2014 Q5(4)
テレビ番組の視聴満足回数の調査で満足と答えた回数のそれぞれ人数の適合度検定を実施し適合を判断する手順を述べました。

コード
多項確率 が、
が、 に忠実に基づく場合と、各番組または各回答者の満足度が異なるモデルにおいて、カイ二乗統計量、尤度比統計量、およびp-値を計算し、モデルの適合性を比較します。
に忠実に基づく場合と、各番組または各回答者の満足度が異なるモデルにおいて、カイ二乗統計量、尤度比統計量、およびp-値を計算し、モデルの適合性を比較します。
import numpy as np
from scipy.stats import chi2
import matplotlib.pyplot as plt
# シミュレーションの設定
n = 100 # 回答者数
p_true = 0.6 # 真の成功確率(忠実なモデル)
categories = np.arange(5) # カテゴリ (0~4)
n_simulations = 1000 # シミュレーション回数
# 忠実なモデルの確率 q_j
qj_true = [np.math.comb(4, j) * (p_true ** j) * ((1 - p_true) ** (4 - j)) for j in categories]
# 統計量を記録するリスト
chi_squared_true = []
likelihood_ratio_true = []
chi_squared_noisy_program = []
likelihood_ratio_noisy_program = []
chi_squared_noisy_responder = []
likelihood_ratio_noisy_responder = []
# 二項分布に従わない (qj_noisy_program): q_j をランダムに変更してズラす
qj_noisy_program = np.array(qj_true) + np.random.uniform(-0.1, 0.1, size=len(qj_true))
qj_noisy_program = np.clip(qj_noisy_program, 0, None) # 確率が0未満にならないようにする
qj_noisy_program = qj_noisy_program / np.sum(qj_noisy_program) # 確率なので正規化
# 各回答者の満足度が異なる場合(qj_noisy_responder)をランダム設定
p_responders = np.random.uniform(0.35, 0.85, size=n)
qj_noisy_responder = np.zeros(len(categories))
for p in p_responders:
qj_responder = [np.math.comb(4, j) * (p ** j) * ((1 - p) ** (4 - j)) for j in categories]
qj_noisy_responder += qj_responder
qj_noisy_responder /= np.sum(qj_noisy_responder)
# シミュレーション開始
for _ in range(n_simulations):
# 忠実なモデル(均一)
obs_true = np.random.multinomial(n, qj_true)
exp_true = n * np.array(qj_true)
chi2_stat_true = np.sum((obs_true - exp_true) ** 2 / exp_true) # カイ二乗統計量
likelihood_stat_true = 2 * np.sum(obs_true * np.log(obs_true / exp_true, where=(obs_true > 0))) # 尤度比統計量
chi_squared_true.append(chi2_stat_true)
likelihood_ratio_true.append(likelihood_stat_true)
# 各番組の満足度が異なる場合
obs_noisy_program = np.random.multinomial(n, qj_noisy_program)
exp_noisy_program = n * np.array(qj_true)
chi2_stat_noisy_program = np.sum((obs_noisy_program - exp_noisy_program) ** 2 / exp_noisy_program) # カイ二乗統計量
likelihood_stat_noisy_program = 2 * np.sum(obs_noisy_program * np.log(obs_noisy_program / exp_noisy_program, where=(obs_noisy_program > 0))) # 尤度比統計量
chi_squared_noisy_program.append(chi2_stat_noisy_program)
likelihood_ratio_noisy_program.append(likelihood_stat_noisy_program)
# 各回答者の満足度が異なる場合
obs_noisy_responder = np.random.multinomial(n, qj_noisy_responder)
exp_noisy_responder = n * np.array(qj_true)
chi2_stat_noisy_responder = np.sum((obs_noisy_responder - exp_noisy_responder) ** 2 / exp_noisy_responder) # カイ二乗統計量
likelihood_stat_noisy_responder = 2 * np.sum(obs_noisy_responder * np.log(obs_noisy_responder / exp_noisy_responder, where=(obs_noisy_responder > 0))) # 尤度比統計量
chi_squared_noisy_responder.append(chi2_stat_noisy_responder)
likelihood_ratio_noisy_responder.append(likelihood_stat_noisy_responder)
# 平均値を計算
mean_chi2_true = np.mean(chi_squared_true)
mean_likelihood_true = np.mean(likelihood_ratio_true)
mean_chi2_noisy_program = np.mean(chi_squared_noisy_program)
mean_likelihood_noisy_program = np.mean(likelihood_ratio_noisy_program)
mean_chi2_noisy_responder = np.mean(chi_squared_noisy_responder)
mean_likelihood_noisy_responder = np.mean(likelihood_ratio_noisy_responder)
# 各統計量に対応するp値を計算
p_value_chi2_true = 1 - chi2.cdf(mean_chi2_true, df=3)
p_value_likelihood_true = 1 - chi2.cdf(mean_likelihood_true, df=3)
p_value_chi2_noisy_program = 1 - chi2.cdf(mean_chi2_noisy_program, df=3)
p_value_likelihood_noisy_program = 1 - chi2.cdf(mean_likelihood_noisy_program, df=3)
p_value_chi2_noisy_responder = 1 - chi2.cdf(mean_chi2_noisy_responder, df=3)
p_value_likelihood_noisy_responder = 1 - chi2.cdf(mean_likelihood_noisy_responder, df=3)
# 結果の出力
print(f"忠実なモデル(均一)の平均カイ二乗統計量: {mean_chi2_true:.4f}, 平均p値: {p_value_chi2_true:.4f}")
print(f"忠実なモデル(均一)の平均尤度比統計量: {mean_likelihood_true:.4f}, 平均p値: {p_value_likelihood_true:.4f}")
print(f"各番組の満足度が異なる場合の平均カイ二乗統計量: {mean_chi2_noisy_program:.4f}, 平均p値: {p_value_chi2_noisy_program:.4f}")
print(f"各番組の満足度が異なる場合の平均尤度比統計量: {mean_likelihood_noisy_program:.4f}, 平均p値: {p_value_likelihood_noisy_program:.4f}")
print(f"各回答者の満足度が異なる場合の平均カイ二乗統計量: {mean_chi2_noisy_responder:.4f}, 平均p値: {p_value_chi2_noisy_responder:.4f}")
print(f"各回答者の満足度が異なる場合の平均尤度比統計量: {mean_likelihood_noisy_responder:.4f}, 平均p値: {p_value_likelihood_noisy_responder:.4f}")
# カイ二乗分布のPDFを計算
x = np.linspace(0, 20, 500) # x軸の範囲
pdf = chi2.pdf(x, df=3) # 自由度3のPDF
# グラフの描画
plt.figure(figsize=(10, 6))
plt.plot(x, pdf, label="自由度3のカイ二乗分布", linewidth=2)
plt.axvline(mean_chi2_true, color="blue", linestyle="--", label=f"忠実モデルのカイ二乗: {mean_chi2_true:.2f}")
plt.axvline(mean_likelihood_true, color="cyan", linestyle="--", label=f"忠実モデルの尤度比: {mean_likelihood_true:.2f}")
plt.axvline(mean_chi2_noisy_program, color="green", linestyle="--", label=f"番組ごとに異なるカイ二乗: {mean_chi2_noisy_program:.2f}")
plt.axvline(mean_likelihood_noisy_program, color="lime", linestyle="--", label=f"番組ごとに異なる尤度比: {mean_likelihood_noisy_program:.2f}")
plt.axvline(mean_chi2_noisy_responder, color="red", linestyle="--", label=f"回答者ごとに異なるカイ二乗: {mean_chi2_noisy_responder:.2f}")
plt.axvline(mean_likelihood_noisy_responder, color="magenta", linestyle="--", label=f"回答者ごとに異なる尤度比: {mean_likelihood_noisy_responder:.2f}")
plt.xlabel("$X^2$ 値", fontsize=12)
plt.ylabel
plt.ylabel("確率密度", fontsize=12)
plt.title("自由度3のカイ二乗分布と統計量", fontsize=14)
plt.legend(fontsize=12) # ここで凡例を表示
plt.grid(alpha=0.5)
plt.show()忠実なモデル(均一)の平均カイ二乗統計量: 4.1751, 平均p値: 0.2432
忠実なモデル(均一)の平均尤度比統計量: 4.3247, 平均p値: 0.2285
各番組の満足度が異なる場合の平均カイ二乗統計量: 13.2002, 平均p値: 0.0042
各番組の満足度が異なる場合の平均尤度比統計量: 16.4412, 平均p値: 0.0009
各回答者の満足度が異なる場合の平均カイ二乗統計量: 10.3066, 平均p値: 0.0161
各回答者の満足度が異なる場合の平均尤度比統計量: 8.5302, 平均p値: 0.0362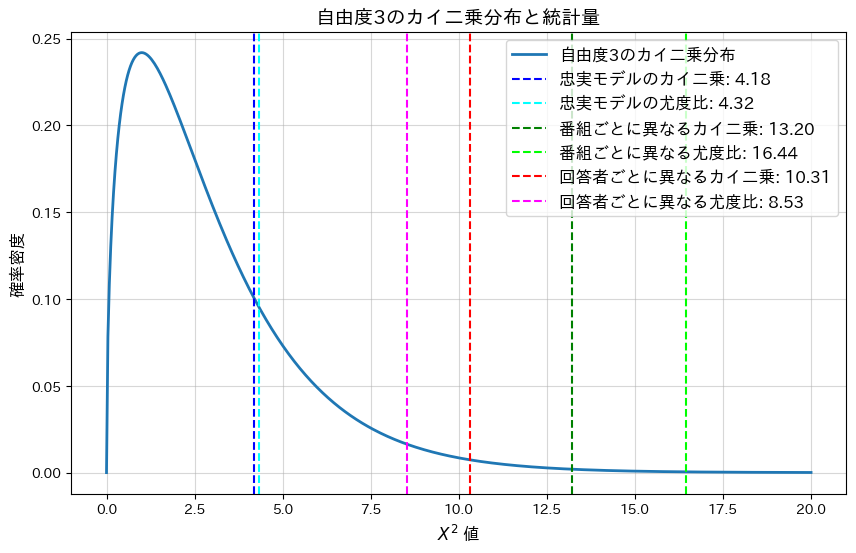
忠実なモデルの平均p-値は大きく、モデルによく適合していることが分かります。一方、各番組または各回答者の満足度が異なるモデルではp-値が0.05以下となり、モデルがデータに適合していないことが分かります。
2014 Q5(3)
テレビ番組の視聴満足回数の調査で満足と答えた回数のそれぞれ人数の適合度検定のための尤度比検定量と自由度を求めました。

コード
多項確率が、に忠実に基づく場合と、ランダムにノイズを加えた(ズレた)場合についてシミュレーションを行い、尤度比統計量とp-値を計算して比較します。
# 2014 Q5(3) 2025.1.17
import numpy as np
from scipy.stats import chi2
import matplotlib.pyplot as plt
# シミュレーションの設定
n = 100 # 人数
p_true = 0.6 # 真の成功確率
categories = np.arange(5) # カテゴリ (0~4)
n_simulations = 1000 # シミュレーション回数
# 二項分布モデルに基づく q_j の計算 (忠実な設定)
qj_true = [np.math.comb(4, j) * (p_true ** j) * ((1 - p_true) ** (4 - j)) for j in categories]
# 二項分布に従わない (qj_noisy): q_j をランダムに変更してズラす
qj_noisy = np.array(qj_true) + np.random.uniform(-0.1, 0.1, size=len(qj_true))
qj_noisy = np.clip(qj_noisy, 0, None) # 確率が0未満にならないようにする
qj_noisy = qj_noisy / np.sum(qj_noisy) # 確率なので正規化
# 尤度比統計量を記録するリスト
likelihood_ratio_true = []
p_values_true = []
likelihood_ratio_noisy = []
p_values_noisy = []
for _ in range(n_simulations):
# 忠実なモデルの観測データ
obs_true = np.random.multinomial(n, qj_true)
exp_true = n * np.array(qj_true)
likelihood_stat_true = 2 * np.sum(obs_true * np.log(obs_true / exp_true, where=(obs_true > 0)))
p_val_true = 1 - chi2.cdf(likelihood_stat_true, df=3) # 自由度 = カテゴリ数 - 1 - 推定パラメータ数
likelihood_ratio_true.append(likelihood_stat_true)
p_values_true.append(p_val_true)
# ズレたモデルの観測データ
obs_noisy = np.random.multinomial(n, qj_noisy)
exp_noisy = n * np.array(qj_true) # 忠実な期待値を使用
likelihood_stat_noisy = 2 * np.sum(obs_noisy * np.log(obs_noisy / exp_noisy, where=(obs_noisy > 0)))
p_val_noisy = 1 - chi2.cdf(likelihood_stat_noisy, df=3)
likelihood_ratio_noisy.append(likelihood_stat_noisy)
p_values_noisy.append(p_val_noisy)
# 平均尤度比統計量を計算
mean_likelihood_true = np.mean(likelihood_ratio_true)
mean_likelihood_noisy = np.mean(likelihood_ratio_noisy)
# カイ二乗分布のPDFを計算
x = np.linspace(0, 20, 500) # x軸の範囲
pdf = chi2.pdf(x, df=3) # 自由度3のPDF
# 結果の出力
print(f"忠実なモデルの平均尤度比統計量: {mean_likelihood_true:.4f}")
print(f"忠実なモデルの平均p値: {np.mean(p_values_true):.4f}")
print(f"ズレたモデルの平均尤度比統計量: {mean_likelihood_noisy:.4f}")
print(f"ズレたモデルの平均p値: {np.mean(p_values_noisy):.4f}")
# グラフの描画
plt.figure(figsize=(10, 6))
plt.plot(x, pdf, label="自由度3のカイ二乗分布", linewidth=2)
plt.axvline(mean_likelihood_true, color="blue", linestyle="--", label=f"忠実モデルの平均: {mean_likelihood_true:.2f}")
plt.axvline(mean_likelihood_noisy, color="red", linestyle="--", label=f"ズレモデルの平均: {mean_likelihood_noisy:.2f}")
plt.xlabel("$X^2$ 値", fontsize=12)
plt.ylabel("確率密度", fontsize=12)
plt.title("自由度3のカイ二乗分布と平均尤度比統計量", fontsize=14)
plt.legend(fontsize=12)
plt.grid(alpha=0.5)
plt.show()忠実なモデルの平均尤度比統計量: 3.9418
忠実なモデルの平均p値: 0.3909
ズレたモデルの平均尤度比統計量: 16.7360
ズレたモデルの平均p値: 0.0081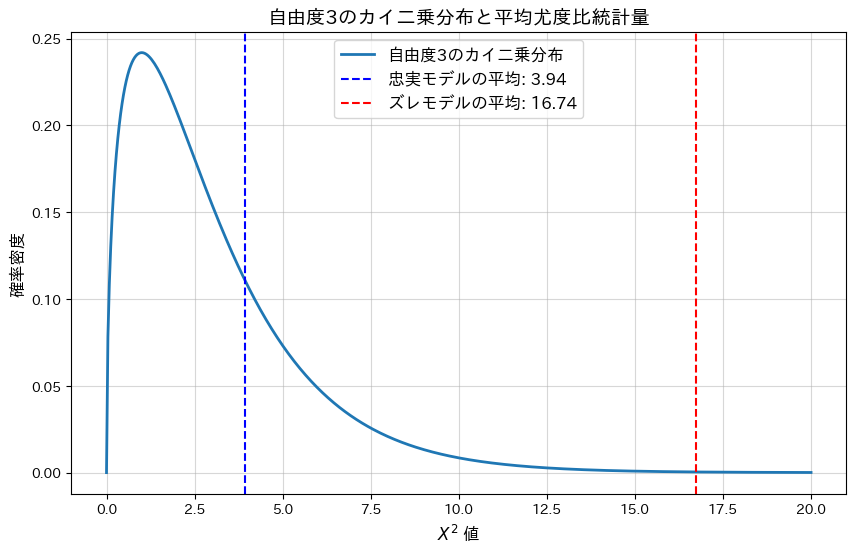
忠実なモデルの平均p-値は大きく、モデルによく適合していることが分かります。一方、ランダムにノイズを加えた(ズレた)モデルではp-値が0.05以下となり、モデルがデータに適合していないことが分かります。
2014 Q5(2)
テレビ番組の視聴満足回数の調査で満足と答えた回数のそれぞれ人数の適合度カイ二乗統計量と自由度を求めました。

コード
多項確率が、に忠実に基づく場合と、ランダムにノイズを加えた(ズレた)場合についてシミュレーションを行い、適合度カイ二乗統計量とp-値を計算して比較します。
# 2014 Q5(2) 2025.1.16
import numpy as np
from scipy.stats import chi2
import matplotlib.pyplot as plt
# シミュレーションの設定
n = 100 # 人数
p_true = 0.6 # 真の成功確率
categories = np.arange(5) # カテゴリ (0~4)
n_simulations = 1000 # シミュレーション回数
# 二項分布モデルに基づく q_j の計算 (忠実な設定)
qj_true = [np.math.comb(4, j) * (p_true ** j) * ((1 - p_true) ** (4 - j)) for j in categories]
# 二項分布に従わない (qj_noisy): q_j をランダムに変更してズラす
qj_noisy = np.array(qj_true) + np.random.uniform(-0.1, 0.1, size=len(qj_true))
qj_noisy = np.clip(qj_noisy, 0, None) # 確率が0未満にならないようにする
qj_noisy = qj_noisy / np.sum(qj_noisy) # 確率なので正規化
# カイ二乗統計量と p 値を記録するリスト
chi_squared_true = []
p_values_true = []
chi_squared_noisy = []
p_values_noisy = []
for _ in range(n_simulations):
# 忠実なモデルの観測データ
obs_true = np.random.multinomial(n, qj_true)
exp_true = n * np.array(qj_true)
chi2_stat_true = np.sum((obs_true - exp_true) ** 2 / exp_true)
p_val_true = 1 - chi2.cdf(chi2_stat_true, df=3) # 自由度 = カテゴリ数 - 1 - 推定パラメータ数
chi_squared_true.append(chi2_stat_true)
p_values_true.append(p_val_true)
# ズレたモデルの観測データ
obs_noisy = np.random.multinomial(n, qj_noisy)
exp_noisy = n * np.array(qj_true) # 忠実な期待値を使用
chi2_stat_noisy = np.sum((obs_noisy - exp_noisy) ** 2 / exp_noisy)
p_val_noisy = 1 - chi2.cdf(chi2_stat_noisy, df=3)
chi_squared_noisy.append(chi2_stat_noisy)
p_values_noisy.append(p_val_noisy)
# 平均カイ二乗統計量を計算
mean_chi2_true = np.mean(chi_squared_true)
mean_chi2_noisy = np.mean(chi_squared_noisy)
# カイ二乗分布のPDFを計算
x = np.linspace(0, 20, 500) # x軸の範囲
pdf = chi2.pdf(x, df=3) # 自由度3のPDF
# 結果の出力
print(f"忠実なモデルの平均カイ二乗統計量: {mean_chi2_true:.4f}")
print(f"忠実なモデルの平均p値: {np.mean(p_values_true):.4f}")
print(f"ズレたモデルの平均カイ二乗統計量: {mean_chi2_noisy:.4f}")
print(f"ズレたモデルの平均p値: {np.mean(p_values_noisy):.4f}")
# グラフの描画
plt.figure(figsize=(10, 6))
plt.plot(x, pdf, label="自由度3のカイ二乗分布", linewidth=2)
plt.axvline(mean_chi2_true, color="blue", linestyle="--", label=f"忠実モデルの平均: {mean_chi2_true:.2f}")
plt.axvline(mean_chi2_noisy, color="red", linestyle="--", label=f"ズレモデルの平均: {mean_chi2_noisy:.2f}")
plt.xlabel("$X^2$ 値", fontsize=12)
plt.ylabel("確率密度", fontsize=12)
plt.title("自由度3のカイ二乗分布と平均カイ二乗統計量", fontsize=14)
plt.legend(fontsize=12)
plt.grid(alpha=0.5)
plt.show()忠実なモデルの平均カイ二乗統計量: 3.8112
忠実なモデルの平均p値: 0.4026
ズレたモデルの平均カイ二乗統計量: 13.4317
ズレたモデルの平均p値: 0.0236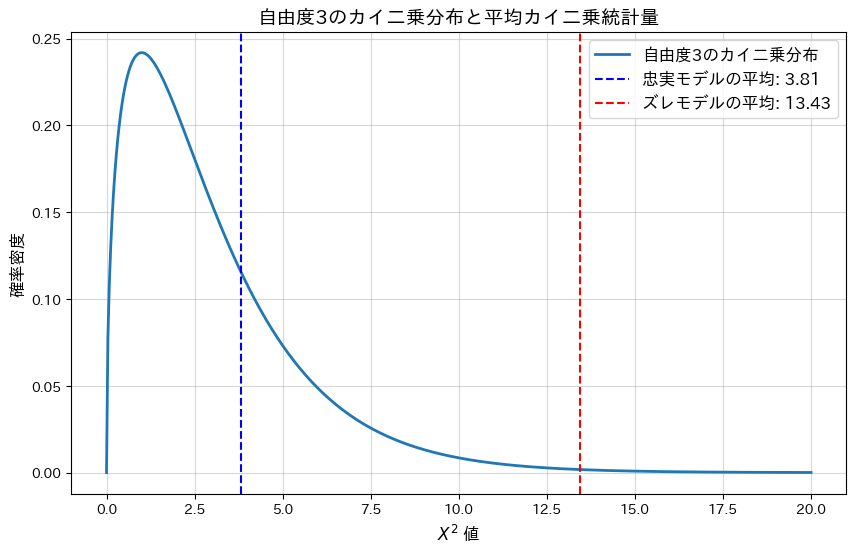
忠実なモデルの平均p-値は大きく、モデルによく適合していることが分かります。一方、ランダムにノイズを加えた(ズレた)モデルではp-値が0.05以下となり、モデルがデータに適合していないことが分かります。
2014 Q5(1)
テレビ番組の視聴満足回数の調査で満足と答えた回数のそれぞれ人数との組みが多項分布に従うのを利用し多項確率を構成する二項分布の確率pの最尤推定量を求めました。
コード
真の確率pに基づいてシミュレーションを行い、最尤推定値 を計算し、真の確率pと比較します。
を計算し、真の確率pと比較します。
# 2014 Q5(1) 2025.1.15
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションのパラメータ
n_simulations = 10000 # シミュレーション回数
n = 100 # 調査対象の人数
p_true = 0.6 # 真の満足確率
# nj のシミュレーション (j = 0, 1, 2, 3, 4)
data = np.random.binomial(4, p_true, size=n_simulations * n).reshape(n_simulations, n)
# 各シミュレーションでの最尤推定値を計算
p_estimates = np.sum(data, axis=1) / (4 * n)
# 平均値(推定されたp^の期待値)を計算
mean_p_estimate = np.mean(p_estimates)
# 推定されたp^の平均値と真の値を出力
print(f"推定された最尤推定値の平均: {mean_p_estimate:.4f}")
print(f"真の値: {p_true:.4f}")
# グラフの描画
plt.hist(p_estimates, bins=30, density=True, alpha=0.75, label="推定された $\\hat{p}$")
plt.axvline(p_true, color='red', linestyle='dashed', label=f"真の値 $p = {p_true}$")
plt.xlabel("推定された $\\hat{p}$")
plt.ylabel("密度")
plt.title("最尤推定値 $\\hat{p}$ の分布")
plt.legend()
plt.grid(alpha=0.5)
plt.show()推定された最尤推定値の平均: 0.5997
真の値: 0.6000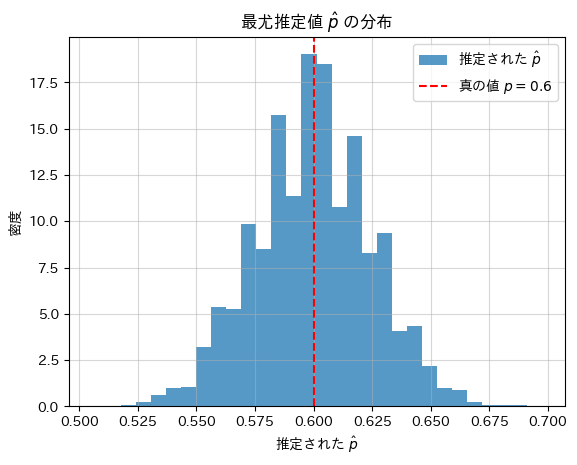
シミュレーションの結果、最尤推定値は、真の確率pに近い値を示しました。
2015 Q4(2)
確率の分割表に対称性があるという仮説の下での期待度数の最尤推定を行いました。
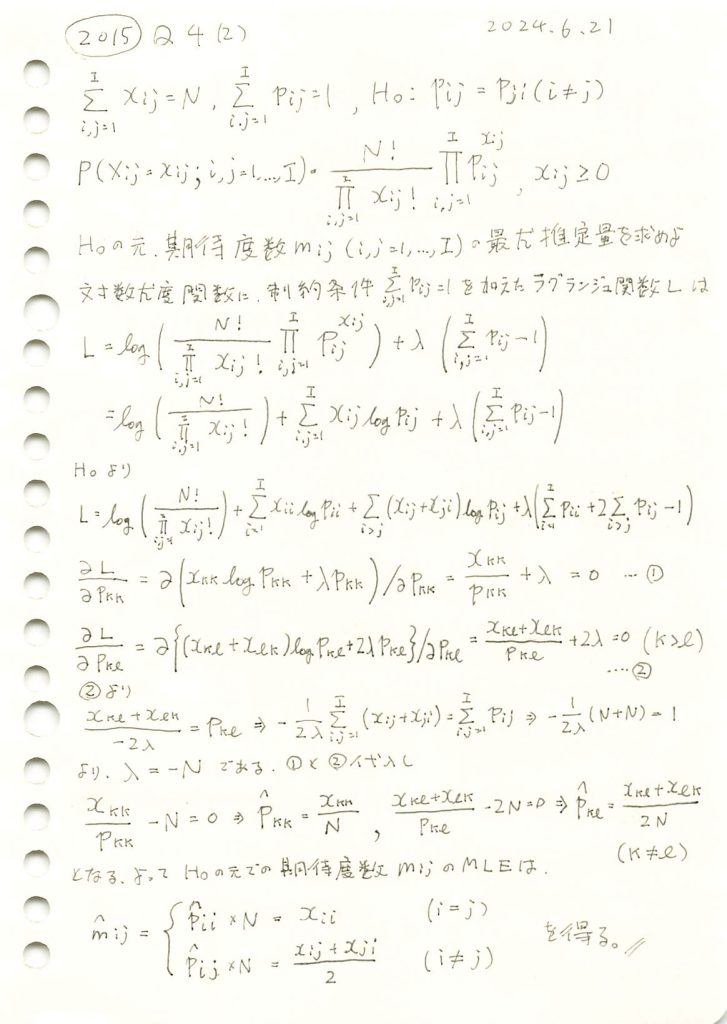
与えられた観測度数表から に基づき期待度数を求めます。
に基づき期待度数を求めます。
# 2015 Q4(2) 2024.12.18
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 1. 観測度数表
observed_counts = np.array([[1520, 266, 124, 66],
[234, 1512, 432, 78],
[117, 362, 1772, 205],
[36, 82, 179, 492]])
# 2. 総サンプルサイズ N
N = observed_counts.sum()
# 3. 期待度数 m_ij の計算 (対称性の仮説)
m_ij = np.zeros_like(observed_counts, dtype=float)
I = observed_counts.shape[0]
for i in range(I):
for j in range(I):
if i == j: # 対角要素
m_ij[i, j] = observed_counts[i, j]
else: # 非対角要素
m_ij[i, j] = (observed_counts[i, j] + observed_counts[j, i]) / 2
# 4. 観測度数と期待度数をDataFrameにまとめる
row_labels = col_labels = ["Highest", "Second", "Third", "Lowest"]
df_observed = pd.DataFrame(observed_counts, index=row_labels, columns=col_labels)
df_expected = pd.DataFrame(np.round(m_ij, 2), index=row_labels, columns=col_labels)
# 5. 観測度数と期待度数のヒートマップを作成
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# 観測度数のヒートマップ
sns.heatmap(df_observed, annot=True, fmt=".0f", cmap="Blues", ax=axes[0])
axes[0].set_title("観測度数表 $x_{ij}$")
# 期待度数のヒートマップ
sns.heatmap(df_expected, annot=True, fmt=".2f", cmap="Greens", ax=axes[1])
axes[1].set_title("期待度数表 $\hat{m}_{ij}$ (対称性の仮説)")
plt.tight_layout()
plt.show()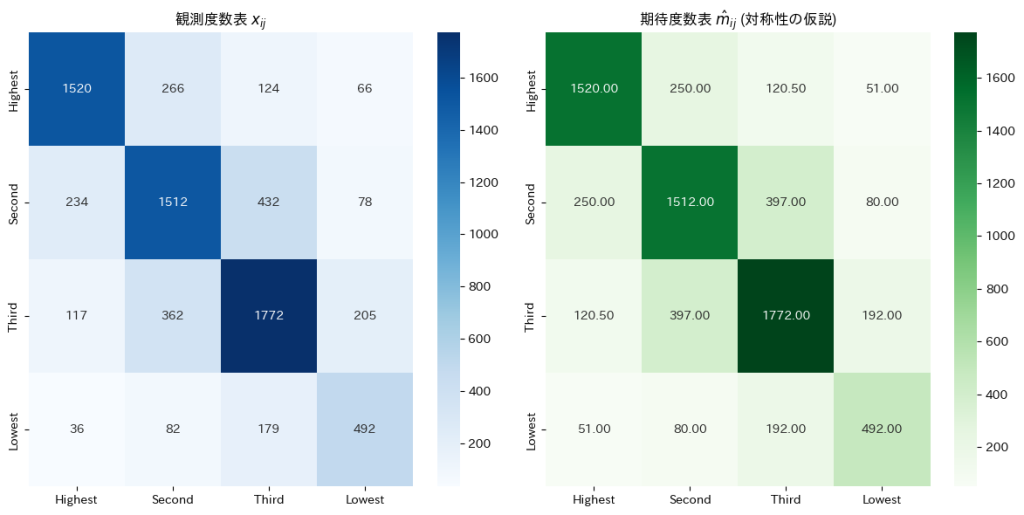
与えられた観測度数表からに基づいて期待度数を求めると、非対角要素は対応する2つの観測度数の平均として表され、対角要素は観測度数そのものが期待度数となりました。
2015 Q4(1)
観測度数と確率の分割表から、そうなり得る確率を求めました。

コード
与えられた観測度数表から仮にセル確率を計算し、その観測度数が多項分布に基づいて得られる確率を計算をします。
# 2015 Q4(1) 2024.12.17
import numpy as np
import pandas as pd
from scipy.stats import multinomial
# 観測度数表 (与えられたデータ)
observed_counts = np.array([[1520, 266, 124, 66],
[234, 1512, 432, 78],
[117, 362, 1772, 205],
[36, 82, 179, 492]])
# 総サンプルサイズ N の計算
N = observed_counts.sum()
# セル確率 pij の計算 (観測度数を総数で割る)
p_ij = observed_counts / N
# 観測度数とセル確率
row_labels = ["Highest", "Second", "Third", "Lowest"]
col_labels = ["Highest", "Second", "Third", "Lowest"]
# 観測度数
df_counts = pd.DataFrame(observed_counts, columns=col_labels, index=row_labels)
# セル確率
df_probs = pd.DataFrame(np.round(p_ij, 6), columns=col_labels, index=row_labels)
print("観測度数表 (x_ij):")
print(df_counts)
print("\nセル確率表 (p_ij):")
print(df_probs)
# 観測度数が得られる確率を計算
x_flat = observed_counts.flatten()
p_flat = p_ij.flatten()
# 多項分布の確率を計算
prob = multinomial.pmf(x_flat, n=N, p=p_flat)
print(f"\nこの観測度数表が得られる確率: {prob:.10e}")観測度数表 (x_ij):
Highest Second Third Lowest
Highest 1520 266 124 66
Second 234 1512 432 78
Third 117 362 1772 205
Lowest 36 82 179 492
セル確率表 (p_ij):
Highest Second Third Lowest
Highest 0.203290 0.035576 0.016584 0.008827
Second 0.031296 0.202220 0.057777 0.010432
Third 0.015648 0.048415 0.236993 0.027417
Lowest 0.004815 0.010967 0.023940 0.065802
この観測度数表が得られる確率: 7.0375704386e-24得られた確率はとても小さな数字になりました。これは、特定の具体的な度数の組み合わせが発生する確率であるため小さくなります。