel('α', fontsize=14)
plt.ylabel('u(α)', fontsize=14)
plt.legend(fontsize=12)
plt.grid(True)
plt.xticks(alpha_values)
# グラフの表示
plt.show()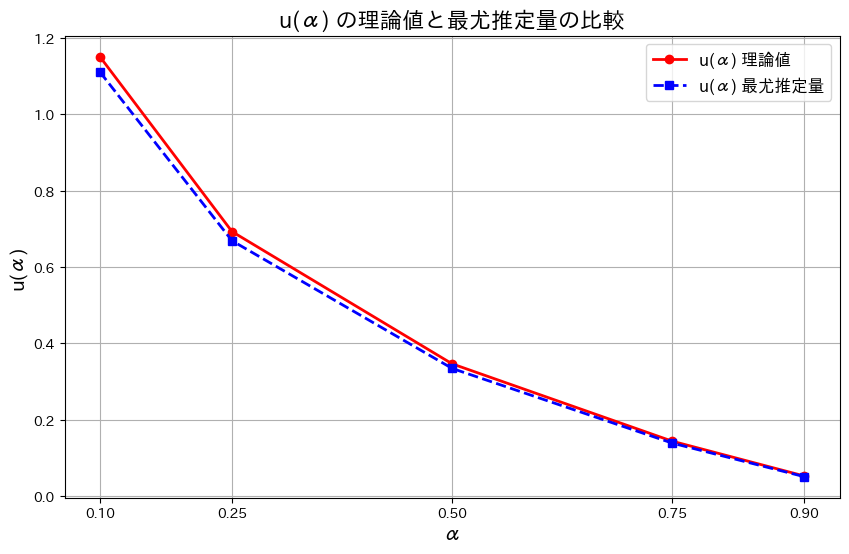
はわずかに誤差があるものの概ね一致しました。また誤差はαが大きくなるにつれて小さくなります。その理由は、αが大きくなるとu(α)の値が小さくなり、分布の高密度な部分にサンプルが集中するためと考えられます。
2016 Q2(2)
指数分布の上側α点を返す関数を求めました。

コード
パラメータλ=2の指数分布において、Q(c)=P(X>c)をシミュレーションによって求め、理論値と比較します。c=1とします。また、P(X>u(α))=αとなるu(α)も同様に比較します。
# 2016 Q2(2) 2024.11.16
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
lambda_value = 2 # λの値
sample_size = 10000 # シミュレーションに使用するサンプル数
c = 1.0 # 上側確率を計算するための定数 c
alpha_values = [0.1, 0.25, 0.5, 0.75, 0.9] # 上側 100α% 点を確認する α の値
# 1. 上側確率 Q(c) のシミュレーション
random_samples = np.random.exponential(scale=1/lambda_value, size=sample_size)
empirical_prob_c = np.mean(random_samples > c) # シミュレーションによる上側確率
theoretical_prob_c = np.exp(-lambda_value * c) # 理論的な上側確率
# 結果表示
print("上側確率 Q(c) のシミュレーション結果")
print(f"理論的な Q(c) = {theoretical_prob_c:.4f}")
print(f"シミュレーションによる Q(c) = {empirical_prob_c:.4f}\n")
# 2. 上側 100α% 点 u(α) の確認
alpha_results = []
for alpha in alpha_values:
u_alpha = -np.log(alpha) / lambda_value # 理論的な上側 100α% 点
empirical_prob_alpha = np.mean(random_samples > u_alpha) # u(α) を超える割合
alpha_results.append((alpha, u_alpha, empirical_prob_alpha))
# 結果表示
print("上側 100α% 点 u(α) のシミュレーション結果")
for alpha, u_alpha, empirical_prob_alpha in alpha_results:
print(f"α = {alpha:.2f} | 理論的な u(α) = {u_alpha:.4f} | 理論的確率P(X>u(α)) = {alpha:.2f} | シミュレーション確率 = {empirical_prob_alpha:.4f}")
# ヒストグラムのプロット
plt.figure(figsize=(10, 6))
plt.hist(random_samples, bins=50, density=True, alpha=0.6, color='skyblue', label='サンプルのヒストグラム')
# 理論的な確率密度関数
x = np.linspace(0, max(random_samples), 1000)
theoretical_pdf = lambda_value * np.exp(-lambda_value * x)
plt.plot(x, theoretical_pdf, 'r-', label='理論的な確率密度関数', linewidth=2)
# 上側 100α% 点 u(α) のプロット
for alpha, u_alpha, _ in alpha_results:
plt.axvline(u_alpha, linestyle='dashed', label=f'u({alpha}) = {u_alpha:.2f}')
# グラフ設定
plt.title(f'指数分布 Exp({lambda_value}) のシミュレーションと理論分布')
plt.xlabel('x')
plt.ylabel('密度')
plt.legend(fontsize=10)
plt.grid(True)
# プロット表示
plt.show()上側確率 Q(c) のシミュレーション結果
理論的な Q(c) = 0.1353
シミュレーションによる Q(c) = 0.1365
上側 100α% 点 u(α) のシミュレーション結果
α = 0.10 | 理論的な u(α) = 1.1513 | 理論的確率P(X>u(α)) = 0.10 | シミュレーション確率 = 0.1035
α = 0.25 | 理論的な u(α) = 0.6931 | 理論的確率P(X>u(α)) = 0.25 | シミュレーション確率 = 0.2480
α = 0.50 | 理論的な u(α) = 0.3466 | 理論的確率P(X>u(α)) = 0.50 | シミュレーション確率 = 0.4962
α = 0.75 | 理論的な u(α) = 0.1438 | 理論的確率P(X>u(α)) = 0.75 | シミュレーション確率 = 0.7513
α = 0.90 | 理論的な u(α) = 0.0527 | 理論的確率P(X>u(α)) = 0.90 | シミュレーション確率 = 0.9011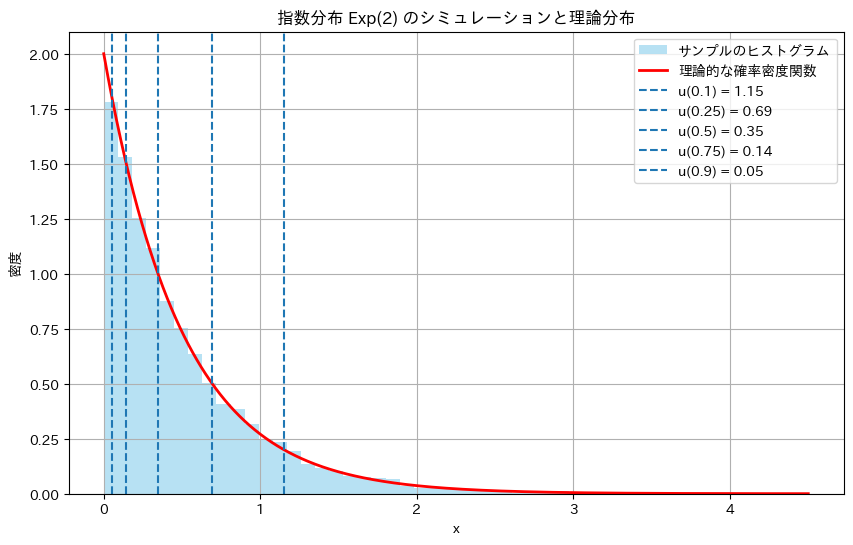
Q(c)=P(X>c)とP(X>u(α))の理論値とシミュレーション結果は非常によく一致しました。
2016 Q2(1)
指数分布の期待値を求めました。
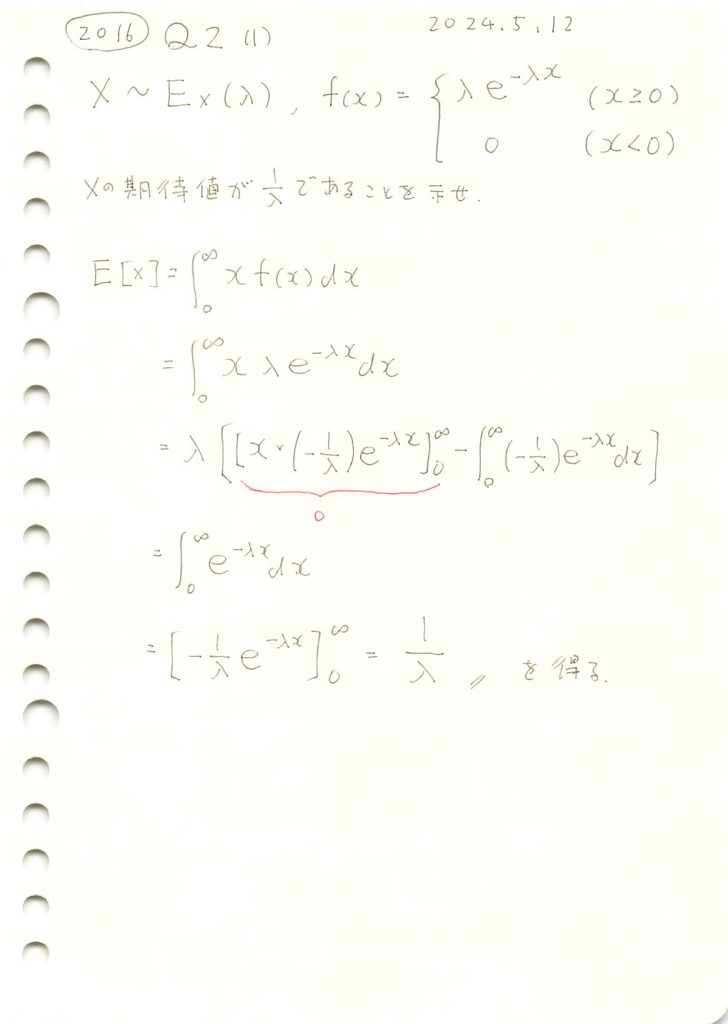
コード
指数分布Exp(λ)に従うXの確率密度関数を とするとき、Xのシミュレーションを行い、その分布のヒストグラムと理論的な確率密度関数のグラフを重ねて描画してみます。λ=2とします。
とするとき、Xのシミュレーションを行い、その分布のヒストグラムと理論的な確率密度関数のグラフを重ねて描画してみます。λ=2とします。
# 2016 Q2(1) 2024.11.15
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションとプロット
def simulate_and_plot_exponential(lambda_value=2, sample_size=50000, bins=100):
# 指数分布に従う乱数を生成
random_samples = np.random.exponential(scale=1/lambda_value, size=sample_size)
# 理論的な確率密度関数を計算
x = np.linspace(0, 5, 1000)
theoretical_pdf = lambda_value * np.exp(-lambda_value * x)
# サンプルのヒストグラムを描画
plt.figure(figsize=(10, 6))
plt.hist(random_samples, bins=bins, density=True, alpha=0.6, color='skyblue', label='サンプルのヒストグラム')
# 理論的な確率密度関数を重ねる
plt.plot(x, theoretical_pdf, 'r-', label='理論的な確率密度関数', linewidth=2)
# 期待値を計算
simulated_mean = np.mean(random_samples)
theoretical_mean = 1 / lambda_value
# 期待値を直線でプロット
plt.axvline(simulated_mean, color='green', linestyle='dashed', linewidth=2, label=f'シミュレーション期待値: {simulated_mean:.2f}')
plt.axvline(theoretical_mean, color='blue', linestyle='dotted', linewidth=2, label=f'理論期待値: {theoretical_mean:.2f}')
# グラフの設定
plt.title(f'指数分布のシミュレーションと理論分布 (λ={lambda_value})', fontsize=16)
plt.xlabel('x', fontsize=14)
plt.ylabel('密度', fontsize=14)
plt.legend(fontsize=12)
plt.grid(True)
# プロットを表示
plt.show()
# 実行
simulate_and_plot_exponential()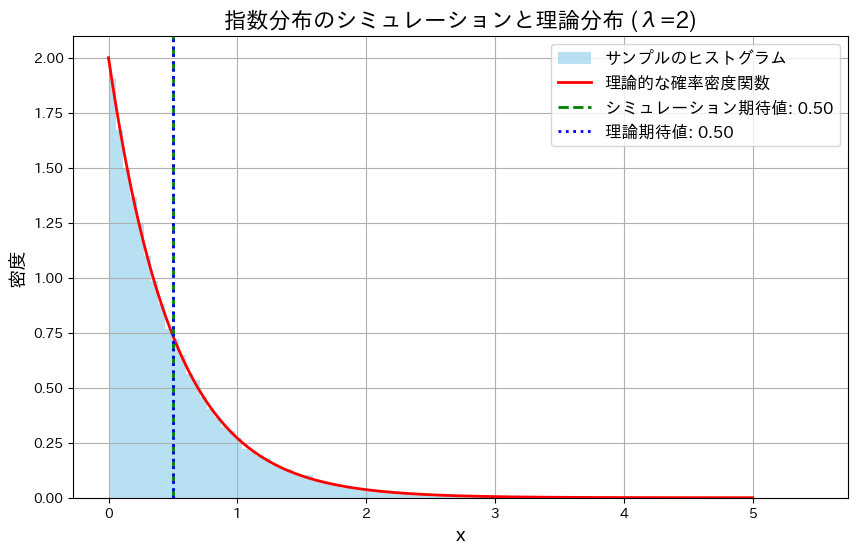
Xの分布は、確率密度関数とよく一致しており、シミュレーションで得られた期待値も理論値に非常に近い値となりました。
では、次にλを変化させて同様の実験を行い、グラフの形状の変化と期待値がどのように変化するかを確認します。
# 2016 Q2(1) 2024.11.15
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションとプロット
def simulate_and_plot_adjusted_lambdas(lambdas=[0.5, 1, 2, 3], sample_size=50000, bins=100):
fig, axes = plt.subplots(2, 2, figsize=(12, 10), sharex=True, sharey=True)
x = np.linspace(0, 6, 1000) # 横軸の範囲を0~6に限定
for i, lambda_value in enumerate(lambdas):
row, col = divmod(i, 2)
ax = axes[row, col]
# 乱数生成と理論値計算
random_samples = np.random.exponential(scale=1/lambda_value, size=sample_size)
theoretical_pdf = lambda_value * np.exp(-lambda_value * x)
# ヒストグラムと理論分布
ax.hist(random_samples, bins=bins, range=(0, 6), density=True, alpha=0.6, color='skyblue', label='サンプルのヒストグラム')
ax.plot(x, theoretical_pdf, 'r-', label='理論的な確率密度関数', linewidth=2)
# 期待値を計算してプロット
simulated_mean = np.mean(random_samples)
theoretical_mean = 1 / lambda_value
ax.axvline(simulated_mean, color='green', linestyle='dashed', linewidth=2, label=f'シミュレーション期待値: {simulated_mean:.2f}')
ax.axvline(theoretical_mean, color='blue', linestyle='dotted', linewidth=2, label=f'理論期待値: {theoretical_mean:.2f}')
# グラフ設定
ax.set_xlim(0, 6) # 横軸を0~6に限定
ax.set_title(f'λ={lambda_value}', fontsize=14)
ax.set_xlabel('x', fontsize=12)
ax.set_ylabel('密度', fontsize=12)
ax.legend(fontsize=10)
ax.grid(True)
# 全体のタイトルと調整
plt.suptitle('異なるλにおける指数分布のシミュレーションと理論分布', fontsize=16)
plt.tight_layout(rect=[0, 0, 1, 0.96]) # タイトルとの重なり防止
plt.show()
# 実行
simulate_and_plot_adjusted_lambdas()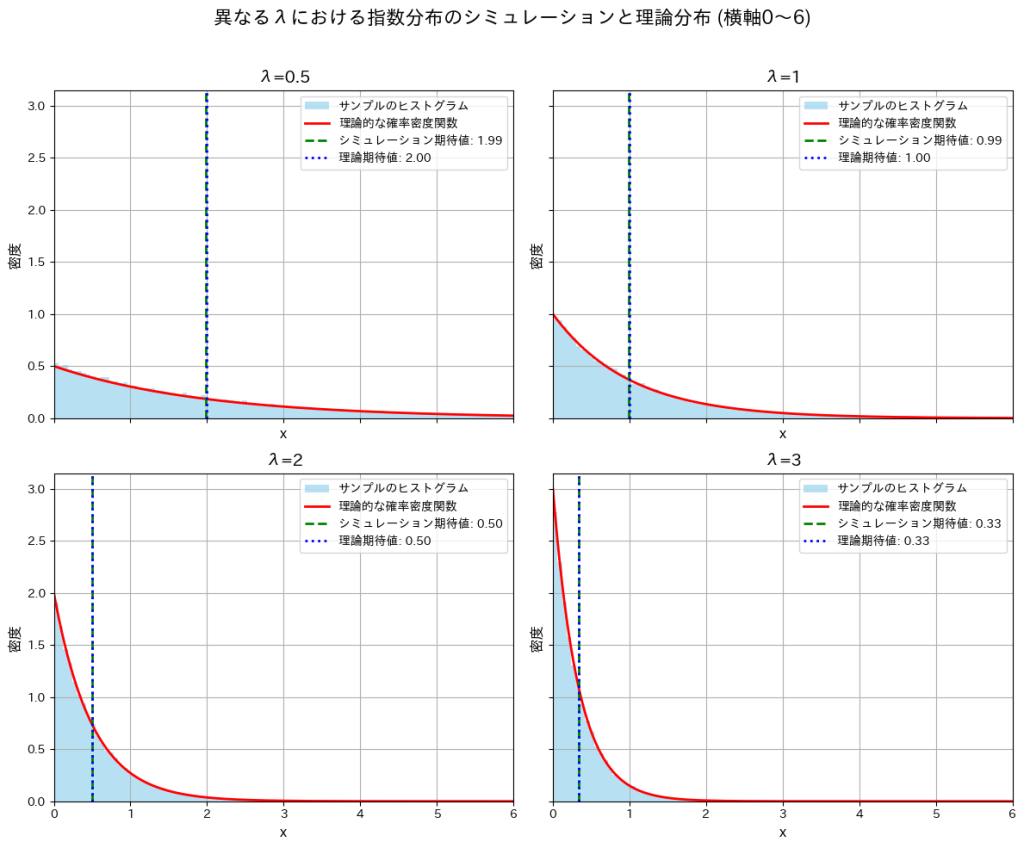
λが大きくなるにつれて分布の形状は急こう配になり期待値が小さくなることが確認できました。λの増加によって小さい値が観測される確率が高くなるためだと考えられます。
2016 Q1(4)
正規分布の母平均μに対してθ=exp(μ)をパラメータとする尤度関数からフィッシャー情報量を求め、その逆数が不偏推定量の分散と一致するか否かを確かめた。
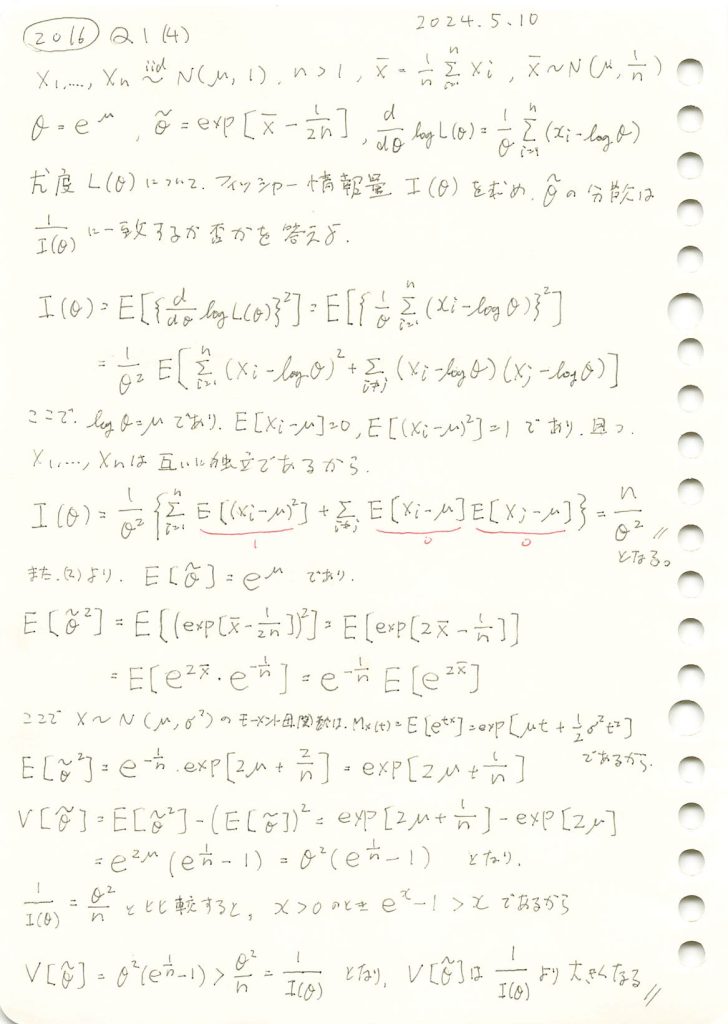
コード
![V[\tilde{\theta}] > \frac{1}{I(\theta)}](https://statistics.blue/wp-content/ql-cache/quicklatex.com-2d9eb86cf44967a084eda006cf24f813_l3.png "Rendered by QuickLaTeX.com") となることを確認するために、両辺をグラフで比較してみます。
となることを確認するために、両辺をグラフで比較してみます。
# 2016 Q1(4) 2024.11.14
import numpy as np
import matplotlib.pyplot as plt
# θ の範囲設定
theta_values = np.linspace(0.1, 5.0, 10) # 0.1から5.0までの範囲で計算
n_samples = 50 # サンプルサイズ
# 分散 V[θ~] と 1/I(θ) の計算
V_theta_tilde = theta_values**2 * (np.exp(1 / n_samples) - 1)
Fisher_info_inverse = theta_values**2 / n_samples # 1 / I(θ)
# 折れ線グラフの描画
plt.figure(figsize=(10, 6))
plt.plot(theta_values, V_theta_tilde, label=r'$V[\tilde{\theta}]$ (不偏推定量の分散)', color='blue', linestyle='-', marker='o')
plt.plot(theta_values, Fisher_info_inverse, label=r'$1/I(\theta)$ (フィッシャー情報量の逆数)', color='red', linestyle='--', marker='s')
plt.title('不偏推定量の分散とフィッシャー情報量の逆数の比較', fontsize=16)
plt.xlabel(r'$\theta$', fontsize=14)
plt.ylabel('分散', fontsize=14)
plt.legend(fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()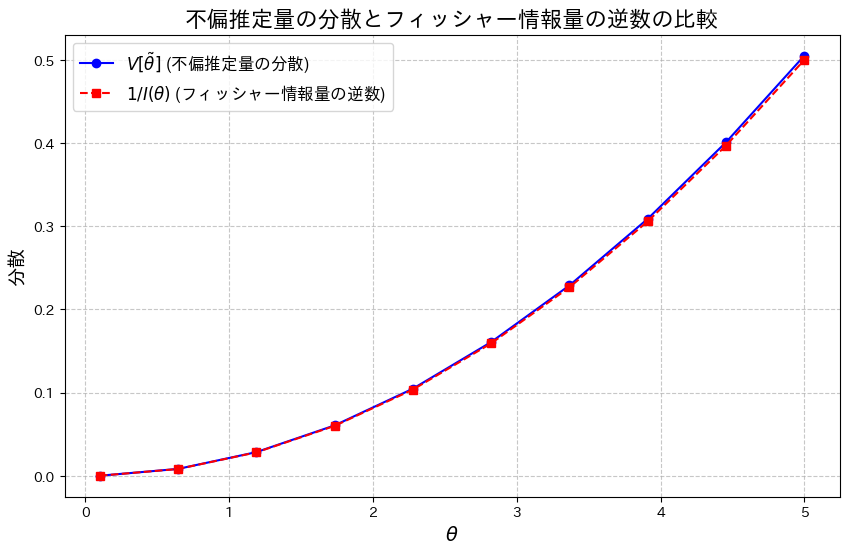
わずかに![V[\tilde{\theta}] > \frac{1}{I(\theta)}](https://statistics.blue/wp-content/ql-cache/quicklatex.com-82d5b6f70c4a45274f861f27ff6b84c1_l3.png "Rendered by QuickLaTeX.com") となっているようです。
となっているようです。
次に、2式の差![V[\tilde{\theta}] - \frac{1}{I(\theta)}](https://statistics.blue/wp-content/ql-cache/quicklatex.com-19034a0c4a68e2a8e2003f7fb1d8afbd_l3.png "Rendered by QuickLaTeX.com") をプロットし、その差を確認してみます。
をプロットし、その差を確認してみます。
# 2016 Q1(4) 2024.11.14
import numpy as np
import matplotlib.pyplot as plt
# θ の範囲設定
theta_values = np.linspace(0.1, 5.0, 10) # 0.1から5.0までの範囲で計算
n_samples = 50 # サンプルサイズ
# 分散 V[θ~] と 1/I(θ) の計算
V_theta_tilde = theta_values**2 * (np.exp(1 / n_samples) - 1)
Fisher_info_inverse = theta_values**2 / n_samples # 1 / I(θ)
# V[θ~] - 1/I(θ) を計算
diff_V_Fisher = V_theta_tilde - Fisher_info_inverse
# 差分をプロット
plt.figure(figsize=(10, 6))
plt.plot(theta_values, diff_V_Fisher, color='purple', linestyle='-', marker='o', label=r'$V[\tilde{\theta}] - \frac{1}{I(\theta)}$')
plt.title('不偏推定量の分散とフィッシャー情報量逆数の差', fontsize=16)
plt.xlabel(r'$\theta$', fontsize=14)
plt.ylabel(r'$V[\tilde{\theta}] - \frac{1}{I(\theta)}$', fontsize=14)
plt.axhline(0, color='black', linestyle='--', linewidth=1) # y=0 の線を追加
plt.legend(fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()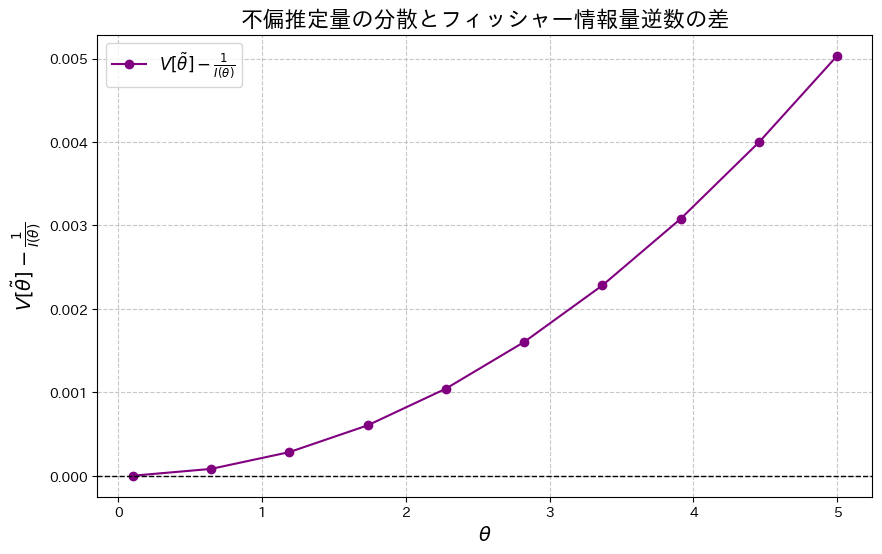
2式の差が存在することが確認できました。この差は、θが増加するにつれて大きくなる傾向が見られます。
次に、乱数を用いたシミュレーションを行い、![V[\tilde{\theta}]](https://statistics.blue/wp-content/ql-cache/quicklatex.com-179947b17f89f0eed24e07077e22915b_l3.png "Rendered by QuickLaTeX.com") を重ねてプロットしてみます。
を重ねてプロットしてみます。
# 2016 Q1(4) 2024.11.14
import numpy as np
import matplotlib.pyplot as plt
# 再定義:thetaの範囲
theta_values = np.linspace(0.1, 5.0, 100)
n_samples = 50
n_trials = 10000 # シミュレーション試行回数
# 理論分散 V[θ~] と 1/I(θ) の計算
V_theta_tilde = theta_values**2 * (np.exp(1 / n_samples) - 1)
Fisher_info_inverse = theta_values**2 / n_samples
# シミュレーションによる分散の再計算
simulated_V_theta_tilde = []
for theta in theta_values:
mse_trials = []
for _ in range(n_trials):
sample = np.random.normal(loc=np.log(theta), scale=1, size=n_samples) # 平均 log(theta), 分散 1
X_bar = np.mean(sample)
theta_tilde = np.exp(X_bar - 1 / (2 * n_samples)) # 不偏推定量
mse_trials.append((theta_tilde - theta)**2) # 二乗誤差
simulated_var = np.mean(mse_trials) # シミュレーションによる分散 (MSE)
simulated_V_theta_tilde.append(simulated_var)
# グラフの描画
plt.figure(figsize=(10, 6))
plt.plot(theta_values, V_theta_tilde, label='理論分散 $V[\\tilde{\\theta}]$', linestyle='-', color='blue', alpha=0.7)
plt.scatter(theta_values, simulated_V_theta_tilde, label='シミュレーション分散 $V[\\tilde{\\theta}]$', marker='s', color='red', alpha=0.6)
plt.plot(theta_values, Fisher_info_inverse, label='$1/I(\\theta)$ (フィッシャー情報量の逆数)', linestyle='--', color='green', alpha=0.8)
plt.title('不偏推定量の分散とフィッシャー情報量の逆数の比較', fontsize=16)
plt.xlabel('$\\theta$', fontsize=14)
plt.ylabel('分散', fontsize=14)
plt.legend(fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()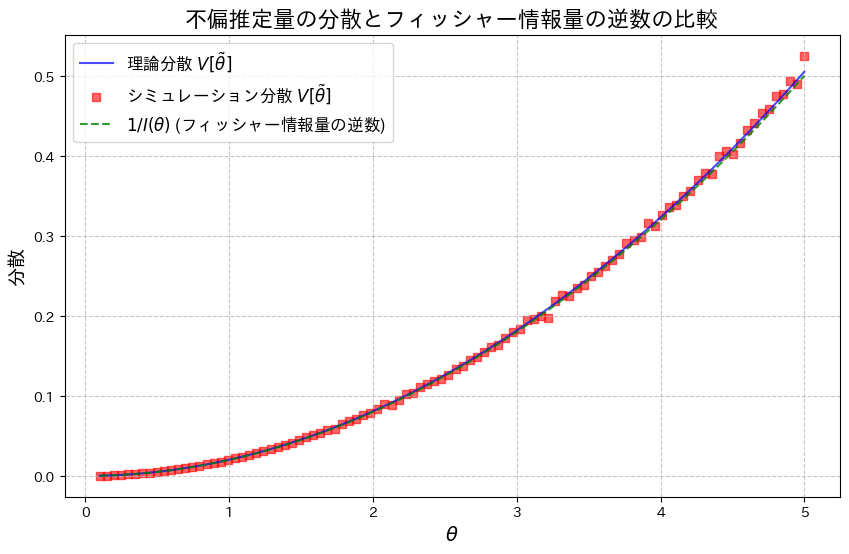
は、わずかに を下回る場合があるようです。これは、シミュレーションにおける乱数の誤差によるものだと考えられます。
を下回る場合があるようです。これは、シミュレーションにおける乱数の誤差によるものだと考えられます。
2016 Q1(3)
正規分布の母平均μに対するθ=exp(μ)の最尤推定量の平均二乗誤差が0になることを示しました。

コード
シミュレーションを行います。 に対して、
に対して、![MSE[\hat{\theta}] = E\left[(\hat{\theta} - \theta)^2\right]](https://statistics.blue/wp-content/ql-cache/quicklatex.com-0777a7865e923e07c8ee9b8bdb4b9add_l3.png "Rendered by QuickLaTeX.com") を計算し、理論値とともにプロットします。サンプルサイズnを増加させて、MSEの変化を観察します。
を計算し、理論値とともにプロットします。サンプルサイズnを増加させて、MSEの変化を観察します。
# 2016 Q1(3) 2024.11.13
import numpy as np
import matplotlib.pyplot as plt
# 真の値とシミュレーション設定
mu_true = 1.0 # 真の平均 (mu)
theta_true = np.exp(mu_true) # 真の θ = e^mu
n_trials = 10000 # シミュレーション試行回数
sample_sizes = np.arange(5, 101, 5) # サンプルサイズの範囲
# MSEを格納するリスト
mse_simulated = []
# 理論的なMSEの計算関数
def theoretical_mse(n, mu):
return np.exp(2 * mu) * (np.exp(2 / n) - 2 * np.exp(1 / (2 * n)) + 1)
mse_theoretical = [theoretical_mse(n, mu_true) for n in sample_sizes]
# シミュレーションでのMSE計算
for n_samples in sample_sizes:
mse_trials = []
for _ in range(n_trials):
sample = np.random.normal(loc=mu_true, scale=1, size=n_samples)
X_bar = np.mean(sample)
theta_hat = np.exp(X_bar) # 最尤推定量
mse_trials.append((theta_hat - theta_true) ** 2) # MSEの計算
mse_simulated.append(np.mean(mse_trials)) # 試行平均を格納
# グラフの描画
plt.figure(figsize=(10, 6))
plt.plot(sample_sizes, mse_simulated, marker='o', linestyle='-', color='blue', label='シミュレーション MSE')
plt.plot(sample_sizes, mse_theoretical, marker='s', linestyle='--', color='red', label='理論的 MSE')
plt.title('MSEのシミュレーションと理論値', fontsize=16)
plt.xlabel('サンプルサイズ $n$', fontsize=14)
plt.ylabel('MSE', fontsize=14)
plt.legend(fontsize=12)
plt.grid(True)
plt.show()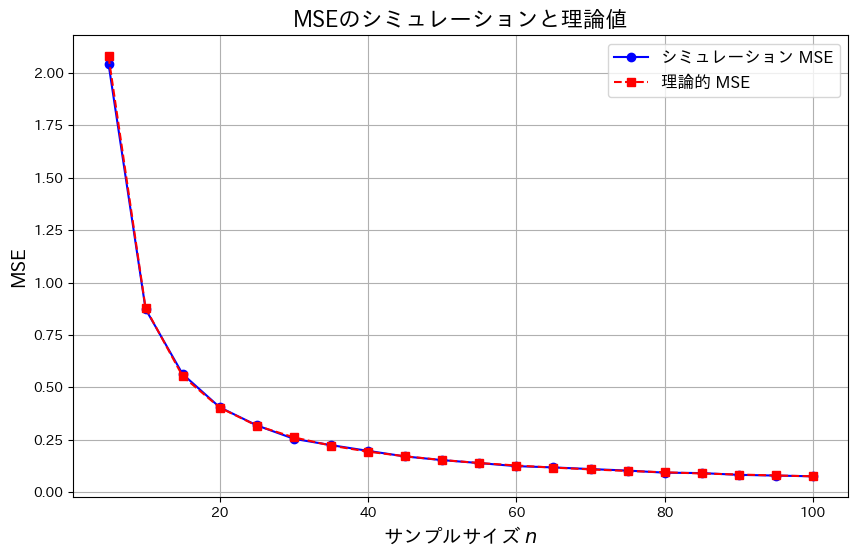
サンプルサイズnが増加するにつれて、![MSE[\hat{\theta}]](https://statistics.blue/wp-content/ql-cache/quicklatex.com-3516978b495f5fefb469c72f0782d40f_l3.png "Rendered by QuickLaTeX.com") は0に近づきました。これにより、
は0に近づきました。これにより、![\lim_{n \to \infty} MSE[\hat{\theta}] = 0](https://statistics.blue/wp-content/ql-cache/quicklatex.com-feabecc669d8001f224ea00f9a5f4289_l3.png "Rendered by QuickLaTeX.com") になることが理論とシミュレーションの両方で確認できました。また、この結果から最尤推定量
になることが理論とシミュレーションの両方で確認できました。また、この結果から最尤推定量  が漸近的一致性を持つことが分かりました。
が漸近的一致性を持つことが分かりました。
2016 Q1(2)
正規分布の母平均μに対してθ=exp(μ)をパラメータとする最尤推定量のバイアスを調べて、与式がθの不偏推定量であることを示しました。
コード
と が真のθに近づくか確認するため、シミュレーションを行います。まずはサンプルサイズn=5で試してみます。
が真のθに近づくか確認するため、シミュレーションを行います。まずはサンプルサイズn=5で試してみます。
# 2016 Q1(2) 2024.11.12
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションのパラメータ
mu_true = 1.0 # 真の平均 (mu)
theta_true = np.exp(mu_true) # 真の θ = e^mu
n_samples = 5 # サンプルサイズ
n_trials = 100000 # シミュレーション試行回数
# 乱数生成と推定量の計算
theta_hat_estimates = []
theta_tilde_estimates = []
for _ in range(n_trials):
sample = np.random.normal(loc=mu_true, scale=1/np.sqrt(n_samples), size=n_samples)
X_bar = np.mean(sample) # 標本平均
# 最尤推定量 θ^
theta_hat = np.exp(X_bar)
theta_hat_estimates.append(theta_hat)
# 不偏推定量 θ~
theta_tilde = np.exp(X_bar - 1/(2*n_samples))
theta_tilde_estimates.append(theta_tilde)
# 推定量の平均を計算
theta_hat_mean = np.mean(theta_hat_estimates)
theta_tilde_mean = np.mean(theta_tilde_estimates)
# グラフ描画
plt.figure(figsize=(12, 6))
# ヒストグラムの描画
plt.hist(theta_hat_estimates, bins=100, density=True, alpha=0.6, color='blue', label='$\\hat{\\theta}$ (最尤推定量)')
plt.hist(theta_tilde_estimates, bins=100, density=True, alpha=0.6, color='green', label='$\\tilde{\\theta}$ (不偏推定量)')
# 真の値を赤線で表示
plt.axvline(theta_true, color='red', linestyle='dashed', linewidth=2, label=f'真の$\\theta$: {theta_true:.2f}')
# θハットとθチルダの平均をそれぞれ緑線と青線で表示
plt.axvline(theta_hat_mean, color='blue', linestyle='dotted', linewidth=2, label=f'$\\hat{{\\theta}}$平均: {theta_hat_mean:.2f}')
plt.axvline(theta_tilde_mean, color='green', linestyle='dotted', linewidth=2, label=f'$\\tilde{{\\theta}}$平均: {theta_tilde_mean:.2f}')
# グラフのタイトルとラベル
plt.title('$\\hat{\\theta}$ と $\\tilde{\\theta}$ の分布', fontsize=16)
plt.xlabel('$\\theta$', fontsize=14)
plt.ylabel('密度', fontsize=14)
plt.legend(fontsize=12)
plt.grid(True)
plt.show()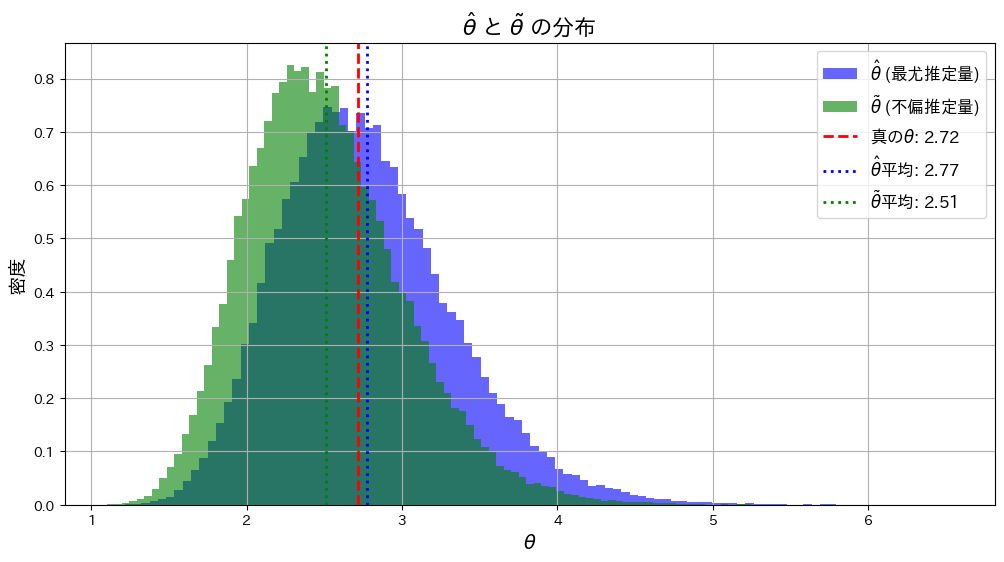
は よりも真のθに近くなっています。これはサンプルサイズnが小さいことと、および推定量の分散の違いが起因しているのかもしれません。
よりも真のθに近くなっています。これはサンプルサイズnが小さいことと、および推定量の分散の違いが起因しているのかもしれません。
次に、サンプルサイズn=5, 10, 20, 50と変化させて、この乖離がどのように変わるかを確認します。
# 2016 Q1(2) 2024.11.12
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションのパラメータ
mu_true = 1.0 # 真の平均 (mu)
theta_true = np.exp(mu_true) # 真の theta = e^mu
n_trials = 100000 # シミュレーション試行回数
sample_sizes = [5, 10, 20, 50] # サンプルサイズのリスト
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
axes = axes.ravel() # 2x2 の配列を平坦化
for i, n_samples in enumerate(sample_sizes):
theta_hat_estimates = []
theta_tilde_estimates = []
for _ in range(n_trials):
sample = np.random.normal(loc=mu_true, scale=1/np.sqrt(n_samples), size=n_samples)
X_bar = np.mean(sample)
# 最尤推定量
theta_hat = np.exp(X_bar)
theta_hat_estimates.append(theta_hat)
# 不偏推定量
theta_tilde = np.exp(X_bar - 1/(2*n_samples))
theta_tilde_estimates.append(theta_tilde)
theta_hat_mean = np.mean(theta_hat_estimates)
theta_tilde_mean = np.mean(theta_tilde_estimates)
# ヒストグラムのプロット
axes[i].hist(theta_hat_estimates, bins=100, density=True, alpha=0.6, color='blue', label='$\\hat{\\theta}$ (最尤推定量)')
axes[i].hist(theta_tilde_estimates, bins=100, density=True, alpha=0.6, color='green', label='$\\tilde{\\theta}$ (不偏推定量)')
axes[i].axvline(theta_true, color='red', linestyle='dashed', linewidth=2, label=f'真の$\\theta$: {theta_true:.2f}')
axes[i].axvline(theta_hat_mean, color='blue', linestyle='dotted', linewidth=2, label=f'$\\hat{{\\theta}}$平均: {theta_hat_mean:.2f}')
axes[i].axvline(theta_tilde_mean, color='green', linestyle='dotted', linewidth=2, label=f'$\\tilde{{\\theta}}$平均: {theta_tilde_mean:.2f}')
axes[i].set_title(f'サンプルサイズ n={n_samples}')
axes[i].set_xlabel('$\\theta$')
axes[i].set_ylabel('密度')
axes[i].legend()
axes[i].grid(True)
plt.suptitle('$\\hat{\\theta}$ と $\\tilde{\\theta}$ の分布', fontsize=16)
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()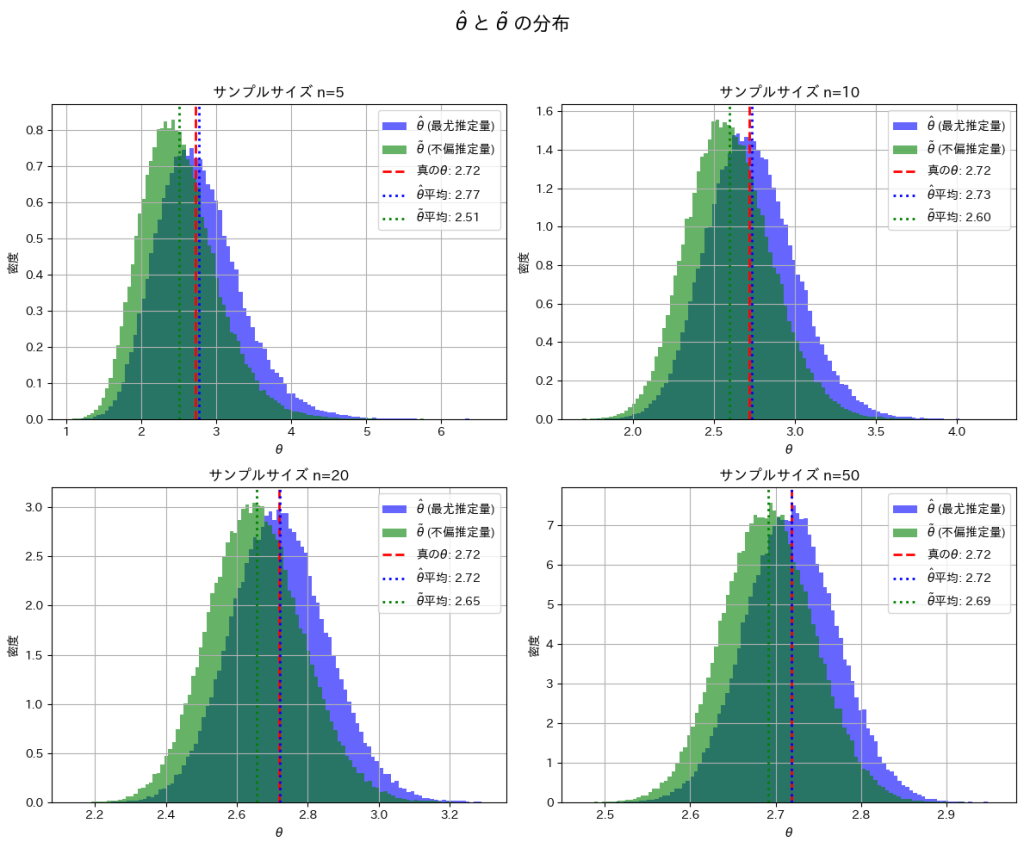
nを大きくすることで、とは真のθの間の乖離が小さくなることを確認できました。
次に、nを変化させてとがどのように変化するか折れ線グラフで見てみます。
# 2016 Q1(2) 2024.11.12
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションのパラメータ
mu_true = 1.0 # 真の平均 (mu)
theta_true = np.exp(mu_true) # 真の theta = e^mu
n_trials = 100000 # シミュレーション試行回数
sample_sizes = np.arange(5, 101, 5) # サンプルサイズ n の範囲 [5, 10, ..., 100]
# 推定量の平均値を格納するリスト
theta_hat_means = []
theta_tilde_means = []
# サンプルサイズを変化させてシミュレーション
for n_samples in sample_sizes:
theta_hat_estimates = []
theta_tilde_estimates = []
for _ in range(n_trials):
sample = np.random.normal(loc=mu_true, scale=1/np.sqrt(n_samples), size=n_samples)
X_bar = np.mean(sample)
# 最尤推定量
theta_hat = np.exp(X_bar)
theta_hat_estimates.append(theta_hat)
# 不偏推定量
theta_tilde = np.exp(X_bar - 1/(2*n_samples))
theta_tilde_estimates.append(theta_tilde)
# 平均値を格納
theta_hat_means.append(np.mean(theta_hat_estimates))
theta_tilde_means.append(np.mean(theta_tilde_estimates))
# 折れ線グラフの描画
plt.figure(figsize=(10, 6))
plt.plot(sample_sizes, theta_hat_means, marker='o', linestyle='-', color='blue', label='$\\hat{\\theta}$ (最尤推定量)')
plt.plot(sample_sizes, theta_tilde_means, marker='s', linestyle='-', color='green', label='$\\tilde{\\theta}$ (不偏推定量)')
plt.axhline(y=theta_true, color='red', linestyle='dashed', linewidth=2, label=f'真の$\\theta$: {theta_true:.2f}')
# ラベルとタイトル
plt.title('サンプルサイズ n に対する $\\hat{\\theta}$ と $\\tilde{\\theta}$ の平均値', fontsize=16)
plt.xlabel('サンプルサイズ $n$', fontsize=14)
plt.ylabel('$\\theta$の平均値', fontsize=14)
plt.legend(fontsize=12)
plt.grid(True)
plt.show()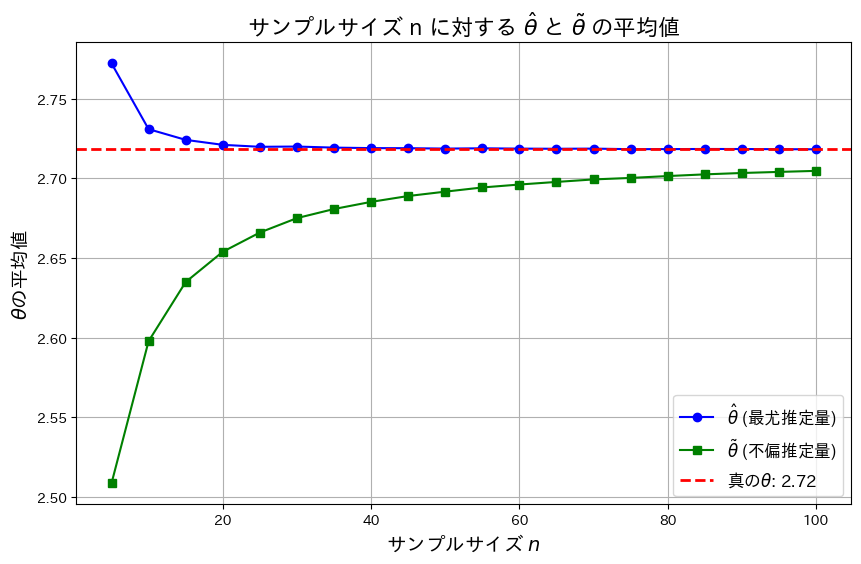
は真のθよりも大きい値を取り、徐々に減少し真のθに近づきます。一方真のθよりも小さい値を取り、徐々に増加し真のθに近づきます。また近づくスピードはのほうが早く、の分散がの分散よりも小さいことが分かります。