ホーム » 復習3周目 (ページ 3)
「復習3周目」カテゴリーアーカイブ
2014 Q1(3)
一様分布の指数を取るn個の確率変数のうち特定の一つが最大値をとる確率を求めました。
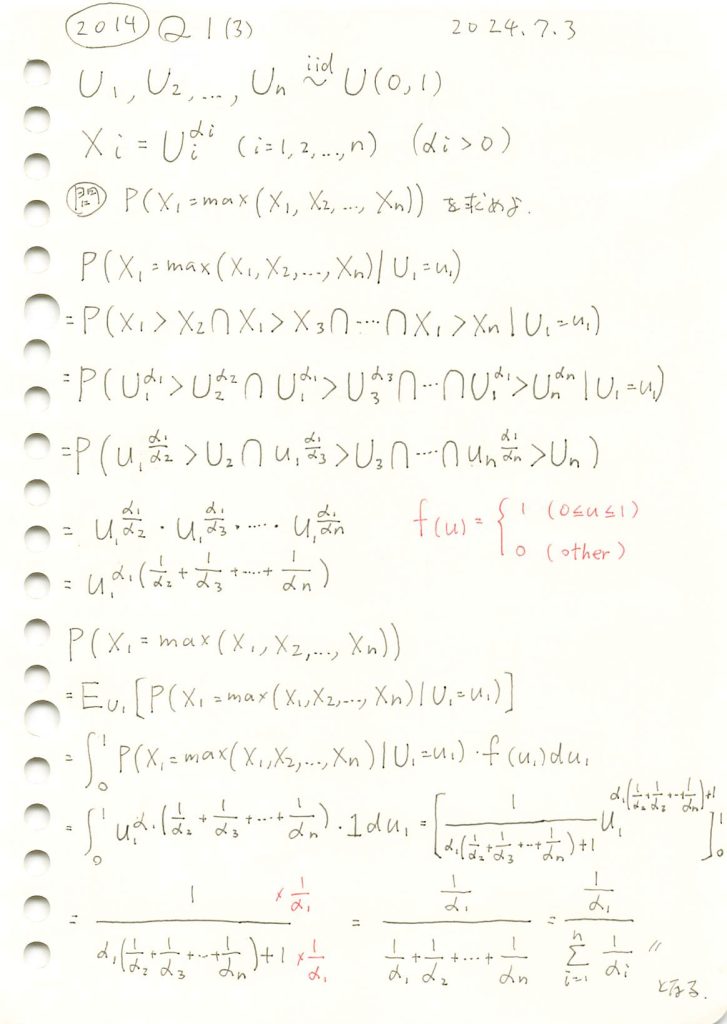
コード
与式は と考え、
と考え、 とした場合の
とした場合の をシミュレーションで計算し、理論値と比較します。
をシミュレーションで計算し、理論値と比較します。
# 2014 Q1(3) 2024.12.30
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションの設定
n_simulations = 10**6
# 確率変数の数とパラメータの設定
n = 5
alphas = [2, 3, 4, 5, 6] # α1, α2, ..., αn
# 一様分布からサンプリング
U = np.random.uniform(0, 1, (n_simulations, n))
X = U**np.array(alphas)
# 確率変数 Z を計算 (Z = X1 - max(X2, ..., Xn))
Z_diff = X[:, 0] - np.max(X[:, 1:], axis=1)
# Z の累積分布関数 (CDF) を計算
z_sorted = np.sort(Z_diff)
cdf_Z = np.arange(1, len(z_sorted) + 1) / len(z_sorted)
# Z = 0 の累積確率を計算
cumulative_prob_at_zero = cdf_Z[np.searchsorted(z_sorted, 0)]
# 理論値の計算
theoretical_prob = (1 / alphas[0]) / sum(1 / alpha for alpha in alphas)
# 結果を出力
print(f"Z = 0 における続繁確率: {cumulative_prob_at_zero:.3f}")
print(f"シミュレーション結果: P(X1 > max(X2, ..., Xn)) = {1 - cumulative_prob_at_zero:.6f}")
print(f"理論値: P(X1 > max(X2, ..., Xn)) = {theoretical_prob:.6f}")
print(f"誤差: {abs((1 - cumulative_prob_at_zero) - theoretical_prob):.6f}")
# PDF および CDF のプロット (PDF にも Z = 0 の赤い線を追加)
plt.figure(figsize=(14, 6))
# PDF
plt.subplot(1, 2, 1)
plt.hist(Z_diff, bins=100, density=True, alpha=0.7, label=r'$Z = X_1 - \max(X_2, ..., X_n)$', color='blue')
plt.axvline(x=0, color='red', linestyle='--', label=r'$Z = 0$ (境界)') # Z = 0 の赤い線を追加
plt.title('Z = X1 - max(X2, ..., Xn) の確率密度関数 (PDF)', fontsize=14)
plt.xlabel('Z', fontsize=12)
plt.ylabel('密度', fontsize=12)
plt.legend()
# CDF
plt.subplot(1, 2, 2)
plt.plot(z_sorted, cdf_Z, label=r'$Z = X_1 - \max(X_2, ..., X_n)$', color='blue')
plt.axvline(x=0, color='red', linestyle='--', label=r'$Z = 0$ (境界)') # Z = 0 の赤い線
plt.text(0.05, cumulative_prob_at_zero, f'{cumulative_prob_at_zero:.3f}', color='red', fontsize=12)
plt.title('Z = X1 - max(X2, ..., Xn) の続繁分布関数 (CDF)', fontsize=14)
plt.xlabel('Z', fontsize=12)
plt.ylabel('続繁確率', fontsize=12)
plt.legend()
plt.tight_layout()
plt.show()Z = 0 における続繁確率: 0.655
シミュレーション結果: P(X1 > max(X2, ..., Xn)) = 0.345030
理論値: P(X1 > max(X2, ..., Xn)) = 0.344828
誤差: 0.000202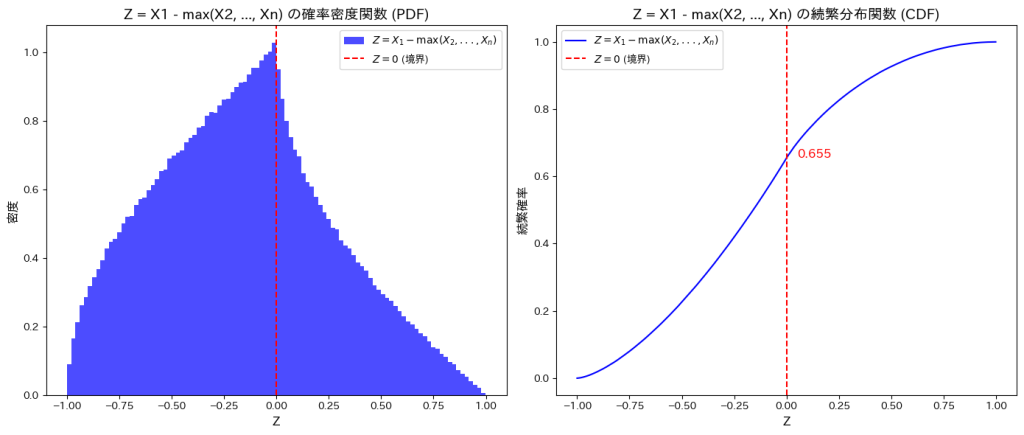
はシミュレーションの結果、理論値と一致しました。
2014 Q1(2)
一様分布の指数を取る三つの確率変数のうち特定の一つが最大値をとる確率を求めました。

コード
与式は と考え、
と考え、 とした場合の
とした場合の をシミュレーションで計算し、理論値と比較します。
をシミュレーションで計算し、理論値と比較します。
# 2014 Q1(2) 2024.12.29
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションの設定
n_simulations = 10**6
# 一様分布からサンプリング
U = np.random.uniform(0, 1, n_simulations)
V = np.random.uniform(0, 1, n_simulations)
W = np.random.uniform(0, 1, n_simulations)
# パラメータの設定
alpha, beta, gamma = 2, 3, 4
# X, Y, Z の計算
X = U**alpha
Y = V**beta
Z = W**gamma
# 確率変数 Z を計算 (例: Z = X - max(Y, Z))
Z_diff = X - np.maximum(Y, Z)
# Z の累積分布関数 (CDF) を計算
z_sorted = np.sort(Z_diff)
cdf_Z = np.arange(1, len(z_sorted) + 1) / len(z_sorted)
# Z = 0 の累積確率を計算
cumulative_prob_at_zero = cdf_Z[np.searchsorted(z_sorted, 0)]
# 理論値の計算
theoretical_prob = (1 / alpha) / (1 / alpha + 1 / beta + 1 / gamma)
# 結果を出力
print(f"Z = 0 における累積確率: {cumulative_prob_at_zero:.3f}")
print(f"シミュレーション結果: P(X > max(Y, Z)) = {1 - cumulative_prob_at_zero:.6f}")
print(f"理論値: P(X > max(Y, Z)) = {theoretical_prob:.6f}")
print(f"誤差: {abs((1 - cumulative_prob_at_zero) - theoretical_prob):.6f}")
# PDF および CDF のプロット (PDF にも Z = 0 の赤い線を追加)
plt.figure(figsize=(14, 6))
# PDF
plt.subplot(1, 2, 1)
plt.hist(Z_diff, bins=100, density=True, alpha=0.7, label=r'$Z = X - \max(Y, Z)$', color='blue')
plt.axvline(x=0, color='red', linestyle='--', label=r'$Z = 0$ (境界)') # Z = 0 の赤い線を追加
plt.title('Z = X - max(Y, Z) の確率密度関数 (PDF)', fontsize=14)
plt.xlabel('Z', fontsize=12)
plt.ylabel('密度', fontsize=12)
plt.legend()
# CDF
plt.subplot(1, 2, 2)
plt.plot(z_sorted, cdf_Z, label=r'$Z = X - \max(Y, Z)$', color='blue')
plt.axvline(x=0, color='red', linestyle='--', label=r'$Z = 0$ (境界)') # Z = 0 の赤い線
plt.text(0.05, cumulative_prob_at_zero, f'{cumulative_prob_at_zero:.3f}', color='red', fontsize=12)
plt.title('Z = X - max(Y, Z) の累積分布関数 (CDF)', fontsize=14)
plt.xlabel('Z', fontsize=12)
plt.ylabel('累積確率', fontsize=12)
plt.legend()
plt.tight_layout()
plt.show()Z = 0 における累積確率: 0.538
シミュレーション結果: P(X > max(Y, Z)) = 0.462111
理論値: P(X > max(Y, Z)) = 0.461538
誤差: 0.000573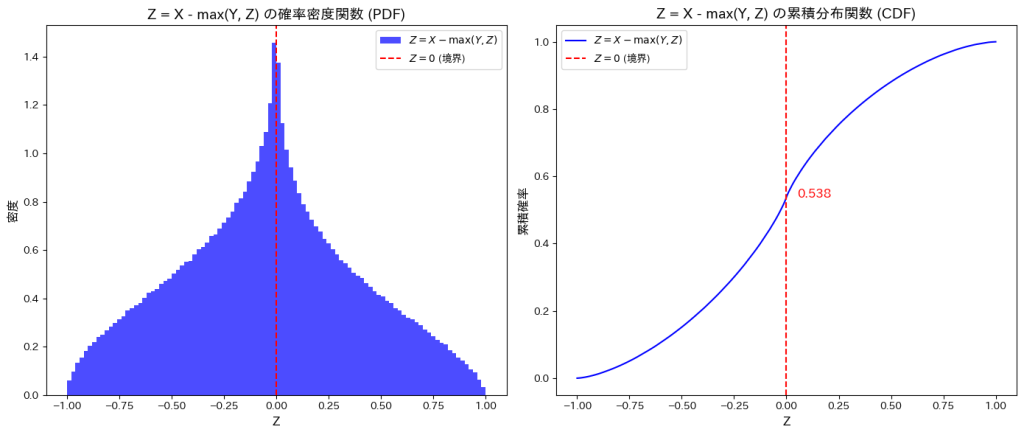
はシミュレーションの結果、理論値と一致しました。
2014 Q1(1)
一様分布の指数を取る二つの確率変数の大小が決まっている場合の確率を条件付確率の期待値を取ることで求めました。

コード
XとYの頻度分布を3Dプロットで可視化してみます。
# 2014 Q1(1) 2024.12.28
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# シミュレーションの設定
n_simulations = 10**5 # サンプルサイズ
# 一様分布からサンプリング
U = np.random.uniform(0, 1, n_simulations)
V = np.random.uniform(0, 1, n_simulations)
# X, Y の計算
X = U**2
Y = V**3
# 3Dプロット
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# 2次元ヒストグラムを計算
hist, xedges, yedges = np.histogram2d(X, Y, bins=50, density=True)
# 座標軸を作成
xpos, ypos = np.meshgrid(xedges[:-1], yedges[:-1], indexing="ij")
xpos = xpos.ravel()
ypos = ypos.ravel()
zpos = np.zeros_like(xpos)
# 棒の高さ
dx = dy = 0.02
dz = hist.ravel()
# 色分け: X > Y (緑), X = Y (黄色), X < Y (青)
tolerance = 0.01 # 許容範囲を指定して X = Y の近似を表現
colors = np.where(
np.abs(xpos - ypos) < tolerance, 'yellow',
np.where(xpos > ypos, 'green', 'blue')
)
# 3Dバーを描画
ax.bar3d(xpos, ypos, zpos, dx, dy, dz, zsort='average', alpha=0.7, color=colors)
# ラベルとタイトル
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('頻度', labelpad=-10) # ラベルの位置を調整
#ax.set_title(r'$X > Y$ (緑), $X = Y$ (黄色), $X < Y$ (青)', fontsize=14)
#ax.set_title(r'$X$ と $Y$ の出現頻度', fontsize=14)
ax.set_title(r'$X$ と $Y$ の出現頻度(組)', fontsize=14)
# 凡例
legend_handles = [
plt.Line2D([0], [0], color='green', lw=4, label=r'$X > Y$ (緑)'),
plt.Line2D([0], [0], color='yellow', lw=4, label=r'$X = Y$ (黄色)'),
plt.Line2D([0], [0], color='blue', lw=4, label=r'$X < Y$ (青)')
]
ax.legend(handles=legend_handles, loc='upper left', bbox_to_anchor=(1.05, 1), fontsize=10)
# カメラビュー
ax.view_init(elev=30, azim=45)
plt.tight_layout()
plt.show()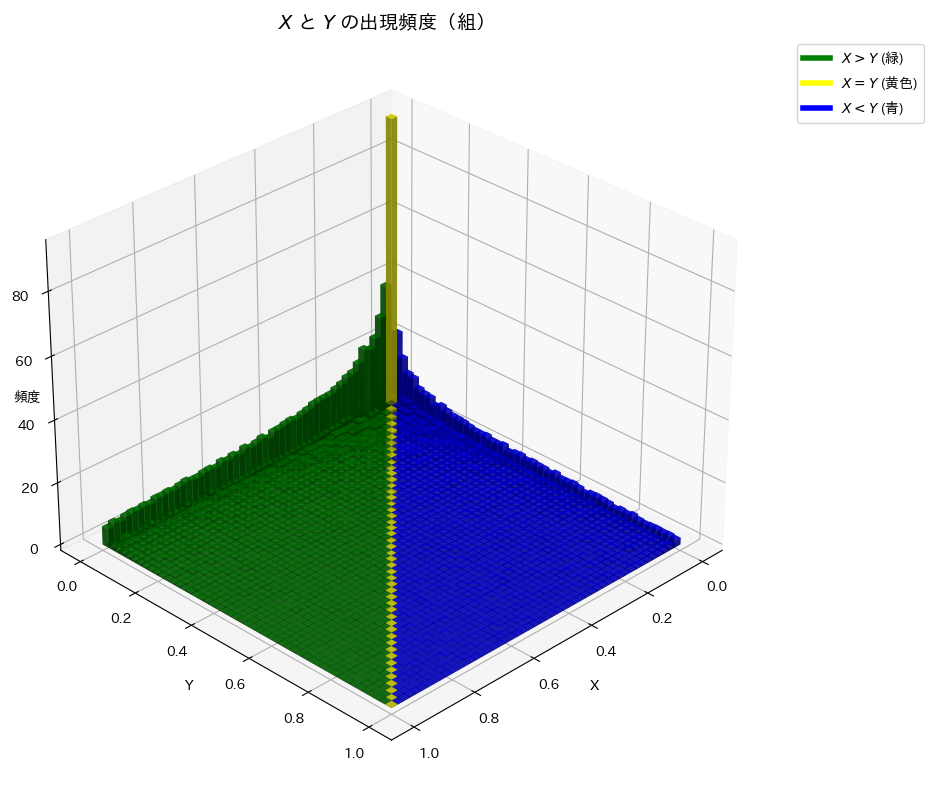
X>Yの領域は、X<Yの領域と比べて出現頻度が高いようです。
次に、XとYの大小関係を確認するために確率変数Z=X-Yを同に導入し、その確率密度と累積分布をシミュレーションにより求め、P(X>Y)を計算してみます。
# 2014 Q1(1) 2024.12.28
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションの設定
np.random.seed(42)
n_simulations = 10**6
# 一様分布からサンプリング
U = np.random.uniform(0, 1, n_simulations)
V = np.random.uniform(0, 1, n_simulations)
# X, Y の計算
X = U**2
Y = V**3
# Z = X - Y を計算
Z = X - Y
# Z の累積分布関数 (CDF) を計算
z_sorted = np.sort(Z)
cdf_Z = np.arange(1, len(z_sorted) + 1) / len(z_sorted)
# Z = 0 の累積確率を計算
cumulative_prob_at_zero = cdf_Z[np.searchsorted(z_sorted, 0)]
# 結果を出力
print(f"Z = 0 における累積確率: {cumulative_prob_at_zero:.3f}")
print(f"P(X > Y) = {1 - cumulative_prob_at_zero:.3f}")
# PDF および CDF のプロット (PDF にも Z = 0 の赤い線を追加)
plt.figure(figsize=(14, 6))
# PDF
plt.subplot(1, 2, 1)
plt.hist(Z, bins=100, density=True, alpha=0.7, label=r'$Z = X - Y$', color='blue')
plt.axvline(x=0, color='red', linestyle='--', label=r'$Z = 0$ (境界)') # Z = 0 の赤い線を追加
plt.title('Z = X - Y の確率密度関数 (PDF)', fontsize=14)
plt.xlabel('Z', fontsize=12)
plt.ylabel('密度', fontsize=12)
plt.legend()
# CDF
plt.subplot(1, 2, 2)
plt.plot(z_sorted, cdf_Z, label=r'$Z = X - Y$', color='blue')
plt.axvline(x=0, color='red', linestyle='--', label=r'$Z = 0$ (境界)') # Z = 0 の赤い線
plt.text(0.05, cumulative_prob_at_zero, f'{cumulative_prob_at_zero:.3f}', color='red', fontsize=12)
plt.title('Z = X - Y の累積分布関数 (CDF)', fontsize=14)
plt.xlabel('Z', fontsize=12)
plt.ylabel('累積確率', fontsize=12)
plt.legend()
plt.tight_layout()
plt.show()Z = 0 における累積確率: 0.399
P(X > Y) = 0.601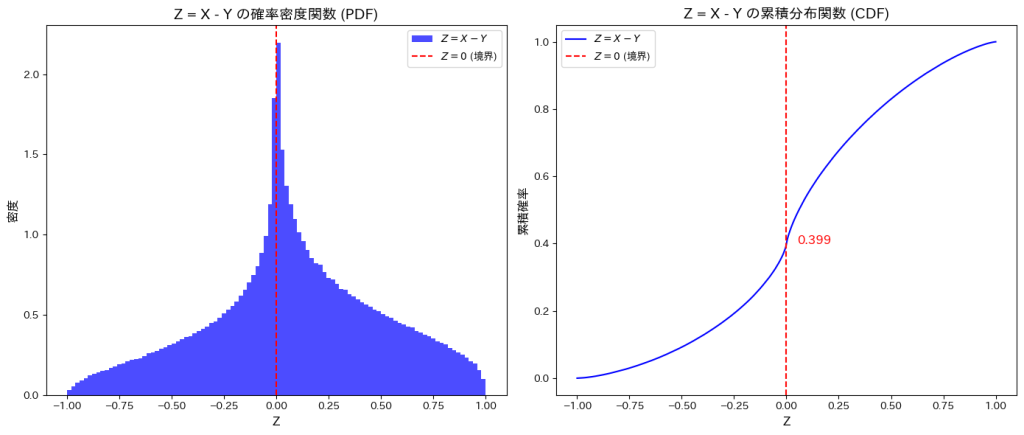
シミュレーションにより求めたP(X>Y)は、理論値と一致することが確認できました。
2015 Q5(6)
二変量正規分布の条件付期待値を求め、二値化された条件付確率変数との相関係数を求めました。
コード
条件付期待値![E[Y \mid X \geq 0]](https://statistics.blue/wp-content/ql-cache/quicklatex.com-9ee608e55cf5ae59c04b098219866f08_l3.png "Rendered by QuickLaTeX.com") と相関係数
と相関係数  が、理論値
が、理論値 に一致することをシミュレーションで確認します。
に一致することをシミュレーションで確認します。
# 2015 Q5(6) 2024.12.27
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
rho = 0.8 # 相関係数
num_samples = 100000 # サンプル数
# 2次元正規分布の生成
mean = [0, 0] # 平均
cov = [[1, rho], [rho, 1]] # 共分散行列
X, Y = np.random.multivariate_normal(mean, cov, num_samples).T
# 条件 X >= 0 の Y の期待値 (シミュレーション)
Y_given_X_positive = Y[X >= 0]
simulated_mean = np.mean(Y_given_X_positive)
# 理論値の計算
theoretical_mean = np.sqrt(2 / np.pi) * rho
# T の定義 (a = 1 と仮定)
a = 1
T = np.where(X >= 0, a, -a)
# 相関係数の計算 (T と Y)
simulated_corr = np.corrcoef(T, Y)[0, 1]
theoretical_corr = np.sqrt(2 / np.pi) * rho
# 結果の表示
print("シミュレーション結果:")
print(f"E[Y | X >= 0] (シミュレーション): {simulated_mean:.4f}")
print(f"E[Y | X >= 0] (理論値): {theoretical_mean:.4f}")
print(f"相関係数 Corr(T, Y) (シミュレーション): {simulated_corr:.4f}")
print(f"相関係数 Corr(T, Y) (理論値): {theoretical_corr:.4f}")
# ヒストグラムの描画
plt.figure(figsize=(10, 6))
plt.hist(Y_given_X_positive, bins=50, density=True, color='lightblue', edgecolor='black', alpha=0.7, label="Y | X >= 0 の分布")
plt.axvline(simulated_mean, color="green", linestyle="--", label=f"シミュレーション期待値: {simulated_mean:.4f}")
plt.axvline(theoretical_mean, color="red", linestyle="--", label=f"理論期待値: {theoretical_mean:.4f}")
# グラフの設定
plt.title("条件付き期待値 E[Y | X >= 0] の確認", fontsize=14)
plt.xlabel("Y の値", fontsize=12)
plt.ylabel("確率密度", fontsize=12)
plt.legend(fontsize=10)
plt.grid(True)
plt.tight_layout()
plt.show()シミュレーション結果:
E[Y | X >= 0] (シミュレーション): 0.6386
E[Y | X >= 0] (理論値): 0.6383
相関係数 Corr(T, Y) (シミュレーション): 0.6384
相関係数 Corr(T, Y) (理論値): 0.6383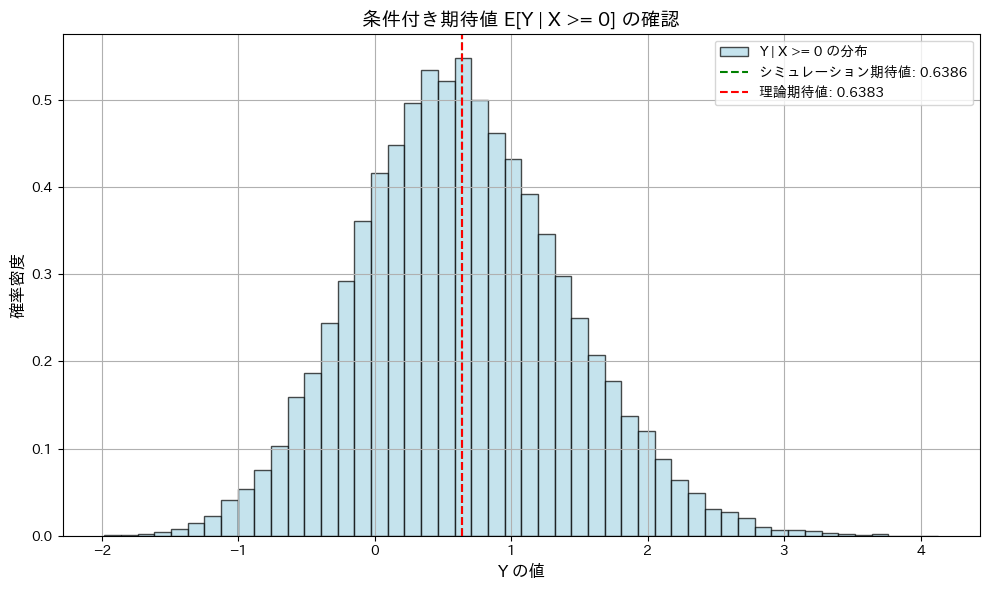
条件付期待値と相関係数 が、共に理論値に一致することが確認されました。
次に、相関係数 がaの値に依らず一定であることを確認します。また、いくつかの相関係数 を変化させて確認します。
を変化させて確認します。
# 2015 Q5(6) 2024.12.27
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
rho_values = [0.2, 0.5, 0.8] # いくつかの相関係数 ρ
a_values = np.linspace(0.1, 5, 50) # a の範囲
num_samples = 100000 # サンプル数
# 結果を格納する辞書
results = {rho: [] for rho in rho_values}
# シミュレーション
for rho in rho_values:
mean = [0, 0] # 平均
cov = [[1, rho], [rho, 1]] # 共分散行列
for a in a_values:
# 2次元正規分布の生成
X, Y = np.random.multivariate_normal(mean, cov, num_samples).T
# T の定義
T = np.where(X >= 0, a, -a)
# 相関係数の計算
simulated_corr = np.corrcoef(T, Y)[0, 1]
results[rho].append(simulated_corr)
# グラフの描画
plt.figure(figsize=(10, 6))
for rho, corr_values in results.items():
plt.plot(a_values, corr_values, label=f"ρ = {rho}")
# 理論値の計算
theoretical_corr = np.sqrt(2 / np.pi) * np.array(rho_values)
# グラフの設定
plt.title("T と Y の相関係数 (Corr(T, Y)) vs a", fontsize=14)
plt.xlabel("a の値", fontsize=12)
plt.ylabel("相関係数 Corr(T, Y)", fontsize=12)
plt.axhline(y=0, color="black", linestyle="--", linewidth=0.8) # 基準線
plt.legend(fontsize=10)
plt.grid(True)
plt.tight_layout()
plt.show()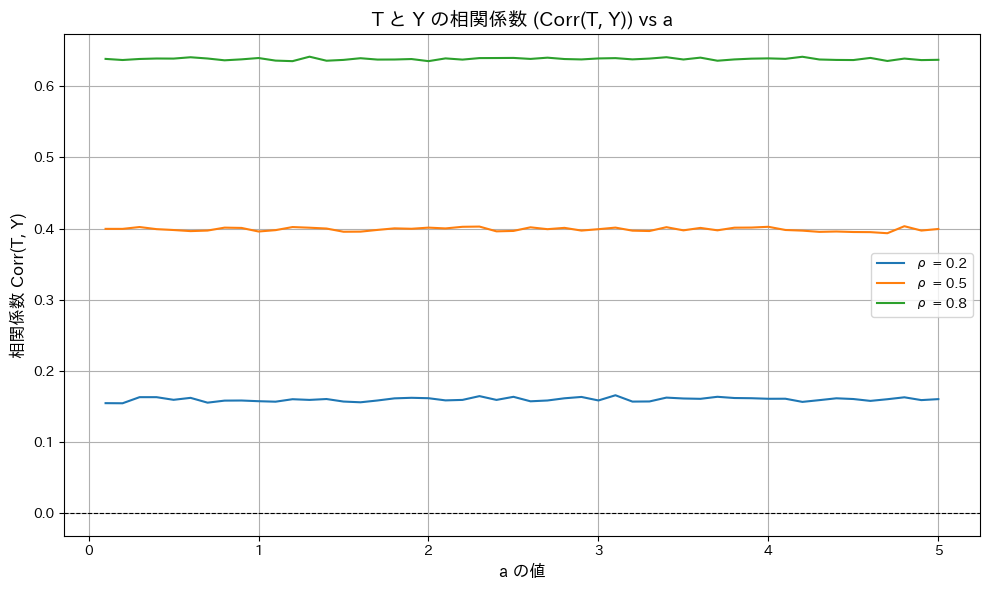
相関係数 がaの値に依らず一定であることが確認されました。
2015 Q5(5)
標準正規分布に従う確率変数を条件に二値化する確率変数の平均と分散を求めました。
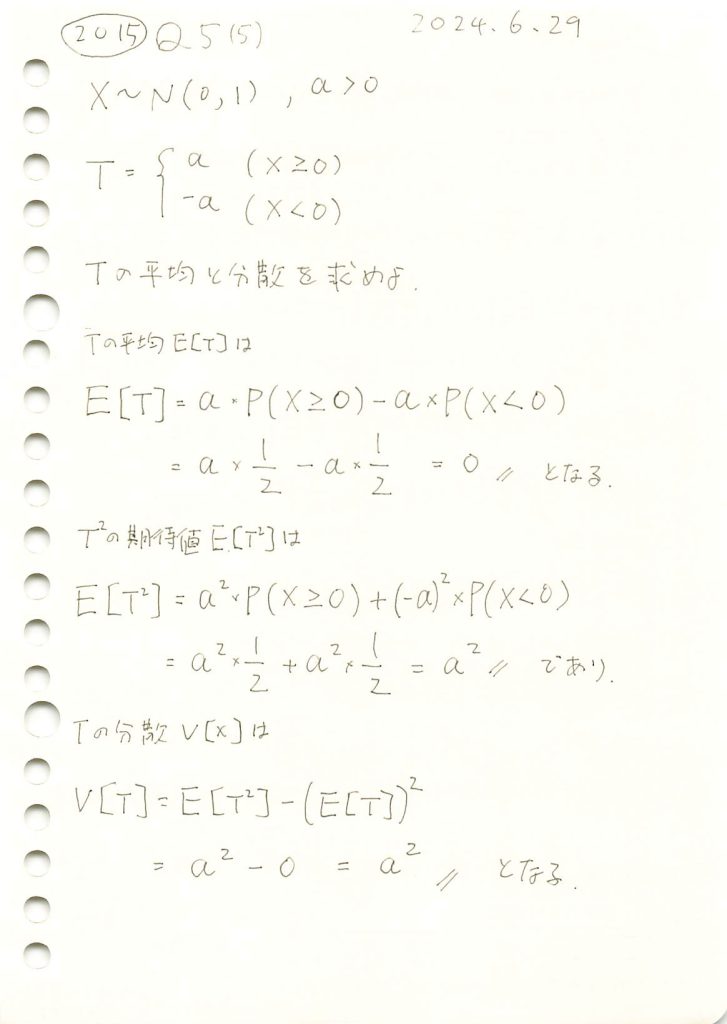
コード
Tの平均と分散をシミュレーションで計算し、それらが理論値と一致するか確認をします。
# 2015 Q5(5) 2024.12.26
import numpy as np
# パラメータ
a = 2 # a の値
num_samples = 100000 # サンプル数
# 正規分布から X を生成
X = np.random.normal(0, 1, num_samples)
# T を定義
T = np.where(X >= 0, a, -a)
# 平均と分散を計算
T_mean = np.mean(T)
T_variance = np.var(T)
# 結果を出力
print("シミュレーション結果:")
print("T の平均 (E[T]):", T_mean)
print("T の分散 (Var(T)):", T_variance)
# 理論値
print("\n理論値:")
print("T の平均 (E[T]):", 0)
print("T の分散 (Var(T)):", a**2)シミュレーション結果:
T の平均 (E[T]): 0.00388
T の分散 (Var(T)): 3.999984945600001
理論値:
T の平均 (E[T]): 0
T の分散 (Var(T)): 4シミュレーションで計算したTの平均と分散は理論値と一致しました。
2015 Q5(4)
標準正規分布に従う確率変数の、右半分の条件付期待値を求めました。

コード
標準正規分布に従う確率変数 Zについて、条件付き期待値![E[Z \mid Z \geq 0] = \sqrt{\frac{2}{\pi}}](https://statistics.blue/wp-content/ql-cache/quicklatex.com-e0958d2099413c45848a20cd739c6eab_l3.png "Rendered by QuickLaTeX.com") になることをシミュレーションで確認をします。
になることをシミュレーションで確認をします。
# 2015 Q5(4) 2024.12.25
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# シミュレーションパラメータ
num_samples = 100000 # サンプル数
# 標準正規分布からサンプルを生成
samples = np.random.normal(0, 1, num_samples)
# 条件 Z >= 0 のサンプルを抽出
samples_positive = samples[samples >= 0]
# 条件付き期待値のシミュレーション値
simulated_mean = np.mean(samples_positive)
# 理論値
theoretical_mean = np.sqrt(2 / np.pi)
# ヒストグラムの準備
x = np.linspace(-3, 3, 500) # x軸の範囲
pdf = norm.pdf(x) # 標準正規分布のPDF
# グラフの描画
plt.figure(figsize=(10, 6))
# 正規分布のPDF
plt.plot(x, pdf, label="標準正規分布のPDF", color="blue", linewidth=2)
# 条件 Z >= 0 のサンプルのヒストグラム
plt.hist(samples_positive, bins=50, density=True, alpha=0.6, color="orange", label="条件 Z ≧ 0 のシミュレーション")
# 結果の表示
plt.axvline(simulated_mean, color="green", linestyle="--", label=f"シミュレーション期待値: {simulated_mean:.4f}")
plt.axvline(theoretical_mean, color="red", linestyle="--", label=f"理論期待値: {theoretical_mean:.4f}")
# グラフの設定
plt.title("条件付き期待値の確認 (Z ≧ 0)", fontsize=14)
plt.xlabel("Z の値", fontsize=12)
plt.ylabel("確率密度", fontsize=12)
plt.legend(fontsize=10)
plt.grid(True)
# グラフを表示
plt.tight_layout()
plt.show()
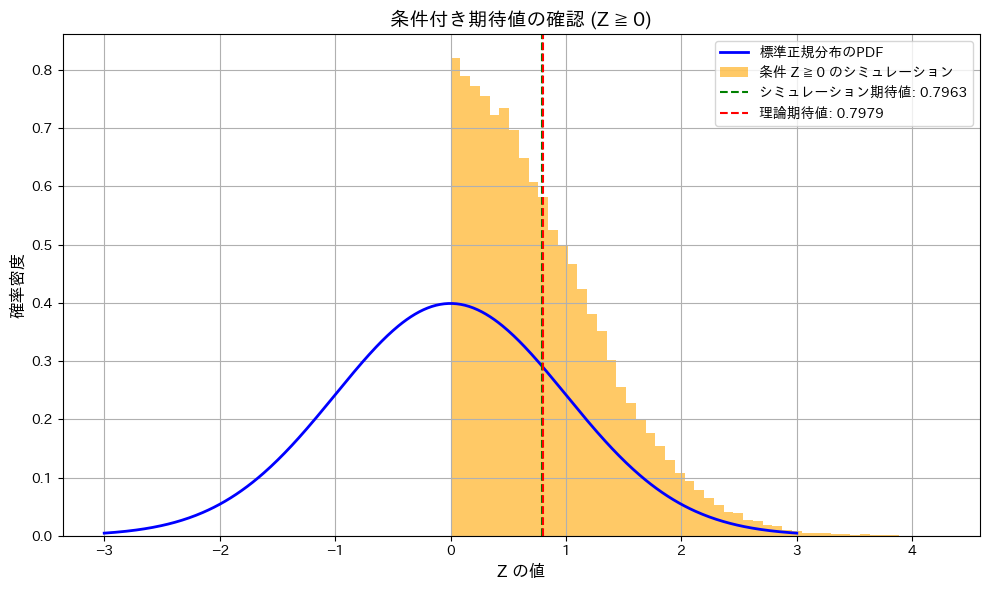
条件付き期待値であることが確認されました。
2015 Q5(3)
2つに分けられた組標本のそれぞれ平均と不偏分散の具体的な値から、全体の平均と不偏分散および相関係数を計算しました。
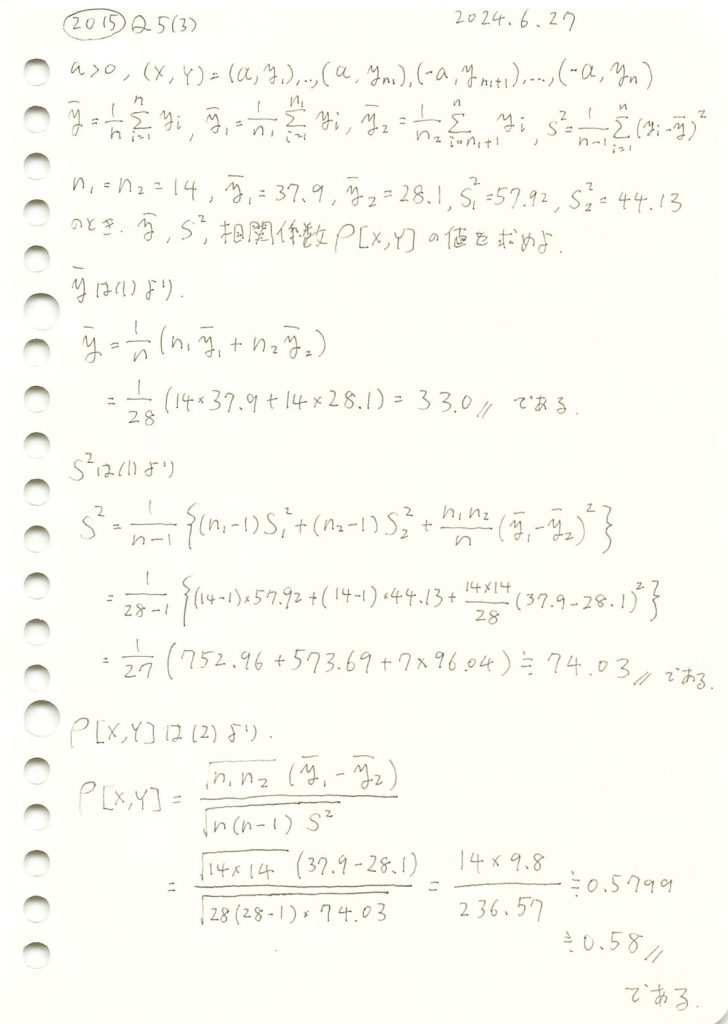
コード
与えられたデータを基に、全体の平均と分散を計算し、相関係数を求めます。
# 2015 Q5(3) 2024.12.24
# 与えられたデータ
n1 = n2 = 14
n = n1 + n2
y1_bar = 37.9
y2_bar = 28.1
s1_sq = 57.92
s2_sq = 44.13
# 全体の平均
y_bar = (n1 * y1_bar + n2 * y2_bar) / n
# 全体の分散
s_sq = (
((n1 - 1) * s1_sq + (n2 - 1) * s2_sq) / (n - 1)
+ (n1 * n2 / n) * ((y1_bar - y2_bar) ** 2) / (n - 1)
)
# 相関係数
numerator = (n1 * n2) ** 0.5 * (y1_bar - y2_bar)
denominator = (n * (n - 1) * s_sq) ** 0.5
r = numerator / denominator
# 結果出力
print("全体の平均 (y_bar):", y_bar)
print("全体の分散 (s^2):", s_sq)
print("相関係数 (r):", r)全体の平均 (y_bar): 33.0
全体の分散 (s^2): 74.03444444444443
相関係数 (r): 0.5799309710329085与えられたデータを基に、全体の平均と分散を計算し、相関係数を求め、解答と一致することを確認しました。
2015 Q5(2)
組標本の相関係数を、2つに分けられた組標本のそれぞれ平均と全体の不偏分散で表現しました。

コード
与えられた式を用いて計算した相関系数と、通常の定義式を用いて計算した相関係数が一致するかシミュレーションで確認をします。
# 2015 Q5(2) 2024.12.23
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションパラメータ
n1 = 30 # グループ1のサンプル数
n2 = 20 # グループ2のサンプル数
n = n1 + n2 # 全体のサンプル数
simulations = 1000 # シミュレーションの回数
# 結果を格納するリスト
custom_r_values = [] # 式で計算した相関係数
standard_r_values = [] # 通常の相関係数
for _ in range(simulations):
# y の生成 (正規分布)
y1 = np.random.normal(0, 1, n1)
y2 = np.random.normal(0, 1, n2)
y = np.concatenate([y1, y2])
# a の生成
a_values = np.concatenate([np.full(n1, 1), np.full(n2, -1)])
# 平均と分散
y_bar = np.mean(y)
s_sq_y = np.var(y, ddof=1)
# 共分散
covariance_manual = np.mean((y - y_bar) * (a_values - np.mean(a_values)))
# 通常の相関係数
standard_r = covariance_manual / np.sqrt(s_sq_y * np.var(a_values, ddof=1))
standard_r_values.append(standard_r)
# 式での相関係数
y1_bar = np.mean(y1)
y2_bar = np.mean(y2)
numerator_custom = np.sqrt(n1 * n2) * (y1_bar - y2_bar)
denominator_custom = np.sqrt(n * (n - 1) * s_sq_y)
custom_r = numerator_custom / denominator_custom
custom_r_values.append(custom_r)
# グラフの描画
plt.figure(figsize=(8, 8))
plt.scatter(custom_r_values, standard_r_values, alpha=0.5, color='blue', label=r"$r = \frac{\sqrt{n_1 n_2} (\bar{y}_1 - \bar{y}_2)}{\sqrt{n(n-1)s^2}}$")
plt.plot([min(custom_r_values), max(custom_r_values)], [min(custom_r_values), max(custom_r_values)], color='red', linestyle='--', label=r"$r = \frac{\mathrm{Cov}(X, Y)}{\sqrt{\mathrm{Var}(X)\mathrm{Var}(Y)}}$")
plt.title("相関係数の比較", fontsize=14)
plt.xlabel("式による相関係数", fontsize=12)
plt.ylabel("通常の相関係数", fontsize=12)
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()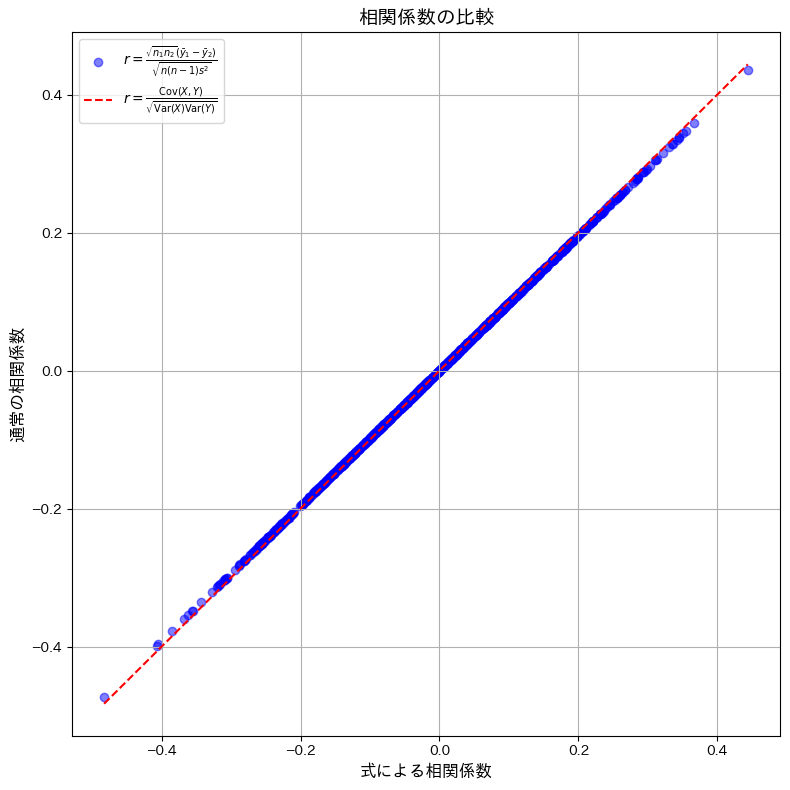
与えられた式を用いて計算した相関系数と、通常の定義式を用いて計算した相関係数が一致しました。わずかに観測された誤差は、浮動小数点演算による丸め誤差であると考えられます。
2015 Q5(1)
2つに分けられた標本それぞれの平均と不偏分散を用い、元の平均と不偏分散を式で表しました。

コード
直接アプローチと間接アプローチで求めた と
と が一致するか確認をします。
が一致するか確認をします。
# 2015 Q5(1) 2024.12.22
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションパラメータ
n1 = 30 # グループ1のサンプル数
n2 = 20 # グループ2のサンプル数
n = n1 + n2 # 全体のサンプル数
simulations = 10000 # シミュレーションの回数
# 結果を格納するリスト
y_split = [] # 分割アプローチで計算した平均
y_direct = [] # 直接アプローチで計算した平均
s2_split = [] # 分割アプローチで計算した分散
s2_direct = [] # 直接アプローチで計算した分散
for _ in range(simulations):
# ランダムサンプル生成 (正規分布 N(0, 1) を仮定)
group1 = np.random.normal(0, 1, n1)
group2 = np.random.normal(0, 1, n2)
# グループごとの平均と分散
y1_bar = np.mean(group1)
y2_bar = np.mean(group2)
s1_sq = np.var(group1, ddof=1) # 分散 (不偏推定)
s2_sq = np.var(group2, ddof=1)
# 分割アプローチの平均と分散
y_bar_split = (n1 * y1_bar + n2 * y2_bar) / n
s_sq_split = (
((n1 - 1) * s1_sq + (n2 - 1) * s2_sq) / (n - 1)
+ (n1 * n2 / n) * (y1_bar - y2_bar) ** 2 / (n - 1)
)
# 直接アプローチの平均と分散
all_data = np.concatenate([group1, group2])
y_bar_direct = np.mean(all_data)
s_sq_direct = np.var(all_data, ddof=1)
# データを格納
y_split.append(y_bar_split)
y_direct.append(y_bar_direct)
s2_split.append(s_sq_split)
s2_direct.append(s_sq_direct)
# グラフの描画
fig, axes = plt.subplots(1, 2, figsize=(16, 8))
# 平均の比較
axes[0].scatter(y_split, y_direct, alpha=0.5, color='blue', label=r"分割アプローチ: $\bar{y} = \frac{1}{n}(n_1\bar{y}_1 + n_2\bar{y}_2)$")
axes[0].plot([min(y_split), max(y_split)], [min(y_split), max(y_split)], color='red', linestyle='--', label=r"直接アプローチ: $\bar{y} = \frac{1}{n} \sum_{i=1}^n y_i$")
axes[0].set_xlabel('分割アプローチ (平均)', fontsize=12)
axes[0].set_ylabel('直接アプローチ (平均)', fontsize=12)
axes[0].set_title('平均の比較: 分割 vs 直接', fontsize=14)
axes[0].legend()
axes[0].grid(True)
# 分散の比較
axes[1].scatter(s2_split, s2_direct, alpha=0.5, color='green', label=r"分割アプローチ: $s^2 = \frac{1}{n-1} \left\{(n_1-1)s_1^2 + (n_2-1)s_2^2 + \frac{n_1n_2}{n}(\bar{y}_1 - \bar{y}_2)^2 \right\}$")
axes[1].plot([min(s2_split), max(s2_split)], [min(s2_split), max(s2_split)], color='red', linestyle='--', label=r"直接アプローチ: $s^2 = \frac{1}{n-1}\sum_{i=1}^n (y_i - \bar{y})^2$")
axes[1].set_xlabel('分割アプローチ (分散)', fontsize=12)
axes[1].set_ylabel('直接アプローチ (分散)', fontsize=12)
axes[1].set_title('分散の比較: 分割 vs 直接', fontsize=14)
axes[1].legend()
axes[1].grid(True)
# グラフの表示
plt.tight_layout()
plt.show()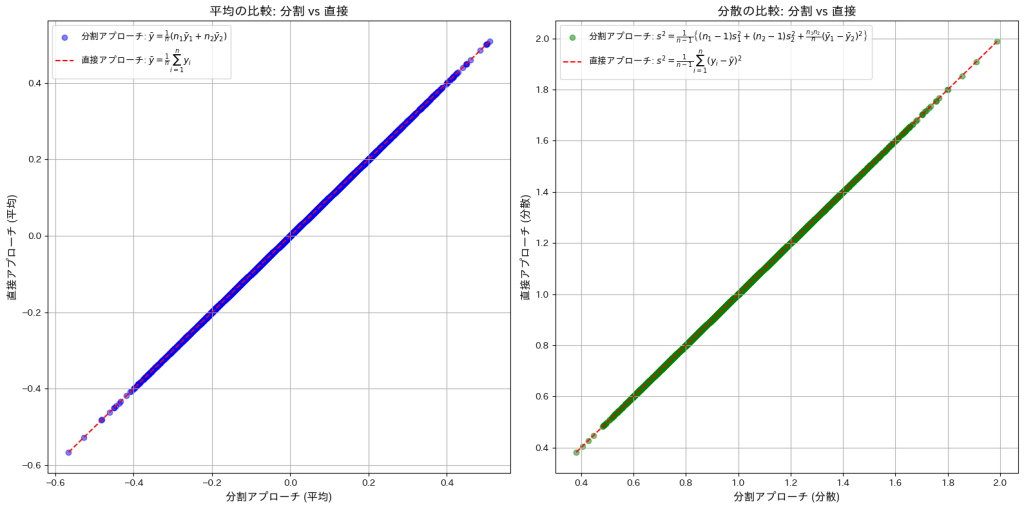
直接アプローチと間接アプローチで求めたとが一致しました。
2015 Q4(5)
確率行列が対称行列であるとき、ある新しいパラメータ行列も対称であるか示し、更にその逆が成り立つかも調べました。

コード
セル確率 の対称性が成り立つ場合にパラメータ
の対称性が成り立つ場合にパラメータ が対称性
が対称性 を持つことを確認します。
を持つことを確認します。
# 2015 Q4(5) 2024.12.21
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# 1. データ生成
np.random.seed(42) # 再現性のためのシード値
I = 4 # 行列のサイズ
p_matrix_sym = np.random.rand(I, I) # 対称性を持たないランダムな確率行列
p_matrix_sym = (p_matrix_sym + p_matrix_sym.T) / 2 # 対称性を強制
# 対称性が成り立たない確率行列
p_matrix_asym = np.random.rand(I, I)
p_matrix_asym = p_matrix_asym / np.sum(p_matrix_asym) # 正規化
# 正規化して確率にする
p_matrix_sym = p_matrix_sym / np.sum(p_matrix_sym)
# 2. λ_ij の計算関数
def calculate_lambda(p_matrix):
I = p_matrix.shape[0]
lambdas = np.zeros((I, I))
for i in range(1, I):
for j in range(1, I):
lambdas[i, j] = np.log(p_matrix[i, j] * p_matrix[0, 0] / (p_matrix[i, 0] * p_matrix[0, j]))
return lambdas
# 対称性の仮説が成り立つ場合の λ_ij
lambda_sym = calculate_lambda(p_matrix_sym)
# 対称性の仮説が成り立たない場合の λ_ij
lambda_asym = calculate_lambda(p_matrix_asym)
# 3. 可視化: ヒートマップをプロット
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 対称性が成り立つ確率行列
sns.heatmap(p_matrix_sym, annot=True, fmt=".3f", cmap="Blues", ax=axes[0, 0])
axes[0, 0].set_title("対称性が成り立つ確率行列 $p_{ij}$")
# 対称性が成り立つ λ_ij 行列
sns.heatmap(lambda_sym, annot=True, fmt=".3f", cmap="Greens", ax=axes[0, 1])
axes[0, 1].set_title("対称性が成り立つ場合の $\lambda_{ij}$")
# 対称性が成り立たない確率行列
sns.heatmap(p_matrix_asym, annot=True, fmt=".3f", cmap="Reds", ax=axes[1, 0])
axes[1, 0].set_title("対称性が成り立たない確率行列 $p_{ij}$")
# 対称性が成り立たない λ_ij 行列
sns.heatmap(lambda_asym, annot=True, fmt=".3f", cmap="Purples", ax=axes[1, 1])
axes[1, 1].set_title("対称性が成り立たない場合の $\lambda_{ij}$")
plt.tight_layout()
plt.show()
# 4. λ_ij = λ_ji の確認
print("対称性が成り立つ場合:")
print("λ_ij == λ_ji:", np.allclose(lambda_sym, lambda_sym.T))
print("\n対称性が成り立たない場合:")
print("λ_ij == λ_ji:", np.allclose(lambda_asym, lambda_asym.T))
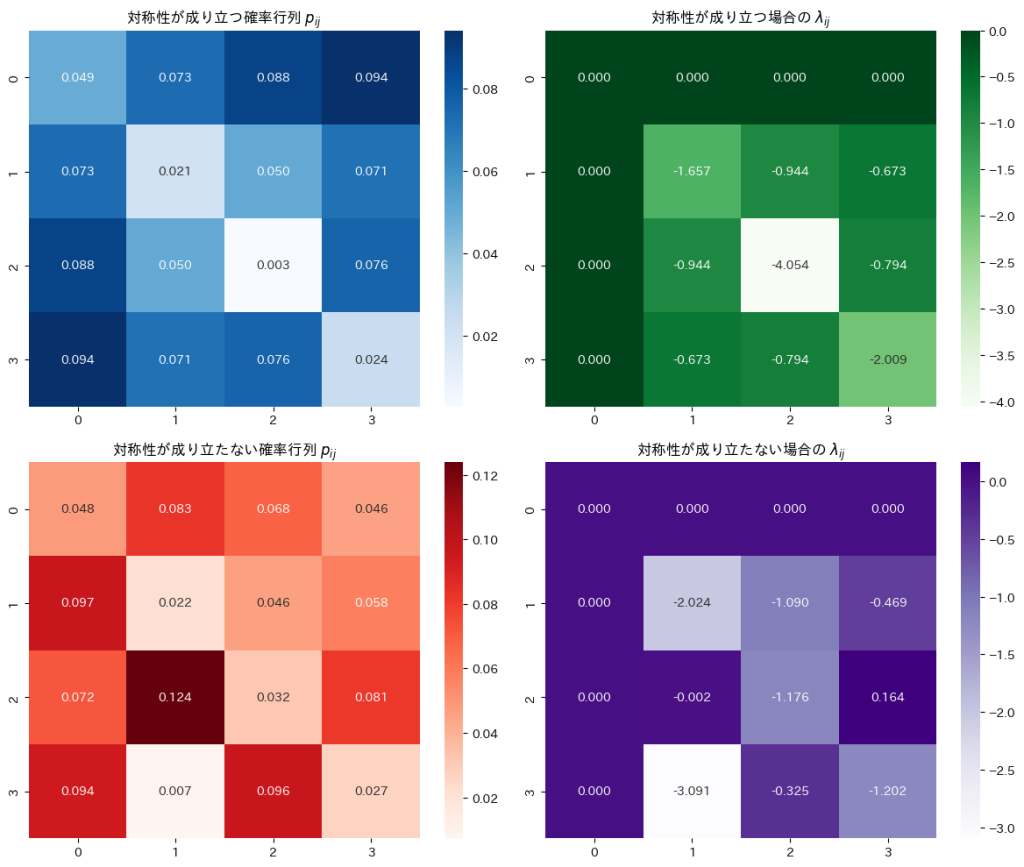
セル確率の対称性が成り立つ場合に、パラメータが対称性を持つことを確認しました。