2021 Q1(3)
変数変換を用いて二つの分布の和の確率密度関数を求めました。

コード
数式を使った計算
# 2024 Q1(3) 2024.8.19
import sympy as sp
# シンボリック変数の定義
x, z = sp.symbols('x z')
# 確率密度関数の定義
f_X = sp.exp(-x) # f_X(x) = e^(-x)
f_Y = sp.Piecewise((1, (z - x >= 0) & (z - x <= 1)), (0, True)) # f_Y(z - x) for 0 < z - x < 1
# 一般的な積分の設定
f_Z_integral = sp.integrate(f_X * f_Y, (x, 0, z))
# 結果の簡略化
f_Z_general = sp.simplify(f_Z_integral)
# 結果の表示
display(f_Z_general)
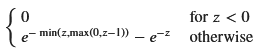
簡単のため、zの範囲を指定して再度計算
# 2024 Q1(3) 2024.8.19
import sympy as sp
# シンボリック変数の定義
x, z = sp.symbols('x z')
# 確率密度関数の定義
f_X = sp.exp(-x) # f_X(x) = e^(-x)
f_Y = 1 # f_Y(y) = 1 (0 < y < 1)
# 各範囲での計算
# 1. z <= 0 の場合
f_Z_1 = 0 # z <= 0 の場合は f_Z(z) = 0
# 2. 0 < z <= 1 の場合
f_Z_2_integral = sp.integrate(f_X * f_Y, (x, 0, z))
f_Z_2 = sp.simplify(f_Z_2_integral)
# 3. z > 1 の場合
f_Z_3_integral = sp.integrate(f_X * f_Y, (x, z-1, z))
f_Z_3 = sp.simplify(f_Z_3_integral)
# 結果の表示
print(f"f_Z(z) for z <= 0:")
display(f_Z_1)
print(f"f_Z(z) for 0 < z <= 1:")
display(f_Z_2)
print(f"f_Z(z) for z > 1:")
display(f_Z_3)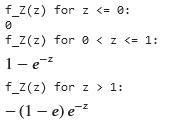
プロット
import numpy as np
import matplotlib.pyplot as plt
from scipy.integrate import quad
# 確率密度関数 f_X(x) と f_Y(y)
def f_X(x):
return np.exp(-x) if x > 0 else 0
def f_Y(y):
return 1 if 0 < y < 1 else 0
# Z = X + Y の確率密度関数 f_Z(z) の計算
def f_Z(z):
integrand = lambda x: f_X(x) * f_Y(z - x)
return quad(integrand, max(0, z-1), z)[0] #積分範囲を限定する場合
#return quad(integrand, 0, z, epsabs=1e-8, epsrel=1e-8)[0] #積分範囲を広くする場合
# z の範囲を設定し、f_Z(z) を計算
z_values = np.linspace(0, 5, 1000) # 増加させたサンプル数
f_Z_values = np.array([f_Z(z) for z in z_values])
# グラフの描画
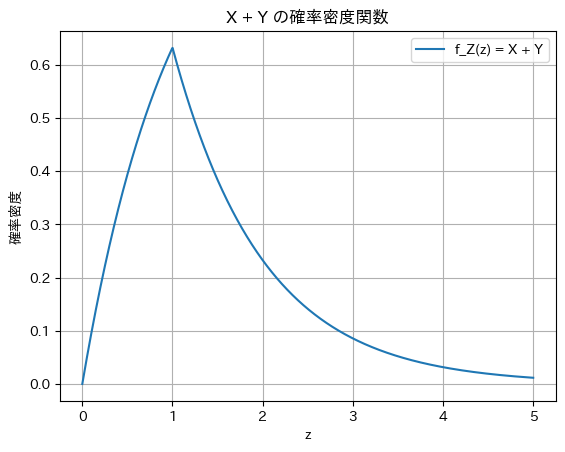
plt.plot(z_values, f_Z_values, label='f_Z(z) = X + Y')
plt.xlabel('z')
plt.ylabel('確率密度')
plt.title('X + Y の確率密度関数')
plt.legend()
plt.grid(True)
plt.show()
2021 Q1(1)(2)
指数分布と一様分布の期待値と、それらが独立な場合の積の期待値を求めました。
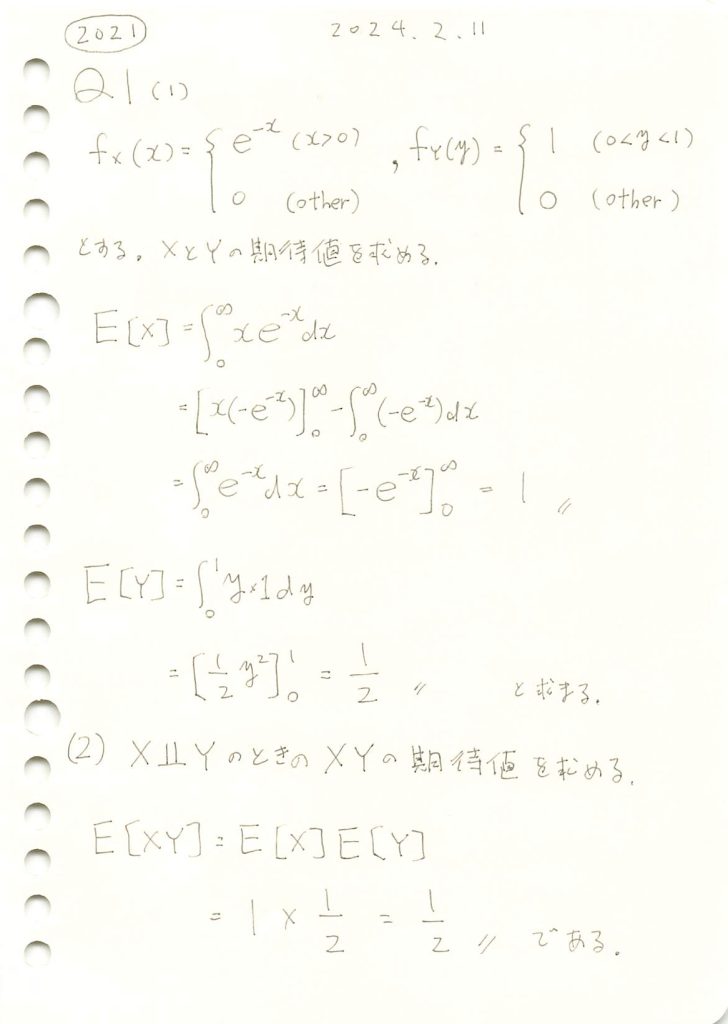
コード
数式を使った計算
# 2021 Q1(1)(2) 2024.8.18
import numpy as np
from scipy.integrate import quad
# Xの期待値の計算
def fx(x):
return x * np.exp(-x)
E_X, _ = quad(fx, 0, np.inf)
# Yの期待値の計算
def fy(y):
return y
E_Y, _ = quad(fy, 0, 1)
# XYの期待値の計算(独立の場合)
E_XY = E_X * E_Y
print(f"E[X] = {E_X}")
print(f"E[Y] = {E_Y}")
print(f"E[XY] (独立の場合) = {E_XY}")
E[X] = 0.9999999999999998
E[Y] = 0.5
E[XY] (独立の場合) = 0.4999999999999999シミュレーションによる計算
# 2021 Q1(1)(2) 2024.8.18
import numpy as np
# シミュレーションの設定
num_samples = 1000000 # サンプル数
# Xの乱数生成(指数分布)
X_samples = np.random.exponential(scale=1.0, size=num_samples)
# Yの乱数生成(一様分布)
Y_samples = np.random.uniform(0, 1, size=num_samples)
# (1) XとYの期待値の計算
E_X_simulation = np.mean(X_samples)
E_Y_simulation = np.mean(Y_samples)
# (2) XYの期待値の計算(独立な場合)
E_XY_simulation = np.mean(X_samples * Y_samples)
print(f"E[X] = {E_X_simulation}")
print(f"E[Y] = {E_Y_simulation}")
print(f"E[XY] = {E_XY_simulation}")
E[X] = 1.0001064255963075
E[Y] = 0.4998284579940602
E[XY] = 0.49980383195826882022 Q4(4)
対数で変数変換した場合の分布を求めました。
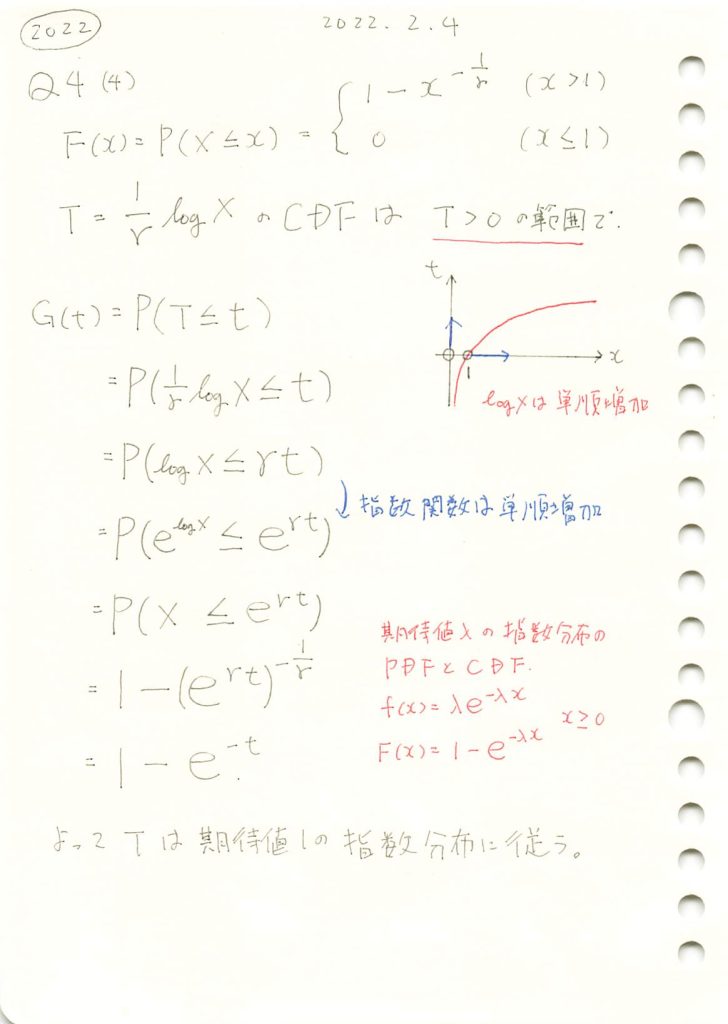
コード
数式を使った計算
# 2022 Q4(4) 2024.8.11
import sympy as sp
# シンボリック変数の定義
t, gamma = sp.symbols('t gamma', positive=True)
x = sp.symbols('x', real=True, positive=True)
# 累積分布関数 F_X(x) の定義
F_X = sp.Piecewise((0, x <= 1), (1 - x**(-1/gamma), x > 1))
# F_T(t) の計算
F_T = F_X.subs(x, sp.exp(gamma * t))
# f_T(t) の計算(F_T(t) を t で微分)
f_T = sp.diff(F_T, t)
# 結果の表示
display(F_T, f_T)
# LaTeXで表示できなときは、こちら
#sp.pprint(F_T, use_unicode=True)
#sp.pprint(f_T, use_unicode=True)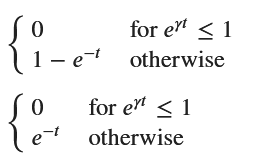
シミュレーションによる計算
# 2022 Q4(4) 2024.8.11
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
# パラメータ設定
gamma = 1.0 # γの値(例えば1)
num_samples = 10000 # サンプルサイズ
# 累積分布関数 F(x) に従う乱数を生成
X = (np.random.uniform(size=num_samples))**(-gamma)
# T = (1/γ) * log(X) の計算
T = (1/gamma) * np.log(X)
# ヒストグラムをプロット
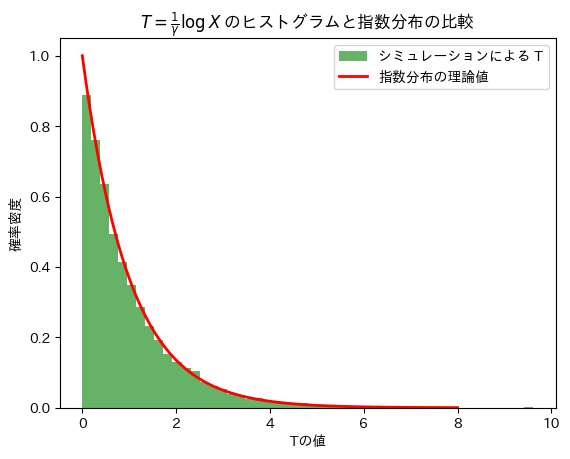
plt.hist(T, bins=50, density=True, alpha=0.6, color='g', label="シミュレーションによる T")
# 理論的な指数分布の密度関数をプロット
x = np.linspace(0, 8, 100)
pdf = stats.expon.pdf(x) # 指数分布(λ=1)の密度関数
plt.plot(x, pdf, 'r-', lw=2, label='指数分布の理論値')
# グラフの設定(日本語でキャプションとラベルを設定)
plt.xlabel('Tの値')
plt.ylabel('確率密度')
plt.title(r'$T = \frac{1}{\gamma} \log X$ のヒストグラムと指数分布の比較')
plt.legend()
plt.show()