2018 Q3(3)
二項分布の条件付き期待値と分散を求めました。

コード
条件付きと条件がついていない場合でシミュレーションし期待値と分散がどのように異なるのか確認します。まずn=10とします。
# 2018 Q3(3) 2024.10.15
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
n = 10 # 試行回数
theta = 0.5 # 成功確率
num_simulations = 100000 # シミュレーション回数
# 二項分布のサンプリング
binom_samples = np.random.binomial(n, theta, num_simulations)
# 条件 X >= 1 を満たすサンプルを抽出
samples_X_geq_1 = binom_samples[binom_samples >= 1]
# 条件付き期待値と条件付き分散のシミュレーションによる計算
simulated_mean = np.mean(samples_X_geq_1)
simulated_variance = np.var(samples_X_geq_1)
# 条件なしの期待値と分散のシミュレーションによる計算
unconditional_simulated_mean = np.mean(binom_samples)
unconditional_simulated_variance = np.var(binom_samples)
# 理論値の計算
theoretical_mean = n * theta / (1 - (1 - theta) ** n)
theoretical_variance = (
(n * theta * (1 - theta)) / (1 - (1 - theta) ** n)
- (n ** 2 * theta ** 2 * (1 - theta) ** n) / (1 - (1 - theta) ** n) ** 2
)
# 条件なしの理論期待値と分散
unconditional_theoretical_mean = n * theta
unconditional_theoretical_variance = n * theta * (1 - theta)
# 結果を表示
print(f"シミュレーションによる条件付き期待値: {simulated_mean}")
print(f"理論上の条件付き期待値: {theoretical_mean}")
print(f"シミュレーションによる条件付き分散: {simulated_variance}")
print(f"理論上の条件付き分散: {theoretical_variance}")
print(f"シミュレーションによる条件なし期待値: {unconditional_simulated_mean}")
print(f"理論上の条件なし期待値: {unconditional_theoretical_mean}")
print(f"シミュレーションによる条件なし分散: {unconditional_simulated_variance}")
print(f"理論上の条件なし分散: {unconditional_theoretical_variance}")
# ヒストグラムの描画
plt.hist(samples_X_geq_1, bins=np.arange(1, n + 2) - 0.5, density=True, alpha=0.6, color='blue', edgecolor='black', label='条件付き (X >= 1)')
plt.hist(binom_samples, bins=np.arange(0, n + 2) - 0.5, density=True, alpha=0.4, color='green', edgecolor='black', label='条件なし')
# 理論値を折れ線グラフで表示
x_values = np.arange(0, n + 1)
binom_pmf = np.array([np.math.comb(n, x) * theta**x * (1 - theta)**(n - x) for x in x_values])
conditional_pmf = binom_pmf[1:] / (1 - binom_pmf[0]) # 条件付きのPMF
plt.plot(x_values[1:], conditional_pmf, marker='x', linestyle='-', color='red', label='条件付き理論値')
plt.plot(x_values, binom_pmf, marker='o', linestyle='-', color='purple', label='条件なし理論値')
# グラフの描画
plt.xlabel("X の値", fontsize=12)
plt.ylabel("確率密度", fontsize=12)
plt.title("条件付きと条件なしの二項分布のシミュレーション", fontsize=14)
plt.legend()
plt.grid(True)
plt.show()シミュレーションによる条件付き期待値: 5.00641686604667
理論上の条件付き期待値: 5.004887585532747
シミュレーションによる条件付き分散: 2.4896127535349235
理論上の条件付き分散: 2.4779819766102995
シミュレーションによる条件なし期待値: 5.00106
理論上の条件なし期待値: 5.0
シミュレーションによる条件なし分散: 2.5137388763999997
理論上の条件なし分散: 2.5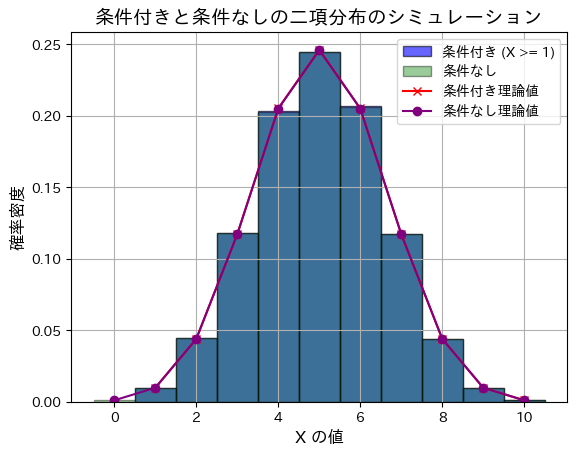
条件付きと条件がついていない場合では、分布はほとんど同じになります。
次に、n=4にすると
シミュレーションによる条件付き期待値: 2.130760208977503
理論上の条件付き期待値: 2.1333333333333333
シミュレーションによる条件付き分散: 0.7789354600394489
理論上の条件付き分散: 0.7822222222222222
シミュレーションによる条件なし期待値: 1.99844
理論上の条件なし期待値: 2.0
シミュレーションによる条件なし分散: 0.9949975664
理論上の条件なし分散: 1.0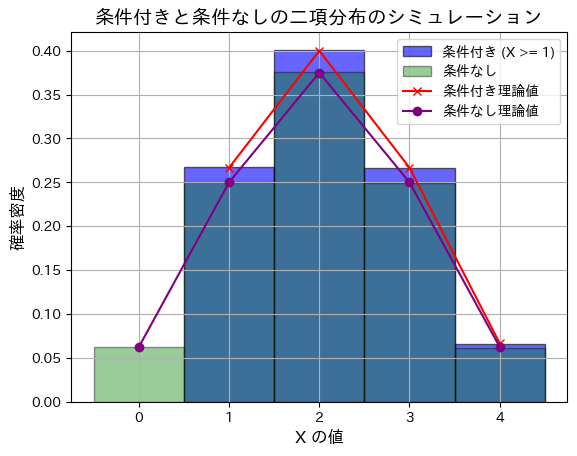
条件付きと条件がついていない場合で、分布の違いが見えてきました。
次に、n=を1から10に変化させて、条件付きと条件がついていない場合の期待値を見てみます。
# 2018 Q3(3) 2024.10.15
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
theta = 0.5 # 成功確率(固定)
n_values = np.arange(1, 11, 1) # nの値を1から10まで1刻みで変化させる
num_simulations = 100000 # シミュレーション回数
simulated_means = [] # 条件付き期待値のシミュレーション結果
theoretical_means = [] # 条件付き理論期待値
unconditional_means_sim = [] # 条件なしの期待値のシミュレーション結果
unconditional_means_theory = [] # 条件なしの理論期待値
# nを変化させてシミュレーション
for n in n_values:
# 二項分布のサンプリング
binom_samples = np.random.binomial(n, theta, num_simulations)
samples_X_geq_1 = binom_samples[binom_samples >= 1] # X >= 1 の条件に絞る
# シミュレーションによる条件付き期待値
simulated_mean = np.mean(samples_X_geq_1)
simulated_means.append(simulated_mean)
# 条件付き理論期待値
theoretical_mean = n * theta / (1 - (1 - theta) ** n)
theoretical_means.append(theoretical_mean)
# 条件なしの期待値のシミュレーション結果
unconditional_mean_sim = np.mean(binom_samples)
unconditional_means_sim.append(unconditional_mean_sim)
# 条件なしの理論期待値
unconditional_mean_theory = n * theta
unconditional_means_theory.append(unconditional_mean_theory)
# シミュレーション結果と理論値をプロット
plt.plot(n_values, simulated_means, label="条件付きシミュレーション", marker='o', linestyle='--', color='blue')
plt.plot(n_values, theoretical_means, label="条件付き理論値", marker='x', linestyle='-', color='red')
plt.plot(n_values, unconditional_means_sim, label="条件なしシミュレーション", marker='^', linestyle='--', color='purple')
plt.plot(n_values, unconditional_means_theory, label="条件なし理論値", marker='s', linestyle='-', color='green')
# グラフの描画
plt.xlabel("試行回数 n", fontsize=12)
plt.ylabel("期待値 E[X]", fontsize=12)
plt.title("n の変化に対する期待値の比較 (θ = 0.5)", fontsize=14)
plt.legend()
plt.grid(True)
plt.show()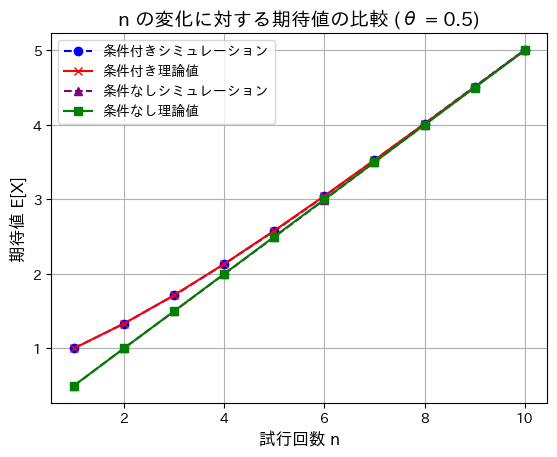
nが増加するほど、条件付きと条件がついていない場合の期待値の差は小さくなります。
分散も同様に確認します。
# 2018 Q3(3) 2024.10.15
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
theta = 0.5 # 成功確率(固定)
n_values = np.arange(1, 11, 1) # nの値を1から10まで1刻みで変化させる
num_simulations = 100000 # シミュレーション回数
simulated_variances = [] # 条件付き分散のシミュレーション結果
theoretical_variances = [] # 条件付き理論分散
unconditional_variances_sim = [] # 条件なしの分散のシミュレーション結果
unconditional_variances_theory = [] # 条件なしの理論分散
# nを変化させてシミュレーション
for n in n_values:
# 二項分布のサンプリング
binom_samples = np.random.binomial(n, theta, num_simulations)
samples_X_geq_1 = binom_samples[binom_samples >= 1] # X >= 1 の条件に絞る
# シミュレーションによる条件付き分散
simulated_variance = np.var(samples_X_geq_1)
simulated_variances.append(simulated_variance)
# 条件付き理論分散
theoretical_variance = (
(n * theta * (1 - theta)) / (1 - (1 - theta) ** n)
- (n ** 2 * theta ** 2 * (1 - theta) ** n) / (1 - (1 - theta) ** n) ** 2
)
theoretical_variances.append(theoretical_variance)
# 条件なしの分散のシミュレーション結果
unconditional_variance_sim = np.var(binom_samples)
unconditional_variances_sim.append(unconditional_variance_sim)
# 条件なしの理論分散
unconditional_variance_theory = n * theta * (1 - theta)
unconditional_variances_theory.append(unconditional_variance_theory)
# シミュレーション結果と理論値をプロット
plt.plot(n_values, simulated_variances, label="条件付きシミュレーション", marker='o', linestyle='--', color='blue')
plt.plot(n_values, theoretical_variances, label="条件付き理論値", marker='x', linestyle='-', color='red')
plt.plot(n_values, unconditional_variances_sim, label="条件なしシミュレーション", marker='^', linestyle='--', color='purple')
plt.plot(n_values, unconditional_variances_theory, label="条件なし理論値", marker='s', linestyle='-', color='green')
# グラフの描画
plt.xlabel("試行回数 n", fontsize=12)
plt.ylabel("分散 V[X]", fontsize=12)
plt.title("n の変化に対する分散の比較 (θ = 0.5)", fontsize=14)
plt.legend()
plt.grid(True)
plt.show()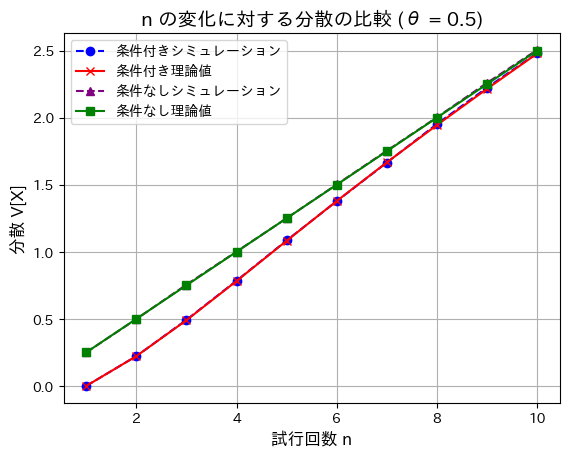
分散も同様に、nが増加するほど差は小さくなりました。
2018 Q3(2)
二項分布の条件付き確率質量関数を求めました。

コード
条件付き二項分布のシミュレーションを行い理論値と一致するか確認します。
# 2018 Q3(2) 2024.10.12
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
n = 10 # 試行回数
theta = 0.5 # 成功確率
num_simulations = 10000 # シミュレーション回数
# 二項分布に従うランダム変数を生成
binom_samples = np.random.binomial(n, theta, num_simulations)
# X >= 1 の条件を満たすサンプルを抽出
samples_X_geq_1 = binom_samples[binom_samples >= 1]
# X = x の回数を数える
counts, _ = np.histogram(samples_X_geq_1, bins=np.arange(n+2))
# シミュレーションによる条件付き確率(X = 1 から n の範囲で計算)
simulated_probabilities = counts[1:] / np.sum(counts)
# 理論上の条件付き確率 h(x)
x_values = np.arange(1, n+1)
binom_pmf = np.array([np.math.comb(n, x) * theta**x * (1-theta)**(n-x) for x in x_values])
theoretical_probabilities = binom_pmf / (1 - (1 - theta)**n)
# シミュレーション結果をヒストグラムで表示
plt.bar(x_values, simulated_probabilities, color='blue', alpha=0.6, label="シミュレーション")
plt.plot(x_values, theoretical_probabilities, label="理論値", marker='x', linestyle='-', color='red')
# グラフの描画
plt.xlabel("X の値", fontsize=12)
plt.ylabel("条件付き確率 P(X = x | X >= 1)", fontsize=12)
plt.title(f"条件付き確率のシミュレーションと理論値の比較 (n={n}, θ={theta})", fontsize=14)
plt.legend()
plt.grid(True)
plt.show()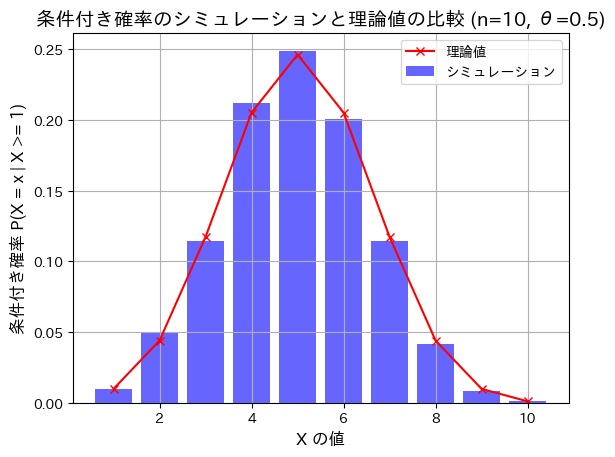
シミュレーションによる結果と理論値が一致しました。
2018 Q3(1)
二項分布の期待値と分散を求めました。
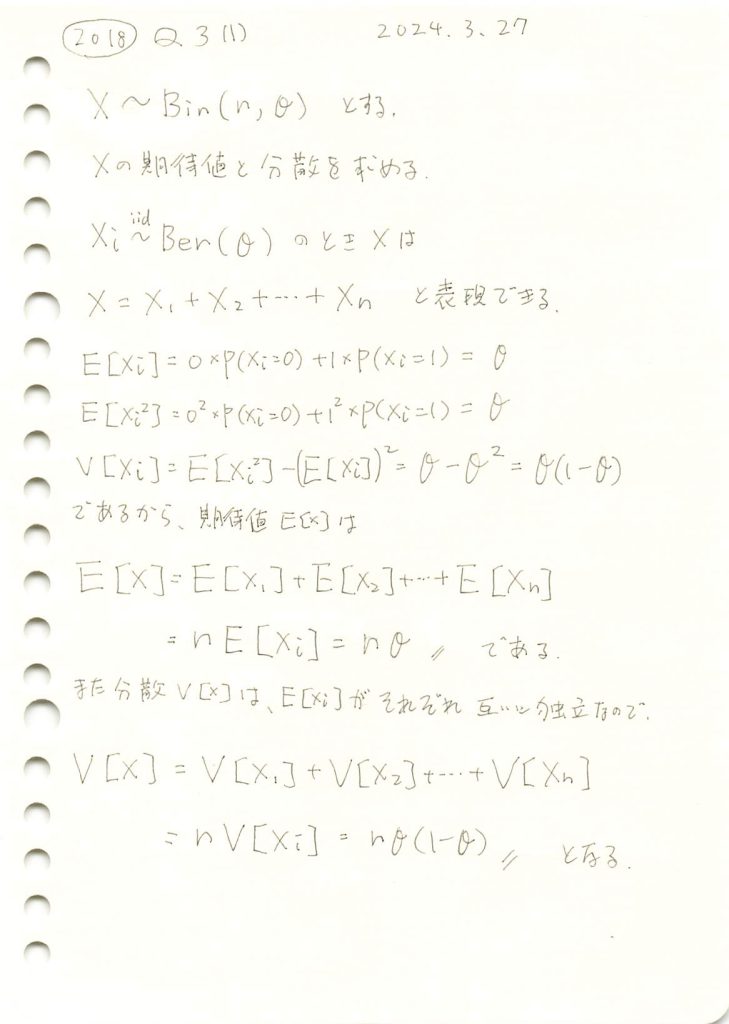
コード
ベルヌーイ試行による二項分布のシミュレーションを行い二項分布の期待値と分散を求めます。
# 2018 Q3(1) 2024.10.11
import numpy as np
import matplotlib.pyplot as plt
# パラメータ
n = 10 # 試行回数
theta = 0.5 # 成功確率
num_simulations = 10000 # シミュレーションの回数
# シミュレーションを実行
bernoulli_trials = np.random.binomial(1, theta, (num_simulations, n))
# 各シミュレーションでの X = X1 + X2 + ... + Xn を計算
X_values = np.sum(bernoulli_trials, axis=1)
# 期待値と分散を計算
simulated_mean = np.mean(X_values)
simulated_variance = np.var(X_values)
# 理論値
theoretical_mean = n * theta
theoretical_variance = n * theta * (1 - theta)
# 結果を表示
print(f"シミュレーションによる期待値: {simulated_mean}")
print(f"理論上の期待値: {theoretical_mean}")
print(f"シミュレーションによる分散: {simulated_variance}")
print(f"理論上の分散: {theoretical_variance}")
# ヒストグラムを描画
plt.hist(X_values, bins=np.arange(n+2)-0.5, density=True, alpha=0.75, color='blue', edgecolor='black')
plt.title("ベルヌーイ試行による二項分布のシミュレーション")
plt.xlabel("Xの値 (成功回数)")
plt.ylabel("確率")
plt.show()シミュレーションによる期待値: 4.9827
理論上の期待値: 5.0
シミュレーションによる分散: 2.54300071
理論上の分散: 2.5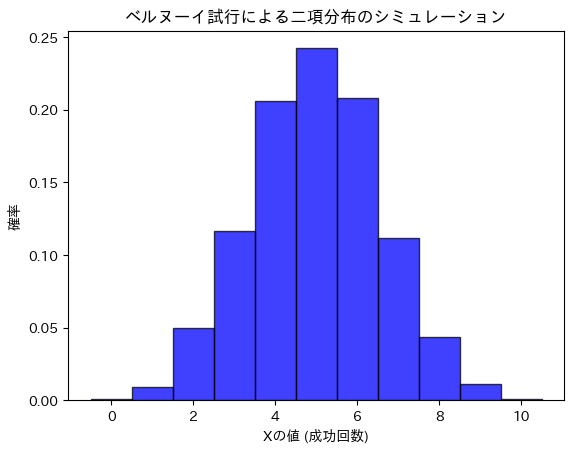
シミュレーションによる結果と理論値が一致しました。
2019 Q1(3)
確率母関数の不等式を証明する問題をやりました。

コード
不等式 を可視化して確認しました。ここでは二項分布で試しています。
を可視化して確認しました。ここでは二項分布で試しています。
# 2019 Q1(3) 2024.9.11
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
n = 10 # 二項分布の試行回数
p = 0.5 # 二項分布の成功確率
t_values = [0.001, 0.2, 0.4, 0.6, 0.8, 1] # t の値のリスト
sample_size = 10000 # サンプル数
r_values = np.arange(0, n+1, 1) # r の範囲を設定
# 確率母関数 G_X(t) の定義
def G_X(t, n, p):
return (p * t + (1 - p))**n
# 1. 二項分布から乱数を生成
samples = np.random.binomial(n, p, sample_size)
# 2. r に対する P(X <= r) の推定(左辺)
P_X_leq_r_values = [np.sum(samples <= r) / sample_size for r in r_values]
# サブプロットの作成
fig, axes = plt.subplots(2, 3, figsize=(15, 8)) # 2行3列のサブプロットを作成
# 3. 各 t に対するグラフを描画
for i, t in enumerate(t_values):
row = i // 3 # 行番号
col = i % 3 # 列番号
# 右辺 t^{-r} G_X(t) の計算
G_X_value = G_X(t, n, p) # 確率母関数の t 固定
right_hand_side_values = [G_X_value if t == 1 else t**(-r) * G_X_value for r in r_values] # t = 1 の場合はべき乗を回避
# グラフの描画
ax = axes[row, col]
ax.plot(r_values, P_X_leq_r_values, label="P(X <= r) (左辺)", color="blue", linestyle="--")
ax.plot(r_values, right_hand_side_values, label="t^(-r) G_X(t) (右辺)", color="red")
ax.set_title(f"t = {t}")
ax.set_xlabel("r")
ax.set_ylabel("値 (対数スケール)")
ax.set_yscale('log') # 縦軸を対数スケールに設定
ax.legend()
ax.grid(True, which="both", ls="--")
# サブプロット間のレイアウト調整
plt.tight_layout()
plt.show()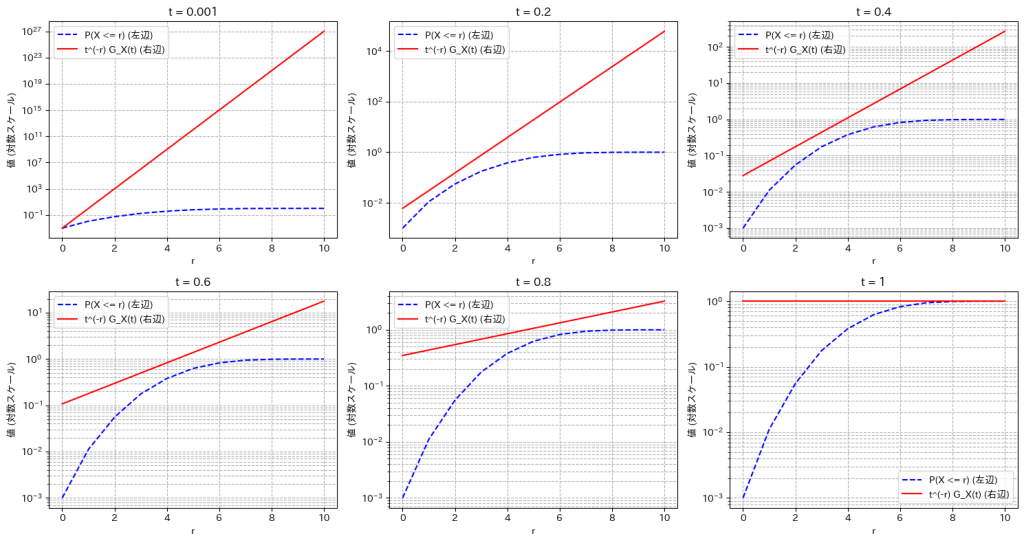
不等式が成り立っていることが確認できました
2019 Q1(2)
二項分布の確率母関数を求め、期待値と分散を算出しました。
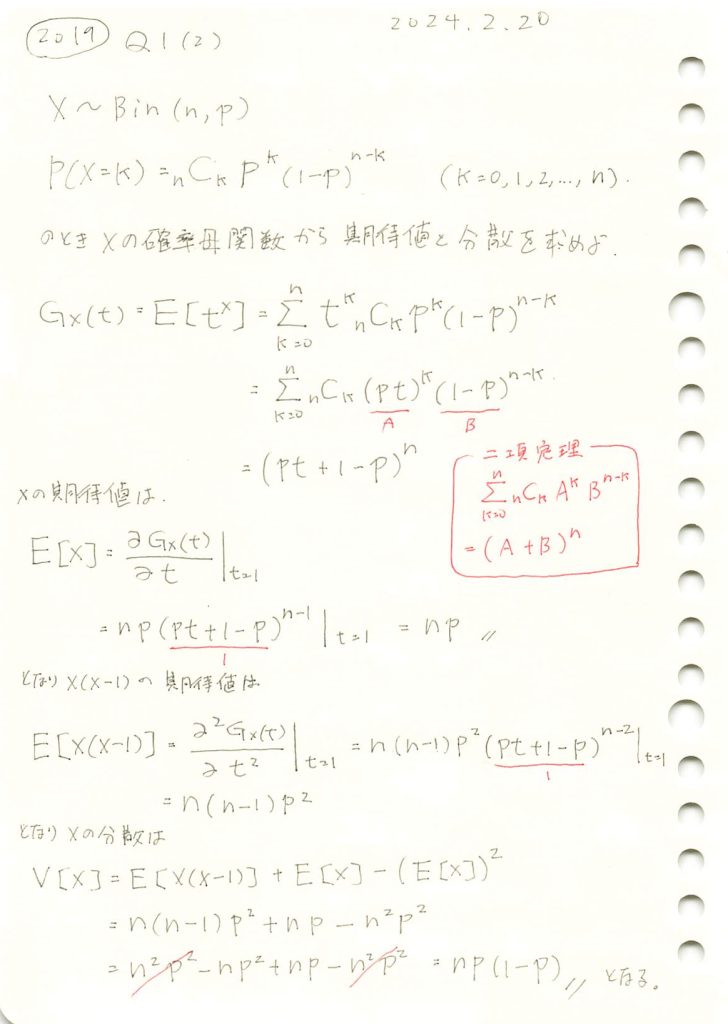
コード
非負の離散型観測データから確率母関数を構築し、これの微分と2階微分から期待値と分散を求めます。ここでは、観測データとして二項分布の乱数を用いて、その理論的な母関数と期待値と分散の比較を行います。
# 2019 Q1(2) 2024.9.10
import numpy as np
import matplotlib.pyplot as plt
from scipy.misc import derivative
# パラメータ設定
n = 10 # 試行回数
p = 0.5 # 成功確率
sample_size = 10000 # サンプル数
# 1. 二項分布に従う乱数データを生成
samples = np.random.binomial(n, p, sample_size)
# 2. P(X=k) の推定(サンプル度数から確率質量関数の推定)
max_k = np.max(samples)
pmf_estimate = np.zeros(max_k + 1)
for k in range(max_k + 1):
pmf_estimate[k] = np.sum(samples == k) / sample_size
# 3. G_X(t) の推定
def G_X(t):
return np.sum([pmf_estimate[k] * t**k for k in range(max_k + 1)])
# 4. 理論的な G_X(t) (二項分布の確率母関数)
def G_X_theoretical(t, n, p):
return (p * t + (1 - p))**n
# 5. G_X(t) のプロット
t_values = np.linspace(0, 1, 100)
G_X_values = [G_X(t) for t in t_values]
G_X_theoretical_values = [G_X_theoretical(t, n, p) for t in t_values]
plt.plot(t_values, G_X_values, label="推定された G_X(t)", color="blue")
plt.plot(t_values, G_X_theoretical_values, label="理論的な G_X(t)", linestyle='--', color="red")
plt.title("推定された確率母関数と理論的な G_X(t) の比較")
plt.xlabel("t")
plt.ylabel("G_X(t)")
plt.legend()
plt.show()
# 6. G_X(t) の微分と2階微分
def G_X_diff_1(t):
return derivative(G_X, t, dx=1e-6)
def G_X_diff_2(t):
return derivative(G_X_diff_1, t, dx=1e-6)
# 7. t = 1 における期待値と分散の推定
E_X_estimated = G_X_diff_1(1) # 期待値
Var_X_estimated = G_X_diff_2(1) + E_X_estimated - E_X_estimated**2 # 分散
# 結果の出力
print(f"推定された期待値 E[X]: {E_X_estimated}")
print(f"推定された分散 Var(X): {Var_X_estimated}")
# 真の期待値と分散を計算
E_X_true = n * p
Var_X_true = n * p * (1 - p)
# 真の期待値と分散を出力
print(f"真の期待値 E[X]: {E_X_true}")
print(f"真の分散 Var(X): {Var_X_true}")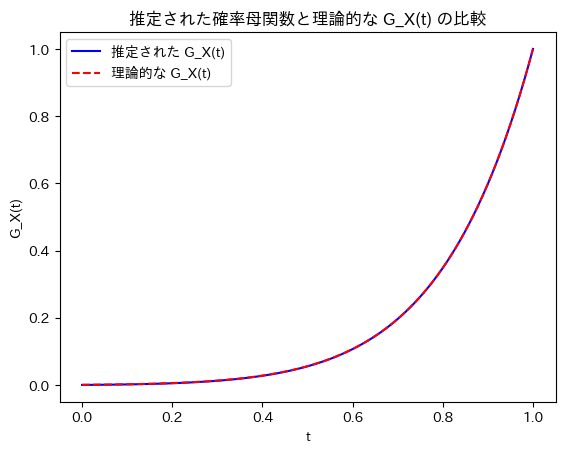
推定された期待値 E[X]: 4.9988999998862305
推定された分散 Var(X): 2.4964947096596752
真の期待値 E[X]: 5.0
真の分散 Var(X): 2.5観測値から推定された確率母関数は理論的な二項分布の確率母関数と一致しました。また、推定された確率母関数から計算された期待値と分散も、真の値に非常に近い結果となりました。
次に、二項分布の確率母関数 、その1階微分
、その1階微分  、および2階微分
、および2階微分  を視覚的に比較してみます。
を視覚的に比較してみます。
# 2019 Q1(2) 2024.9.10
import numpy as np
import matplotlib.pyplot as plt
from scipy.misc import derivative
# パラメータ設定
n = 10 # 試行回数
p = 0.5 # 成功確率
# 確率母関数 G_X(t)
def G_X(t, n, p):
return (p * t + (1 - p))**n
# 1階微分 G'_X(t)
def G_X_diff_1(t, n, p):
return derivative(lambda t: G_X(t, n, p), t, dx=1e-6)
# 2階微分 G''_X(t)
def G_X_diff_2(t, n, p):
return derivative(lambda t: G_X_diff_1(t, n, p), t, dx=1e-6)
# t の範囲を定義
t_values = np.linspace(0, 1, 100)
# G_X(t), G'_X(t), G''_X(t) の値を計算
G_X_values = [G_X(t, n, p) for t in t_values]
G_X_diff_1_values = [G_X_diff_1(t, n, p) for t in t_values]
G_X_diff_2_values = [G_X_diff_2(t, n, p) for t in t_values]
# グラフの描画
plt.plot(t_values, G_X_values, label="G_X(t) (確率母関数)", color="blue")
plt.plot(t_values, G_X_diff_1_values, label="G'_X(t) (1階微分)", color="green")
plt.plot(t_values, G_X_diff_2_values, label="G''_X(t) (2階微分)", color="red")
plt.title(f"G_X(t), G'_X(t), G''_X(t) の比較 (n={n}, p={p})")
plt.xlabel("t")
plt.ylabel("値")
plt.legend()
plt.grid(True)
plt.show()
微分を重ねるごとにt=1付近での傾きが急になり大きな値を取っています。期待値や分散などの高次統計量に関連しているため、その値が大きくなっていると思います。
2021 Q3(2)[2-2]
ポアソン分布に従う独立な変数の和はパラメータλの十分統計量であることを学びました。
あとがき
 の式で示すと簡単。
の式で示すと簡単。
コード
ポアソン分布に従う10個の乱数の和 Tの分布を見てみます。
# 2024 Q3(2)[2-2] 2024.8.27
import numpy as np
import matplotlib.pyplot as plt
# パラメータの設定
lambda_value = 5 # 真のパラメータ
n = 10 # サンプル数
num_simulations = 1000000 # シミュレーション回数
# ポアソン分布に従う n 個のサンプルを生成
samples = np.random.poisson(lambda_value, (num_simulations, n))
# 和 T を計算
T = np.sum(samples, axis=1)
# 和 T のヒストグラムをプロット
plt.hist(T, bins=30, density=True, alpha=0.75, color='blue')
plt.title(f'Tの分布 (n 個のポアソン変数の和)')
plt.xlabel('T')
plt.ylabel('確率密度')
plt.grid(True)
plt.show()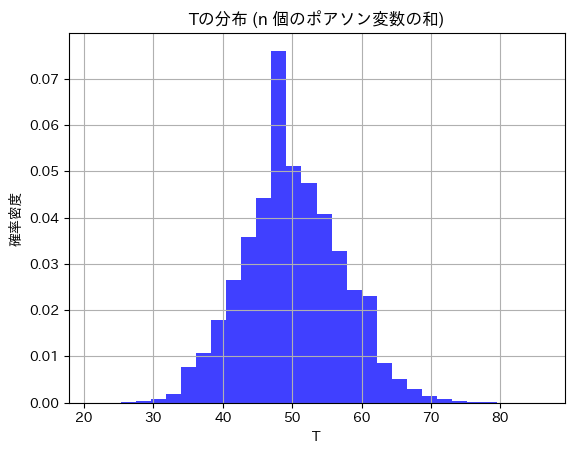
T~Po(nλ)になっています。
つぎにT=50の条件下での確率変数X1の分布を見てます。
# 2024 Q3(2)[2-2] 2024.8.27
import numpy as np
import matplotlib.pyplot as plt
# 条件付き分布の確認
# 例えば、T = 50 の場合におけるサンプルの分布を確認
T_value = 50 # T の特定の値
samples_given_T = samples[np.sum(samples, axis=1) == T_value]
# 確率変数の1つ (X1) の分布をプロット
plt.hist(samples_given_T[:, 0], bins=15, density=True, alpha=0.75, color='green')
plt.title(f'T={T_value} の条件付き X1 の分布')
plt.xlabel('X1')
plt.ylabel('確率密度')
plt.grid(True)
plt.show()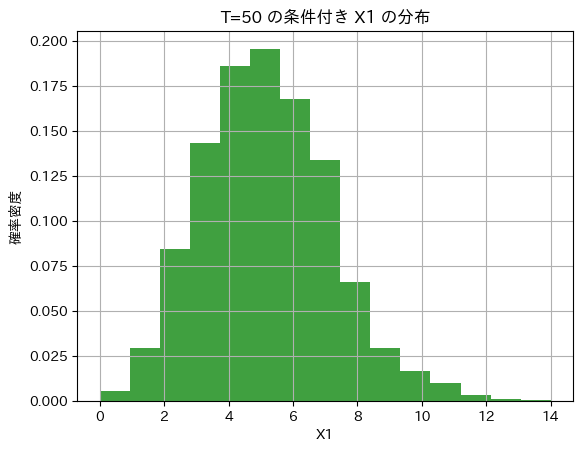
二項分布に従っているようです。
異なるλに対して、和T=50の条件下でのX1の分布を重ねて見てます。
# 2024 Q3(2)[2-2] 2024.8.27
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import binom
# パラメータ設定
lambda_values = [3, 5, 7] # 異なる λ の値
n = 10 # サンプル数
num_simulations = 1000000 # シミュレーション回数
T_value = 50 # T の特定の値
plt.figure(figsize=(12, 6))
for lambda_value in lambda_values:
# ポアソン分布に従う n 個のサンプルを生成
samples = np.random.poisson(lambda_value, (num_simulations, n))
# T = T_value のサンプルを抽出
samples_given_T = samples[np.sum(samples, axis=1) == T_value]
# X1 の分布をプロット
counts, bin_edges, _ = plt.hist(samples_given_T[:, 0], bins=15, density=True, alpha=0.5, label=f'λ = {lambda_value}')
# 理論二項分布を描画
x1_min, x1_max = np.min(samples_given_T[:, 0]), np.max(samples_given_T[:, 0])
x = np.arange(x1_min, x1_max + 1)
estimated_p = 1 / n # 二項分布の p は 1/n で推定
binom_pmf = binom.pmf(x, T_value, estimated_p)
plt.plot(x, binom_pmf, 'k--', label=f'理論二項分布 Bin(T={T_value}, p=1/{n})')
plt.title(f'X1の分布 (T={T_value} 条件付き) と理論二項分布')
plt.xlabel('X1')
plt.ylabel('確率密度')
plt.legend()
plt.grid(True)
plt.show()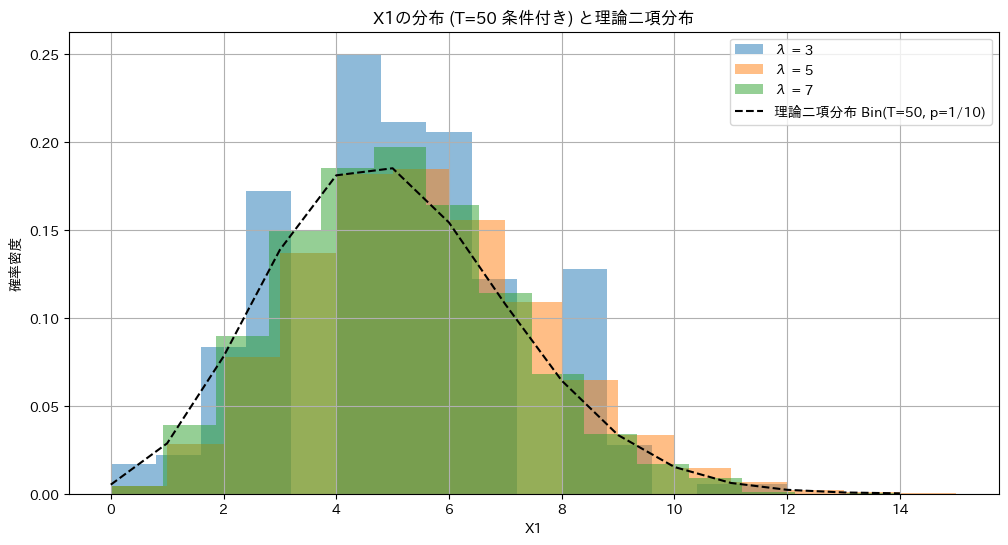
λに依存せず同じ二項分布に従います。よって統計量Tはλに対する十分統計量であることが示されました。
なお、X1~Xnの組は多項分布に従うが、簡単のためX1のみの分布を確認しました。X1は二項分布に従います。