ホーム » 統計検定1級 2014年 統計数理 (ページ 2)
「統計検定1級 2014年 統計数理」カテゴリーアーカイブ
2014 Q4(1)-1
5個の物体の重さを、1つずつ2回量る場合で、最小二乗法による各物体の重さの推定量を求めました。

コード
最小二乗推定量 に基づいて計算してみます。
に基づいて計算してみます。
# 2014 Q4(1)-1 2025.1.8
import numpy as np
# 測定値
x = np.array([5.1, 5.2, 7.3, 7.2, 6.8, 6.7, 4.9, 4.8, 5.5, 5.4])
# 設計行列 X を構築 (各物体を2回測定)
X = np.array([
[1, 0, 0, 0, 0],
[1, 0, 0, 0, 0],
[0, 1, 0, 0, 0],
[0, 1, 0, 0, 0],
[0, 0, 1, 0, 0],
[0, 0, 1, 0, 0],
[0, 0, 0, 1, 0],
[0, 0, 0, 1, 0],
[0, 0, 0, 0, 1],
[0, 0, 0, 0, 1]
])
# 最小二乗推定量の計算
X_transpose = X.T
theta_hat = np.linalg.inv(X_transpose @ X) @ X_transpose @ x
# 結果を出力
print("最小二乗推定量 (θ̂):", theta_hat)最小二乗推定量 (θ̂): [5.15 7.25 6.75 4.85 5.45]最小二乗推定量 が計算されました。
が計算されました。
次に、手計算で導いた式に基づいて計算してみます。
# 2014 Q4(1)-1 2025.1.8
import numpy as np
# 測定値
x = np.array([5.1, 5.2, 7.3, 7.2, 6.8, 6.7, 4.9, 4.8, 5.5, 5.4])
# θ^ を手計算の式に基づいて計算
theta_hat = np.array([
(x[0] + x[1]) / 2,
(x[2] + x[3]) / 2,
(x[4] + x[5]) / 2,
(x[6] + x[7]) / 2,
(x[8] + x[9]) / 2
])
# 結果を出力
print("最小二乗推定量 (θ̂):", theta_hat)最小二乗推定量 (θ̂): [5.15 7.25 6.75 4.85 5.45]最小二乗推定量が計算され、で計算された値と一致しました。
2014 Q3(2)
液体のサンプルの体積と重さから得た比重βがβ0であるという帰無仮説が棄却されないβの信頼区間を体積と重さの分散が未知の場合で求めました。

コード
分散未知の場合の信頼区間をシミュレーションし、カバー率が理論値(1 – α = 0.95)に一致するかを検証してみます。
# 2014 Q3(2) 2025.1.7
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import t
# Parameters
n = 30 # サンプルサイズ
beta_true = 1.5 # 真のβ
sigma_X = 1.0 # Xの標準偏差
sigma_Y = 3.0 # Yの標準偏差
mu_X = 5.0 # Xの平均
alpha = 0.05 # 有意水準
num_simulations = 100 # シミュレーション回数
# 分散未知の場合の信頼区間を計算する関数
def confidence_interval_unknown_variance(X, Y, beta_0, alpha):
X_bar = np.mean(X)
Y_bar = np.mean(Y)
U = Y - beta_0 * X
S_square = np.sum((U - np.mean(U))**2) / (n - 1) # 標本分散
S_star = np.sqrt(S_square)
t_alpha = t.ppf(1 - alpha / 2, df=n - 1)
lower_bound = Y_bar / X_bar - t_alpha * S_star / (np.sqrt(n) * X_bar)
upper_bound = Y_bar / X_bar + t_alpha * S_star / (np.sqrt(n) * X_bar)
return lower_bound, upper_bound
# シミュレーション
intervals_unknown = []
contains_true_beta_unknown = []
for _ in range(num_simulations):
X = np.random.normal(mu_X, sigma_X, n)
epsilon = np.random.normal(0, np.sqrt(sigma_Y**2 + (beta_true * sigma_X)**2), n)
Y = beta_true * X + epsilon
# 信頼区間を計算
ci = confidence_interval_unknown_variance(X, Y, beta_true, alpha)
intervals_unknown.append(ci)
contains_true_beta_unknown.append(ci[0] <= beta_true <= ci[1])
# カバー率を計算
cover_rate_unknown = sum(contains_true_beta_unknown) / num_simulations
print("カバー率:")
print(f" 分散未知の場合: {cover_rate_unknown:.4f}")
# 可視化
plt.figure(figsize=(12, 8))
for i, ci in enumerate(intervals_unknown):
color = 'green' if contains_true_beta_unknown[i] else 'red'
plt.plot([ci[0], ci[1]], [i, i], color=color, marker='o', label="" if i > 0 else "信頼区間")
plt.axvline(x=beta_true, color='blue', linestyle='--', label=f"真のβ: {beta_true}")
plt.title("分散未知の場合の信頼区間 (各シミュレーション)", fontsize=16)
plt.xlabel("β", fontsize=12)
plt.ylabel("シミュレーション回数", fontsize=12)
plt.legend()
plt.grid()
plt.show()カバー率:
分散未知の場合: 0.9500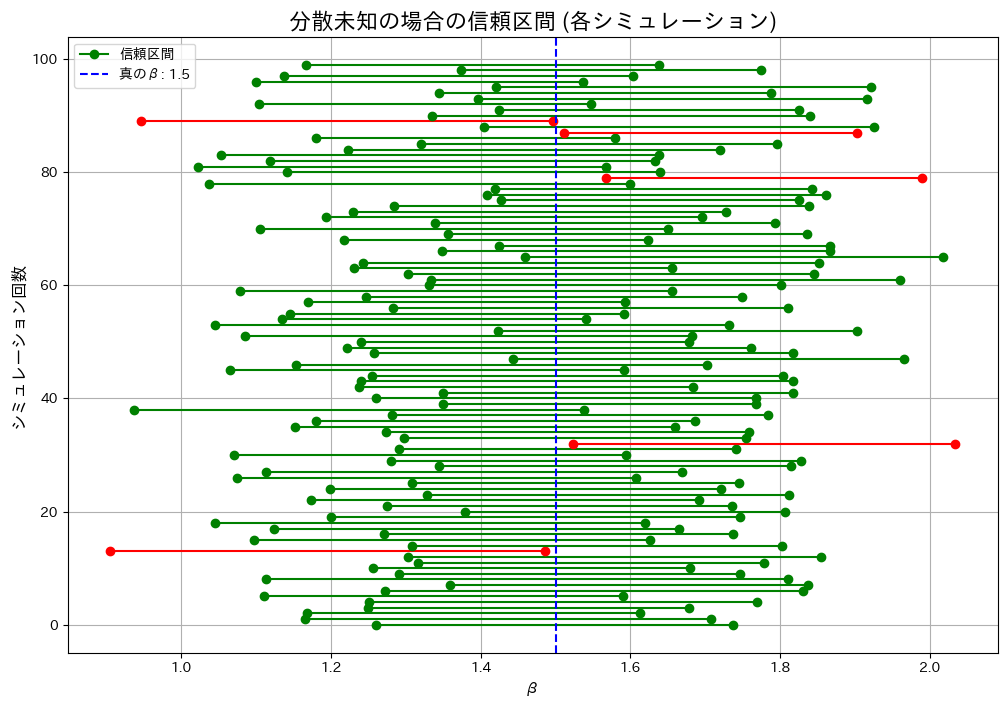
実行ごとに値は変動しましたが、カバー率は概ね理論値(1 – α = 0.95)に一致しました。
2014 Q3(2)
液体のサンプルの体積と重さから得た比重βがβ0であるという帰無仮説が棄却されないβの信頼区間を体積と重さの分散が既知の場合で求めました。

コード
分散既知の場合の信頼区間をシミュレーションし、カバー率が理論値(1 – α = 0.95)に一致するかを検証してみます。
# 2014 Q3(2) 2025.1.6
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# Parameters
n = 30 # サンプルサイズ
beta_true = 1.5 # 真のβ
sigma_X = 1.0 # Xの標準偏差
sigma_Y = 3.0 # Yの標準偏差
mu_X = 5.0 # Xの平均
alpha = 0.05 # 有意水準
num_simulations = 100 # シミュレーション回数
# 分散既知の場合の信頼区間計算関数
def precise_confidence_interval(X, Y, sigma_X, sigma_Y, alpha):
X_bar = np.mean(X)
Y_bar = np.mean(Y)
z_alpha = norm.ppf(1 - alpha / 2)
numerator = n * X_bar * Y_bar
term1 = (n * X_bar * Y_bar)**2
term2 = (n * X_bar**2 - z_alpha**2 * sigma_X**2)
term3 = (n * Y_bar**2 - z_alpha**2 * sigma_Y**2)
denominator = n * X_bar**2 - z_alpha**2 * sigma_X**2
if term2 * term3 < 0:
raise ValueError("平方根の中身が負の値です:term2 * term3 は 0 以上でなければなりません。")
sqrt_term = np.sqrt(term1 - term2 * term3)
lower_bound = (numerator - sqrt_term) / denominator
upper_bound = (numerator + sqrt_term) / denominator
return lower_bound, upper_bound
# シミュレーション
intervals_precise = []
contains_true_beta_precise = []
for _ in range(num_simulations):
X = np.random.normal(mu_X, sigma_X, n)
epsilon = np.random.normal(0, np.sqrt(sigma_Y**2 + (beta_true * sigma_X)**2), n)
Y = beta_true * X + epsilon
# 信頼区間を計算
ci = precise_confidence_interval(X, Y, sigma_X, sigma_Y, alpha)
intervals_precise.append(ci)
contains_true_beta_precise.append(ci[0] <= beta_true <= ci[1])
# カバー率を計算
cover_rate_precise = sum(contains_true_beta_precise) / num_simulations
print("カバー率:")
print(f" 分散既知の場合: {cover_rate_precise:.4f}")
# 可視化
plt.figure(figsize=(12, 8))
for i, ci in enumerate(intervals_precise):
color = 'green' if contains_true_beta_precise[i] else 'red'
plt.plot([ci[0], ci[1]], [i, i], color=color, marker='o', label="" if i > 0 else "信頼区間")
plt.axvline(x=beta_true, color='blue', linestyle='--', label=f"真のβ: {beta_true}")
plt.title("分散既知の場合の信頼区間 (各シミュレーション)", fontsize=16)
plt.xlabel("β", fontsize=12)
plt.ylabel("シミュレーション回数", fontsize=12)
plt.legend()
plt.grid()
plt.show()カバー率:
分散既知の場合: 0.9500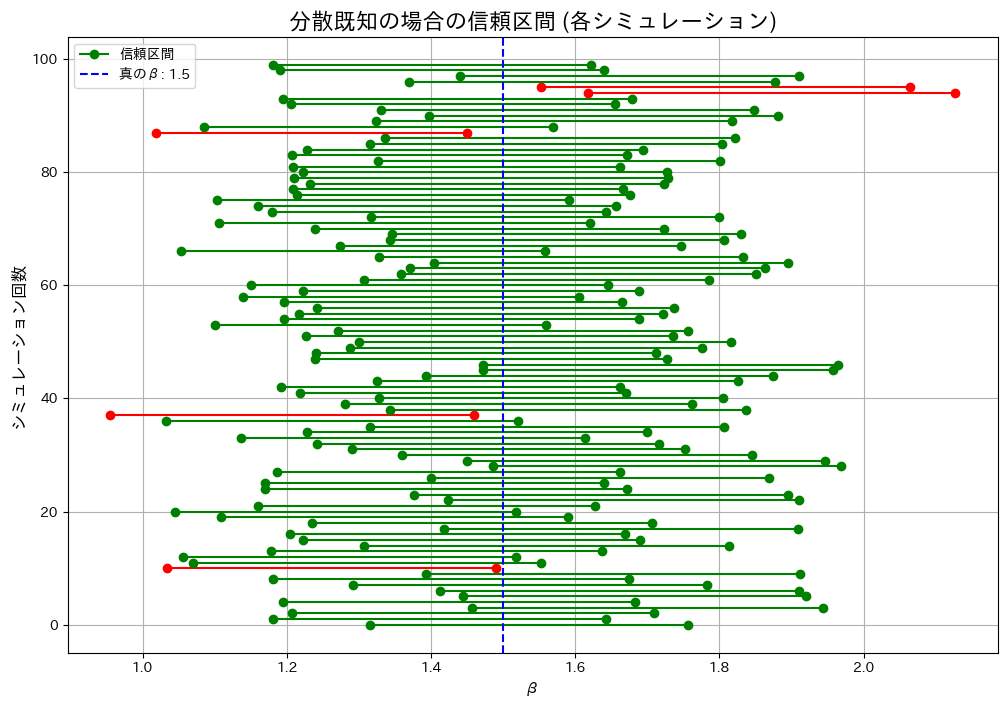
実行ごとに値は変動しましたが、カバー率は概ね理論値(1 – α = 0.95)に一致しました。
2014 Q3(1)
液体のサンプルの体積と重さから比重がβ0であるという検定を体積と重さの分散が既知の場合と未知の場合でそれぞれ方式を求めました。

コード
帰無仮説 の下で、真の値
の下で、真の値 が仮説と一致する場合(
が仮説と一致する場合( )と異なる場合(
)と異なる場合( )におけるZ検定とT検定の棄却率を比較します。
)におけるZ検定とT検定の棄却率を比較します。
# 2014 Q3(1) 2025.1.5 (2025.1.6修正)
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm, t
# Parameters
n = 30 # サンプルサイズ
beta_0 = 1.2 # 仮説のβ
sigma_X = 1.0 # Xの標準偏差
sigma_Y = 3.0 # Yの標準偏差
mu_X = 5.0 # Xの平均 (十分大きく設定)
alpha = 0.05 # 有意水準
num_simulations = 1000 # シミュレーション回数
# 分散の妥当性を確認
beta_true_values = [1.2, 1.5] # 真のβの候補
# 結果を格納するリスト
simulated_Z_dict = {}
simulated_T_dict = {}
rejection_rates_Z = {}
rejection_rates_T = {}
for beta_true in beta_true_values:
if sigma_Y**2 <= (beta_true * sigma_X)**2:
raise ValueError(f"sigma_Y^2は(beta_true * sigma_X)^2より大きくなければなりません (beta_true={beta_true})。")
# 誤差項の分散を計算
sigma_epsilon_squared = sigma_Y**2 + (beta_true * sigma_X)**2
# Z統計量とT統計量を格納するリスト
simulated_Z = []
simulated_T = []
reject_count_Z = 0
reject_count_T = 0
for _ in range(num_simulations):
# Xを正規分布で生成
X = np.random.normal(mu_X, sigma_X, n) # 平均mu_X、標準偏差sigma_X
epsilon = np.random.normal(0, np.sqrt(sigma_epsilon_squared), n) # 誤差項
# Yを生成
Y = beta_true * X + epsilon
# Z検定 (分散既知)
X_bar = np.mean(X)
Y_bar = np.mean(Y)
Z = (Y_bar - beta_0 * X_bar) / np.sqrt((sigma_Y**2 + beta_0**2 * sigma_X**2) / n)
simulated_Z.append(Z)
if abs(Z) > norm.ppf(1 - alpha / 2): # 両側検定
reject_count_Z += 1
# T検定 (分散未知)
U = Y - beta_0 * X
U_bar = np.mean(U)
S_square = np.sum((U - U_bar)**2) / (n - 1)
T = (Y_bar - beta_0 * X_bar) / np.sqrt(S_square / n)
simulated_T.append(T)
if abs(T) > t.ppf(1 - alpha / 2, df=n - 1): # 両側検定
reject_count_T += 1
simulated_Z_dict[beta_true] = simulated_Z
simulated_T_dict[beta_true] = simulated_T
rejection_rates_Z[beta_true] = reject_count_Z / num_simulations
rejection_rates_T[beta_true] = reject_count_T / num_simulations
# 棄却率を表示
print("検定条件: H0: β = 1.2")
for beta_true in beta_true_values:
print(f"真のβ = {beta_true}: Z検定の棄却率 = {rejection_rates_Z[beta_true]:.4f}, T検定の棄却率 = {rejection_rates_T[beta_true]:.4f}")
# グラフ用の範囲を定義
x_values = np.linspace(-4, 4, 1000)
# 理論的なZ分布 (帰無仮説H0: beta = beta_0)
z_pdf = norm.pdf(x_values, 0, 1)
# Z分布のプロット
plt.figure(figsize=(12, 6))
plt.plot(x_values, z_pdf, label="理論分布 (H0: 標準正規分布)", color='blue')
for beta_true, simulated_Z in simulated_Z_dict.items():
plt.hist(simulated_Z, bins=30, density=True, alpha=0.6, label=f"シミュレーション (真のβ = {beta_true})")
plt.axvline(x=norm.ppf(1 - alpha / 2), color='red', linestyle='dashed', label=f"有意水準の境界 (+{norm.ppf(1 - alpha / 2):.2f})")
plt.axvline(x=-norm.ppf(1 - alpha / 2), color='red', linestyle='dashed', label=f"有意水準の境界 (-{norm.ppf(1 - alpha / 2):.2f})")
plt.title("Z分布: 理論分布とシミュレーションの比較 (真のβの変化)", fontsize=16)
plt.xlabel("Z値", fontsize=12)
plt.ylabel("密度", fontsize=12)
plt.legend()
plt.grid()
plt.show()
# 理論的なT分布 (帰無仮説H0: beta = beta_0)
t_pdf = t.pdf(x_values, df=n - 1)
# T分布のプロット
plt.figure(figsize=(12, 6))
plt.plot(x_values, t_pdf, label=f"理論分布 (H0: t分布, 自由度={n - 1})", color='blue')
for beta_true, simulated_T in simulated_T_dict.items():
plt.hist(simulated_T, bins=30, density=True, alpha=0.6, label=f"シミュレーション (真のβ = {beta_true})")
plt.axvline(x=t.ppf(1 - alpha / 2, df=n - 1), color='red', linestyle='dashed', label=f"有意水準の境界 (+{t.ppf(1 - alpha / 2, df=n - 1):.2f})")
plt.axvline(x=-t.ppf(1 - alpha / 2, df=n - 1), color='red', linestyle='dashed', label=f"有意水準の境界 (-{t.ppf(1 - alpha / 2, df=n - 1):.2f})")
plt.title("T分布: 理論分布とシミュレーションの比較 (真のβの変化)", fontsize=16)
plt.xlabel("T値", fontsize=12)
plt.ylabel("密度", fontsize=12)
plt.legend()
plt.grid()
plt.show()検定条件: H0: β = 1.2
真のβ = 1.2: Z検定の棄却率 = 0.0390, T検定の棄却率 = 0.0400
真のβ = 1.5: Z検定の棄却率 = 0.7080, T検定の棄却率 = 0.6490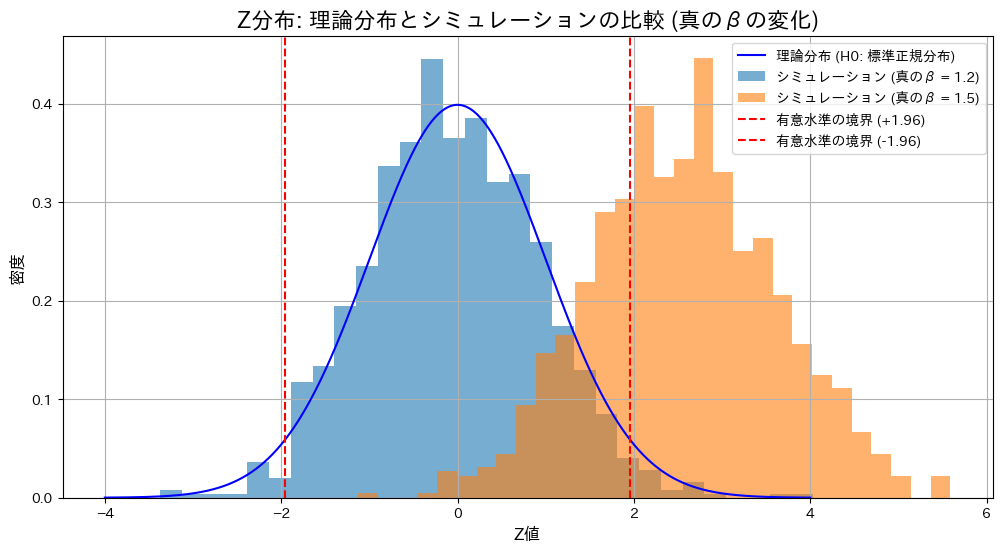
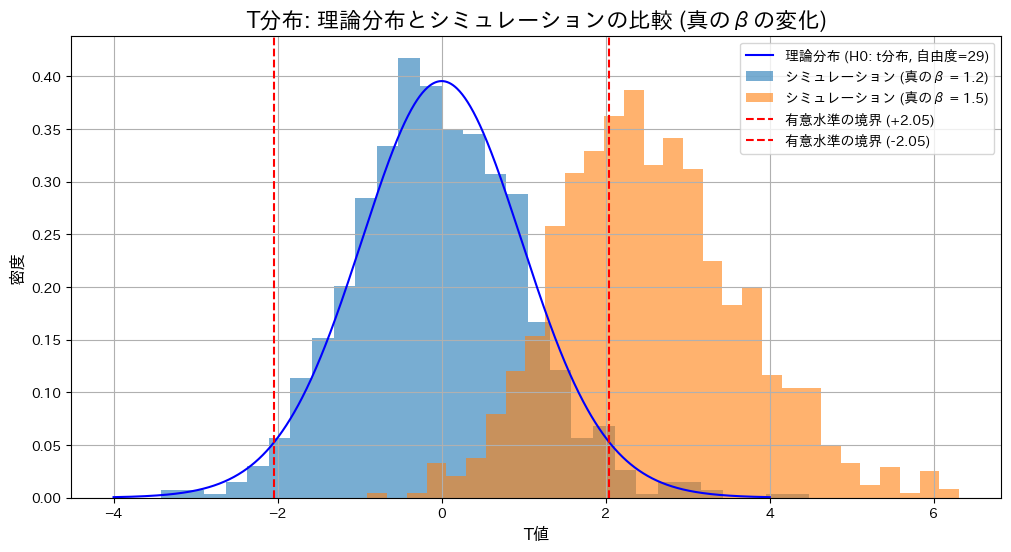
帰無仮説が正しい場合()、Z検定とT検定の棄却率は有意水準付近で期待通りの結果を示しました。一方、真の値が異なる場合()、両検定で棄却域が大幅に上昇し、帰無仮説を適切に棄却できていることが確認されました。また、真の値が異なる場合には、Z検定の棄却率がT検定をわずかに上回る結果となりました。これは、分散既知の場合のZ検定が分散未知のT検定に比べて統計量の推定が安定しているためと考えられます。
2014 Q2(5)
n個の一様分布の順序統計量の期待値を求めました。
コード
サンプルサイズn=5として、一様分布の順序統計量 をシミュレーションし、その確率密度の形状を確認するとともに、期待値がどのようになるか確かめます。
をシミュレーションし、その確率密度の形状を確認するとともに、期待値がどのようになるか確かめます。
# 2014 Q2(5) 2024.1.4
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションの設定
n_simulations = 10**6 # サンプルサイズ
n = 5 # サンプルサイズ (n個の確率変数)
# 一様分布からサンプリング
U = np.random.uniform(0, 1, (n_simulations, n))
# PDF (確率密度関数) および期待値をプロット
j_values = range(1, n + 1) # j を 1 から n まで変化させる
plt.figure(figsize=(14, 8))
colors = ['blue', 'orange', 'green', 'red', 'purple'] # 色の設定
for idx, j in enumerate(j_values):
# j 番目の順序統計量を取得
U_j = np.sort(U, axis=1)[:, j-1]
# 理論値のPDFを計算
u = np.linspace(0, 1, 1000)
pdf_theory = (n * np.math.comb(n-1, j-1)) * (u**(j-1)) * ((1-u)**(n-j))
# ヒストグラム (シミュレーション結果)
plt.hist(U_j, bins=50, density=True, alpha=0.5, label=f'j = {j} (シミュレーション)', color=colors[idx])
# 理論値のPDFをプロット
plt.plot(u, pdf_theory, linestyle='--', color=colors[idx], label=f'j = {j} (理論)')
# 理論値の期待値を直線で追加
expected_value = j / (n + 1)
plt.axvline(x=expected_value, color=colors[idx], linestyle=':', label=f'j = {j} 期待値 = {expected_value:.2f}')
# グラフ装飾
plt.title('順序統計量 U_(j) の PDF と期待値 (理論 vs シミュレーション)', fontsize=16)
plt.xlabel('値', fontsize=12)
plt.ylabel('密度', fontsize=12)
plt.legend()
plt.grid()
plt.tight_layout()
plt.show()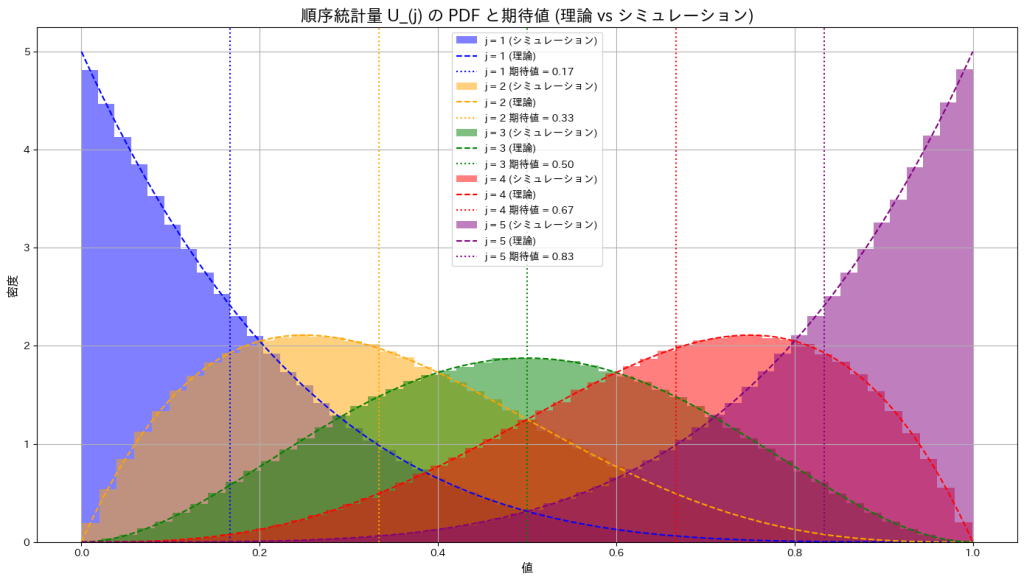
一様分布の順序統計量の確率密度は、jが小さいときには左に寄り、jが大きくなると右に寄る形状を示します。また期待値はj/(n+1)であるため0~1の範囲をn+1で均等に分割した値に一致することが確認できました。
2014 Q2(4)
n個の一様分布の順序統計量の同時分布が、前問の分布に等しい事を示しました。

コード
 と
と の個別の分布をシミュレーションし、グラフを描画してみます。
の個別の分布をシミュレーションし、グラフを描画してみます。
# 2014 Q2(4) 2025.1.3
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
n = 5 # 次元数
num_samples = 10000 # サンプル数
# (1) ガンマ分布からサンプルを生成して X_1, ..., X_(n+1) を計算
X = np.random.gamma(shape=1, scale=1, size=(num_samples, n+1)) # ガンマ分布からサンプル生成
T = X.sum(axis=1) # T = X_1 + X_2 + ... + X_(n+1)
# (2) Y_1, ..., Y_n を計算 (累積和を利用)
cumulative_sum_X = np.cumsum(X[:, :-1], axis=1) # 累積和 (X_1, X_1 + X_2, ..., X_1 + ... + X_n)
Y = cumulative_sum_X / T[:, None] # Y_i = (X_1 + ... + X_i) / T
# (3) 一様分布から順序統計量を生成
U = np.sort(np.random.uniform(0, 1, size=(num_samples, n)), axis=1) # 順序統計量 U_(1), ..., U_(n)
# (4) 個別の分布を比較
plt.figure(figsize=(12, 6))
for i in range(n):
plt.hist(Y[:, i], bins=50, alpha=0.5, density=True, label=rf"$Y_{i+1}$", histtype='step', linewidth=2)
plt.hist(U[:, i], bins=50, alpha=0.5, density=True, label=rf"$U_{{({i+1})}}$", histtype='step', linestyle='--', linewidth=2)
# グラフの装飾
plt.title("累積比率と順序統計量の個別分布の比較", fontsize=16)
plt.xlabel("値", fontsize=14)
plt.ylabel("確率密度", fontsize=14)
plt.legend(fontsize=12)
plt.grid()
plt.show()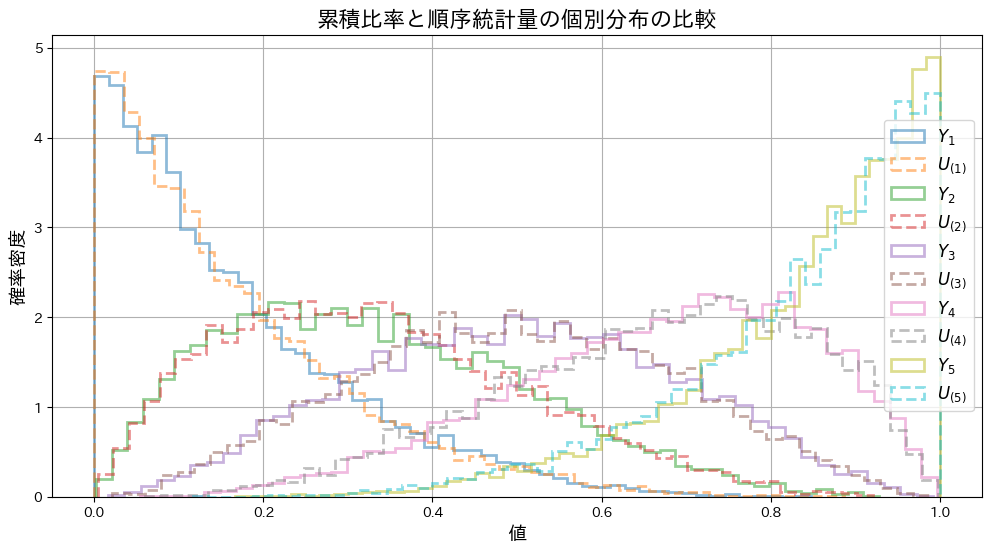
との分布の形状は重なり、一致していることが確認できました。
次に、同時確率 と
と の分布をシミュレーションし、グラフを描画してみます。
の分布をシミュレーションし、グラフを描画してみます。
# 2014 Q2(4) 2025.1.3
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
n = 5 # 次元数
num_samples = 10000 # サンプル数
# (1) ガンマ分布からサンプルを生成して X_1, ..., X_(n+1) を計算
X = np.random.gamma(shape=1, scale=1, size=(num_samples, n+1)) # ガンマ分布からサンプル生成
T = X.sum(axis=1) # T = X_1 + X_2 + ... + X_(n+1)
# (2) Y_1, ..., Y_n を計算 (累積和を利用)
cumulative_sum_X = np.cumsum(X[:, :-1], axis=1) # 累積和 (X_1, X_1 + X_2, ..., X_1 + ... + X_n)
Y = cumulative_sum_X / T[:, None] # Y_i = (X_1 + ... + X_i) / T
# (3) 一様分布から順序統計量を生成
U = np.sort(np.random.uniform(0, 1, size=(num_samples, n)), axis=1) # 順序統計量 U_(1), ..., U_(n)
# (4) 同時確率密度を計算
cumulative_density = np.prod(Y, axis=1) # 累積比率 (Y_1 * Y_2 * ... * Y_n)
order_stats_density = np.prod(U, axis=1) # 順序統計量 (U_(1) * U_(2) * ... * U_(n))
# (5) ヒストグラムを描画して比較
plt.figure(figsize=(12, 6))
# 累積比率分布の同時確率密度
plt.hist(cumulative_density, bins=50, alpha=0.5, density=True, label=r"$f_Y(Y_1, Y_2, \ldots, Y_n)$")
# 順序統計量の同時確率密度
plt.hist(order_stats_density, bins=50, alpha=0.5, density=True, label=r"$f_U(U_{(1)}, U_{(2)}, \ldots, U_{(n)})$")
# グラフの装飾
plt.title("累積比率分布と順序統計量の同時確率密度の比較", fontsize=16)
plt.xlabel("同時確率密度", fontsize=14)
plt.ylabel("頻度", fontsize=14)
plt.legend(fontsize=12)
plt.grid()
plt.show()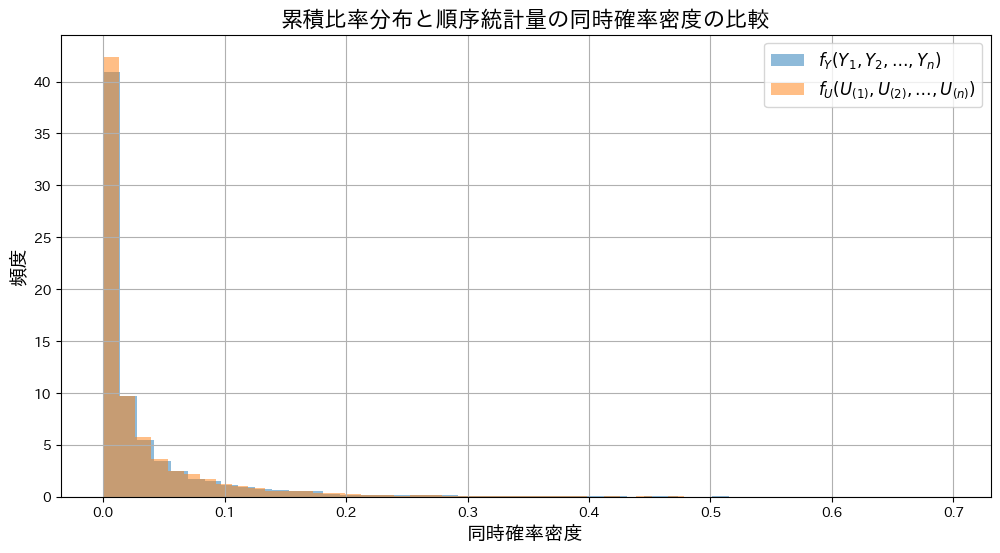
同時確率との分布の形状は重なり、一致していることが確認できました。
2014 Q2(3)
形状パラメータが1のガンマ分布は指数分布となり、その和はガンマ分布に従うことを示しました。

コード
TとYの分布についてシミュレーションを行い、それらの形状を視覚化して確認します。
# 2014 Q2(3) 2024.1.2
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
# パラメータ設定
n = 5 # n+1 個のガンマ分布の和
num_samples = 10000 # シミュレーション回数
# ガンマ分布から乱数を生成
X = gamma.rvs(a=1, scale=1, size=(num_samples, n+1)) # 各行に n+1 個のガンマ乱数を生成
T = X.sum(axis=1) # T = X_1 + X_2 + ... + X_{n+1}
# 修正: Y を累積比率で計算
cumulative_sum_X = np.cumsum(X[:, :-1], axis=1) # X_1, X_1 + X_2, ..., X_1 + ... + X_n
Y = cumulative_sum_X / T[:, None] # Y_i = (X_1 + ... + X_i) / T
# T のヒストグラムを描画
plt.figure(figsize=(10, 6))
t_values = np.linspace(0, 30, 1000)
plt.hist(T, bins=50, density=True, alpha=0.6, color="blue", label="シミュレーション (T)")
plt.plot(t_values, gamma.pdf(t_values, a=n+1, scale=1), color="red", label=f"理論分布 (Gamma({n+1}, 1))")
plt.title("$T$ の分布", fontsize=16)
plt.xlabel("$T$", fontsize=14)
plt.ylabel("確率密度", fontsize=14)
plt.legend(fontsize=12)
plt.grid()
plt.show()
# Y の確認 (サンプルの分布)
plt.figure(figsize=(10, 6))
for i in range(n):
plt.hist(Y[:, i], bins=50, density=True, alpha=0.5, label=f"$Y_{i+1}$")
plt.title("$Y$ の分布 (各比率)", fontsize=16)
plt.xlabel("$Y_i$", fontsize=14)
plt.ylabel("確率密度", fontsize=14)
plt.legend(fontsize=12)
plt.grid()
plt.show()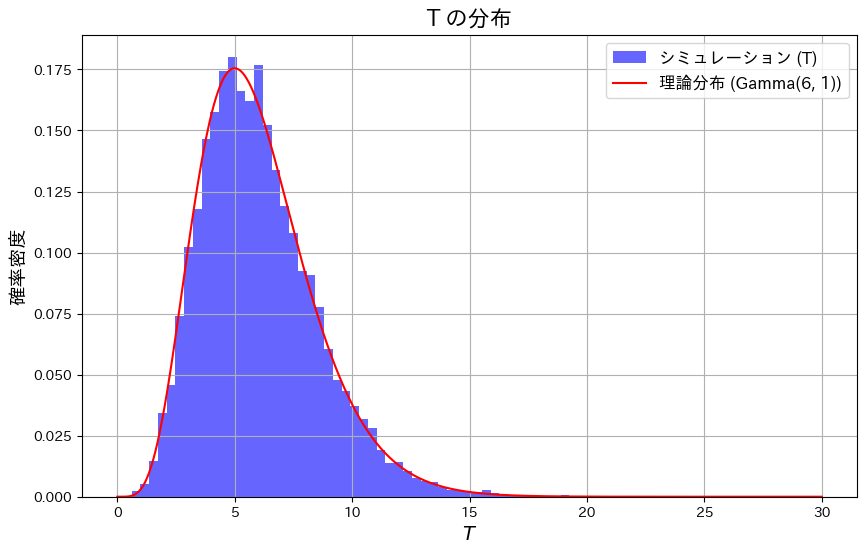
TがGa(n+1,1)のガンマ分布と一致することを確認しました。
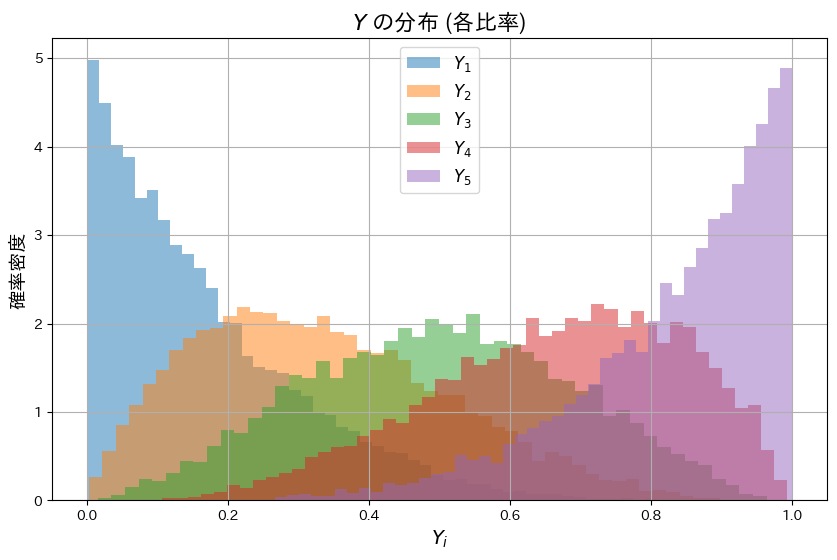
各Yiは累積比率として定義されているため、順序性(Y1<Y2<..<Yn)を持つように見えます。
次に、YiとTが独立であることを確認するため、散布図を描画し、それぞれの共分散Cov(Yi, T)を算出します。
# 2014 Q2(3) 2024.1.2
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
# パラメータ設定
n = 5 # n+1 個のガンマ分布の和
num_samples = 10000 # シミュレーション回数
# ガンマ分布から乱数を生成
X = gamma.rvs(a=1, scale=1, size=(num_samples, n+1)) # 各行に n+1 個のガンマ乱数を生成
T = X.sum(axis=1) # T = X_1 + X_2 + ... + X_{n+1}
Y = X[:, :-1] / T[:, None] # Y_i = X_i / T (最後の列を除いて正規化)
# (1) 共分散の計算
print("各 Y_i と T の共分散:")
for i in range(n):
cov = np.cov(Y[:, i], T)[0, 1] # 共分散行列から共分散を取得
print(f"Cov(Y_{i+1}, T) = {cov:.5f}")
# (2) 散布図の描画
plt.figure(figsize=(12, 8))
for i in range(n):
plt.scatter(T, Y[:, i], alpha=0.3, label=f"$Y_{i+1}$ vs $T$")
plt.title("散布図: 各 $Y_i$ と $T$ の関係", fontsize=16)
plt.xlabel("$T$", fontsize=14)
plt.ylabel("$Y_i$", fontsize=14)
plt.legend(fontsize=12)
plt.grid()
plt.show()各 Y_i と T の共分散:
Cov(Y_1, T) = 0.00426
Cov(Y_2, T) = 0.00394
Cov(Y_3, T) = -0.00261
Cov(Y_4, T) = -0.00364
Cov(Y_5, T) = -0.00399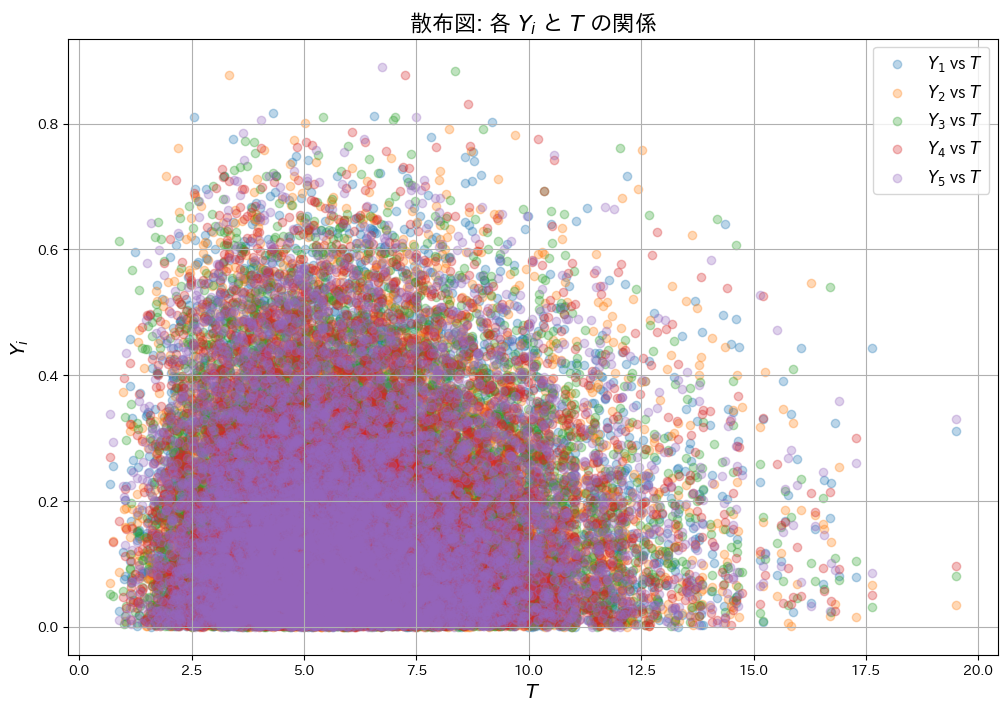
それぞれの共分散Cov(Yi, T)はほぼ0を示し、散布図からもYiとTが互いに影響を与えていないことが確認できました。
2014 Q2(2)
ガンマ分布の平均と分散をモーメント母関数から求めました。
コード
形状パラメータm、スケールパラメータ1のガンマ分布について、期待値と分散が共にmになる様子をシミュレーションで確認し、確率密度の形を視覚的に確かめます。
# 2014 Q2(2) 2025.1.1
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
# パラメータ m の値を変化させる
m_values = [1, 2, 5, 10] # ガンマ分布の形状パラメータ
colors = ["blue", "orange", "green", "red"] # 各 m に対応する色
x = np.linspace(0, 20, 1000) # x の範囲
num_samples = 10000 # シミュレーションで生成する乱数の数
# グラフの描画
plt.figure(figsize=(12, 8))
for m, color in zip(m_values, colors):
# ガンマ分布の確率密度関数 (PDF)
pdf = gamma.pdf(x, a=m, scale=1) # a=m, scale=1 に対応
# 乱数生成
random_samples = gamma.rvs(a=m, scale=1, size=num_samples)
# ヒストグラムを描画
plt.hist(random_samples, bins=50, density=True, alpha=0.5, color=color, label=f"ヒストグラム (m={m})")
# PDF を描画
plt.plot(x, pdf, color=color, linewidth=2, label=f"PDF (m={m})")
# 期待値の線
mean = m # ガンマ分布の期待値
plt.axvline(mean, color=color, linestyle="--", alpha=0.7, label=f"期待値 (m={m})")
# グラフの装飾
plt.title("ガンマ分布のPDFとシミュレーションによるヒストグラム", fontsize=16)
plt.xlabel("$x$", fontsize=14)
plt.ylabel("確率密度", fontsize=14)
plt.legend(fontsize=12)
plt.grid()
plt.show()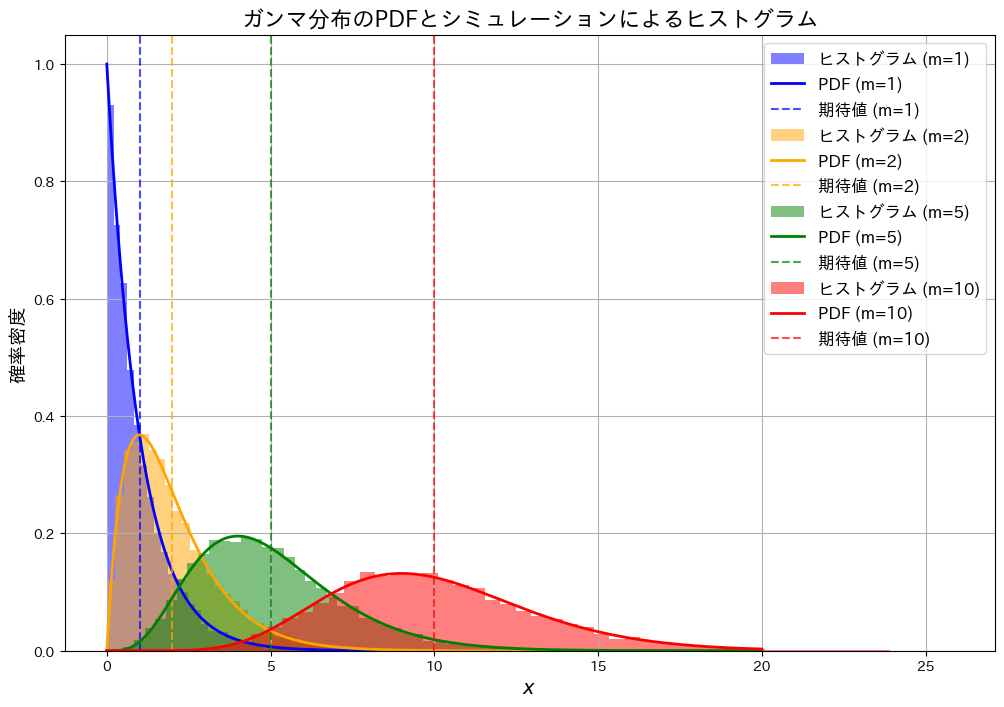
形状パラメータmと期待値が一致し、また、mが大きくなるにつれて分布が広がっている様子が確認できました。分散がmになることを直接確認していませんが、分布の広がりがmと連動していることが示唆されています。
2014 Q2(1)
ガンマ分布のモーメント母関数を求めました。

コード
求めたモーメント母関数を用いてガンマ分布の期待値と分散の理論値を求め、それをシミュレーション結果と一致するか確認します。
# 2014 Q2(1) 2024.12.31
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
import sympy as sp
from IPython.display import display
# モーメント母関数を定義 (シンボリック)
t, m = sp.symbols('t m', real=True, positive=True)
M_X_t = (1 - t)**(-m) # モーメント母関数
# 期待値 (モーメント母関数の一次微分を t=0 に代入)
M_X_prime = sp.diff(M_X_t, t)
theoretical_mean_expr = M_X_prime.subs(t, 0)
# 分散 (モーメント母関数の二次微分を t=0 に代入し、期待値の2乗を引く)
M_X_double_prime = sp.diff(M_X_prime, t)
theoretical_variance_expr = M_X_double_prime.subs(t, 0) - theoretical_mean_expr**2
# 理論値をシンボリックに表示
print("理論値の計算式:")
print("期待値 (モーメント母関数の一次微分を t=0 に代入):")
display(theoretical_mean_expr)
print("\n分散 (モーメント母関数の二次微分を t=0 に代入し、期待値の2乗を引く):")
display(theoretical_variance_expr)
# 実際のシミュレーション
m_values = [1, 2, 5, 10] # ガンマ分布の形状パラメータ
num_samples = 10000 # 乱数のサンプル数
# 理論値とシミュレーション結果を格納するリスト
theoretical_means = []
theoretical_variances = []
simulated_means = []
simulated_variances = []
for m_val in m_values:
# 理論値の計算
mean_value = float(theoretical_mean_expr.subs(m, m_val))
variance_value = float(theoretical_variance_expr.subs(m, m_val))
theoretical_means.append(mean_value)
theoretical_variances.append(variance_value)
# シミュレーション (乱数生成)
random_samples = gamma.rvs(a=m_val, scale=1, size=num_samples) # scale=1 に対応
simulated_mean = np.mean(random_samples)
simulated_variance = np.var(random_samples)
simulated_means.append(simulated_mean)
simulated_variances.append(simulated_variance)
# グラフの描画 (期待値)
plt.figure(figsize=(10, 6))
plt.plot(m_values, theoretical_means, 'o-', label="理論値 (期待値)", color="blue", linewidth=2)
plt.plot(m_values, simulated_means, 's--', label="シミュレーション (期待値)", color="orange", linewidth=2)
plt.title("期待値の比較 (理論値 vs シミュレーション)", fontsize=16)
plt.xlabel("形状パラメータ $m$", fontsize=14)
plt.ylabel("期待値", fontsize=14)
plt.legend(fontsize=12)
plt.grid()
plt.show()
# グラフの描画 (分散)
plt.figure(figsize=(10, 6))
plt.plot(m_values, theoretical_variances, 'o-', label="理論値 (分散)", color="blue", linewidth=2)
plt.plot(m_values, simulated_variances, 's--', label="シミュレーション (分散)", color="orange", linewidth=2)
plt.title("分散の比較 (理論値 vs シミュレーション)", fontsize=16)
plt.xlabel("形状パラメータ $m$", fontsize=14)
plt.ylabel("分散", fontsize=14)
plt.legend(fontsize=12)
plt.grid()
plt.show()

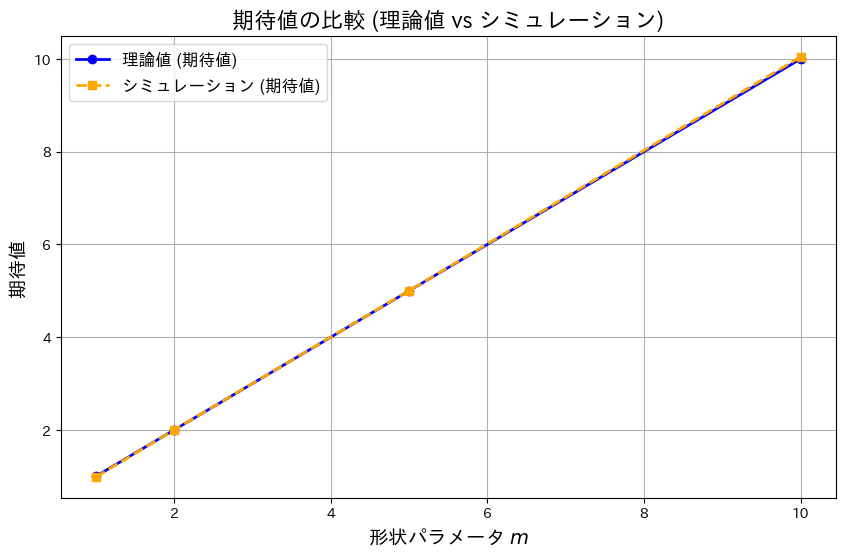
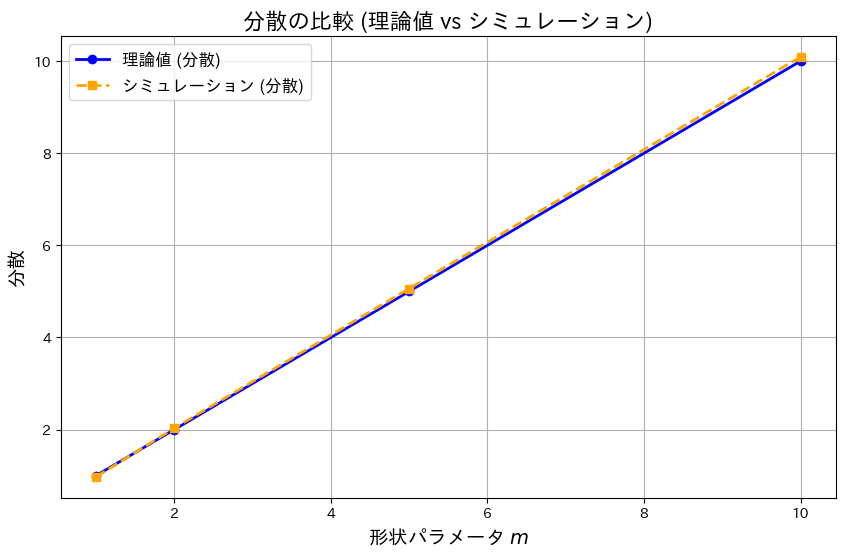
モーメント母関数を用いてガンマ分布の期待値と分散の理論値は、シミュレーション結果がよく一致しました。
2014 Q1(3)
一様分布の指数を取るn個の確率変数のうち特定の一つが最大値をとる確率を求めました。
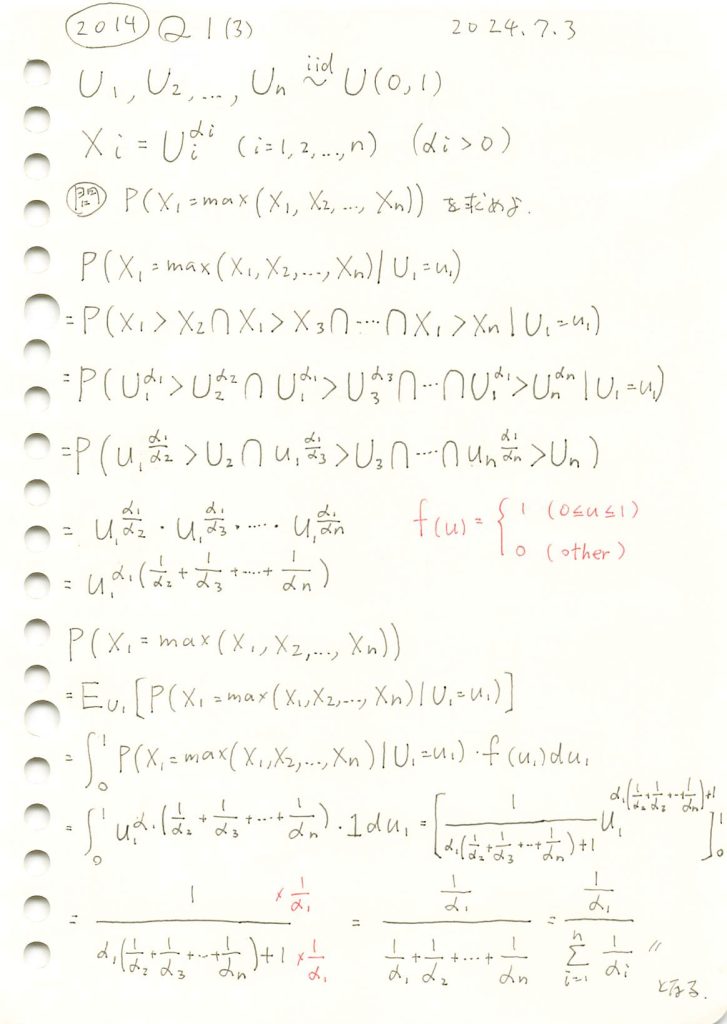
コード
与式は と考え、
と考え、 とした場合の
とした場合の をシミュレーションで計算し、理論値と比較します。
をシミュレーションで計算し、理論値と比較します。
# 2014 Q1(3) 2024.12.30
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションの設定
n_simulations = 10**6
# 確率変数の数とパラメータの設定
n = 5
alphas = [2, 3, 4, 5, 6] # α1, α2, ..., αn
# 一様分布からサンプリング
U = np.random.uniform(0, 1, (n_simulations, n))
X = U**np.array(alphas)
# 確率変数 Z を計算 (Z = X1 - max(X2, ..., Xn))
Z_diff = X[:, 0] - np.max(X[:, 1:], axis=1)
# Z の累積分布関数 (CDF) を計算
z_sorted = np.sort(Z_diff)
cdf_Z = np.arange(1, len(z_sorted) + 1) / len(z_sorted)
# Z = 0 の累積確率を計算
cumulative_prob_at_zero = cdf_Z[np.searchsorted(z_sorted, 0)]
# 理論値の計算
theoretical_prob = (1 / alphas[0]) / sum(1 / alpha for alpha in alphas)
# 結果を出力
print(f"Z = 0 における続繁確率: {cumulative_prob_at_zero:.3f}")
print(f"シミュレーション結果: P(X1 > max(X2, ..., Xn)) = {1 - cumulative_prob_at_zero:.6f}")
print(f"理論値: P(X1 > max(X2, ..., Xn)) = {theoretical_prob:.6f}")
print(f"誤差: {abs((1 - cumulative_prob_at_zero) - theoretical_prob):.6f}")
# PDF および CDF のプロット (PDF にも Z = 0 の赤い線を追加)
plt.figure(figsize=(14, 6))
# PDF
plt.subplot(1, 2, 1)
plt.hist(Z_diff, bins=100, density=True, alpha=0.7, label=r'$Z = X_1 - \max(X_2, ..., X_n)$', color='blue')
plt.axvline(x=0, color='red', linestyle='--', label=r'$Z = 0$ (境界)') # Z = 0 の赤い線を追加
plt.title('Z = X1 - max(X2, ..., Xn) の確率密度関数 (PDF)', fontsize=14)
plt.xlabel('Z', fontsize=12)
plt.ylabel('密度', fontsize=12)
plt.legend()
# CDF
plt.subplot(1, 2, 2)
plt.plot(z_sorted, cdf_Z, label=r'$Z = X_1 - \max(X_2, ..., X_n)$', color='blue')
plt.axvline(x=0, color='red', linestyle='--', label=r'$Z = 0$ (境界)') # Z = 0 の赤い線
plt.text(0.05, cumulative_prob_at_zero, f'{cumulative_prob_at_zero:.3f}', color='red', fontsize=12)
plt.title('Z = X1 - max(X2, ..., Xn) の続繁分布関数 (CDF)', fontsize=14)
plt.xlabel('Z', fontsize=12)
plt.ylabel('続繁確率', fontsize=12)
plt.legend()
plt.tight_layout()
plt.show()Z = 0 における続繁確率: 0.655
シミュレーション結果: P(X1 > max(X2, ..., Xn)) = 0.345030
理論値: P(X1 > max(X2, ..., Xn)) = 0.344828
誤差: 0.000202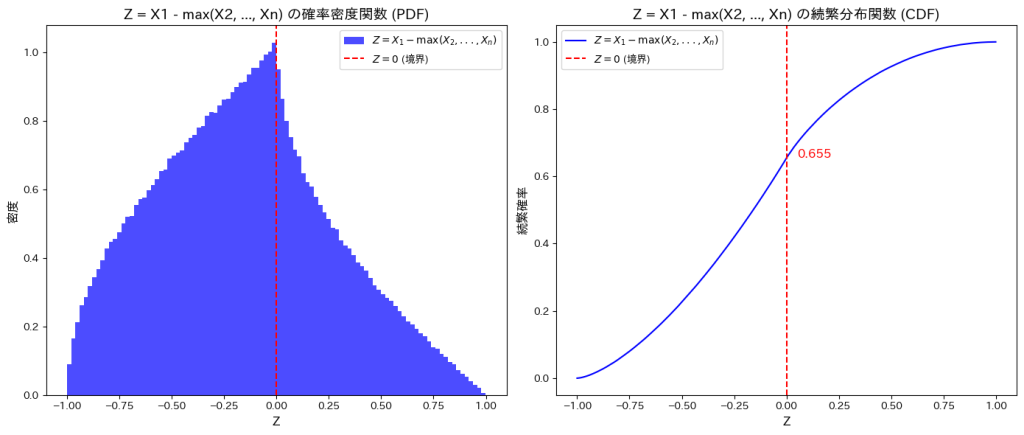
はシミュレーションの結果、理論値と一致しました。