ホーム » コードあり (ページ 5)
「コードあり」カテゴリーアーカイブ
2015 Q2(3)
標本平均の片側検定での検出力を求め、母平均と検出力の関係を描きました。

コード
有意水準 α=0.05、サンプルサイズ n=9およびn=16の場合における検出力を真の平均 μを変化させて視覚化します。また、μ=0.4,0.8での検出力を計算します。
# 2015 Q2(3) 2024.12.9
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 定義
alpha = 0.05 # 有意水準
z_alpha = norm.ppf(1 - alpha) # 臨界値 z_alpha
sample_sizes = [9, 16] # n = 9, 16
true_means = [0.4, 0.8] # 真の平均 μ = 0.4, 0.8
# 検出力の計算関数
def compute_power(mu, n, z_alpha):
z_value = z_alpha - mu * np.sqrt(n)
power = 1 - norm.cdf(z_value)
return power
# 検出力を計算
mu_values = np.linspace(0, 1.5, 100) # 真の平均 μ の範囲
powers_n9 = [compute_power(mu, n=9, z_alpha=z_alpha) for mu in mu_values]
powers_n16 = [compute_power(mu, n=16, z_alpha=z_alpha) for mu in mu_values]
# 指定された μ = 0.4, 0.8 の検出力を計算
specific_powers = {
(n, mu): compute_power(mu, n, z_alpha)
for n in sample_sizes
for mu in true_means
}
# グラフの描画
plt.figure(figsize=(10, 6))
plt.plot(mu_values, powers_n9, label="検出力 (n=9)", linestyle="--", color="blue")
plt.plot(mu_values, powers_n16, label="検出力 (n=16)", linestyle="-", color="green")
# μ = 0.4, 0.8 の場合の検出力をプロット
for (n, mu), power in specific_powers.items():
plt.scatter(mu, power, label=f"n={n}, μ={mu}, Power={power:.2f}", zorder=5)
# グラフの設定
plt.xlabel("真の平均 $\\mu$", fontsize=12)
plt.ylabel("検出力 (Power)", fontsize=12)
plt.title("検出力の挙動 ($n=9$ および $n=16$ の場合)", fontsize=14)
plt.axhline(y=alpha, color="red", linestyle=":", label=f"有意水準 α={alpha}")
plt.legend()
plt.grid(True)
plt.show()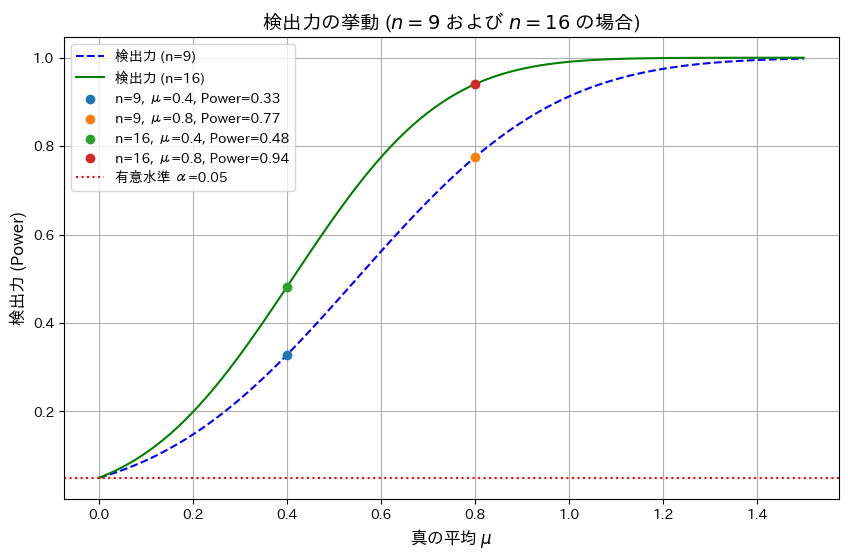
シミュレーションの結果、サンプルサイズnが増加することで検出力が向上することと、真の平均μが大きくなるほど検出力が1に近づくことが分かりました。
2015 Q2(2)
P値が有意水準より小さくなることと、観測値が棄却域より大きくなることが同等である事を示しました。

コード
標本平均 が棄却域に入る条件と、P値が有意水準 α以下となる条件が一致することをシミュレーションで確認します。
が棄却域に入る条件と、P値が有意水準 α以下となる条件が一致することをシミュレーションで確認します。
# 2015 Q2(2) 2024.12.8
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# シミュレーション設定
n = 10 # 標本サイズ
mu_0 = 0 # 帰無仮説の平均
sigma = 1 # 標準偏差
alpha = 0.05 # 有意水準
num_simulations = 10000 # シミュレーション回数
# z_alpha (有意水準に対応する臨界値)
z_alpha = norm.ppf(1 - alpha)
threshold = z_alpha / np.sqrt(n) # 棄却域の閾値
# シミュレーションで標本平均を生成
samples = np.random.normal(mu_0, sigma, (num_simulations, n))
x_bar = np.mean(samples, axis=1)
# 棄却域に入るかどうかを確認
in_rejection_region = x_bar > threshold
# P値の計算
p_values = 1 - norm.cdf(x_bar * np.sqrt(n) / sigma)
# P値が有意水準以下かどうかを確認
p_value_condition = p_values <= alpha
# 棄却域とP値の条件が一致する割合を計算
agreement_rate = np.mean(in_rejection_region == p_value_condition)
# 棄却域に落ちる割合とP値がα以下になる割合の比較
rejection_rate = np.mean(in_rejection_region)
p_value_rate = np.mean(p_value_condition)
# 結果の出力
print(f"シミュレーション回数: {num_simulations}")
print(f"有意水準 α: {alpha}")
print(f"棄却域条件とP値条件の一致率: {agreement_rate:.3f}")
print(f"棄却域に落ちる割合: {rejection_rate:.3f}")
print(f"P値がα以下になる割合: {p_value_rate:.3f}")
# グラフの描画
plt.figure(figsize=(12, 6))
# 標本平均 x̄ の分布
plt.hist(x_bar, bins=50, color="skyblue", alpha=0.7, edgecolor="black", label="標本平均 $\\bar{X}$ の分布")
plt.axvline(threshold, color="red", linestyle="--", label=f"棄却域の閾値 $z_{{\\alpha}}/\\sqrt{{n}} = {threshold:.3f}$")
plt.fill_betweenx([0, plt.gca().get_ylim()[1]], threshold, plt.gca().get_xlim()[1], color="red", alpha=0.2, label="棄却域")
plt.xlabel("標本平均 $\\bar{X}$", fontsize=12)
plt.ylabel("度数", fontsize=12)
plt.title("標本平均 $\\bar{X}$ の分布と棄却域", fontsize=14)
plt.legend()
plt.grid(True)
plt.show()
# P値の分布
plt.figure(figsize=(12, 6))
plt.hist(p_values, bins=50, color="lightgreen", alpha=0.7, edgecolor="black", label="P値の分布")
plt.axvline(alpha, color="blue", linestyle="--", label=f"有意水準 $\\alpha = {alpha}$")
plt.fill_betweenx([0, plt.gca().get_ylim()[1]], 0, alpha, color="blue", alpha=0.2, label="P値が $\\leq \\alpha$ の領域")
plt.xlabel("P値", fontsize=12)
plt.ylabel("度数", fontsize=12)
plt.title("P値の分布と有意水準", fontsize=14)
plt.legend()
plt.grid(True)
plt.show()
シミュレーション回数: 10000
有意水準 α: 0.05
棄却域条件とP値条件の一致率: 1.000
棄却域に落ちる割合: 0.052
P値がα以下になる割合: 0.052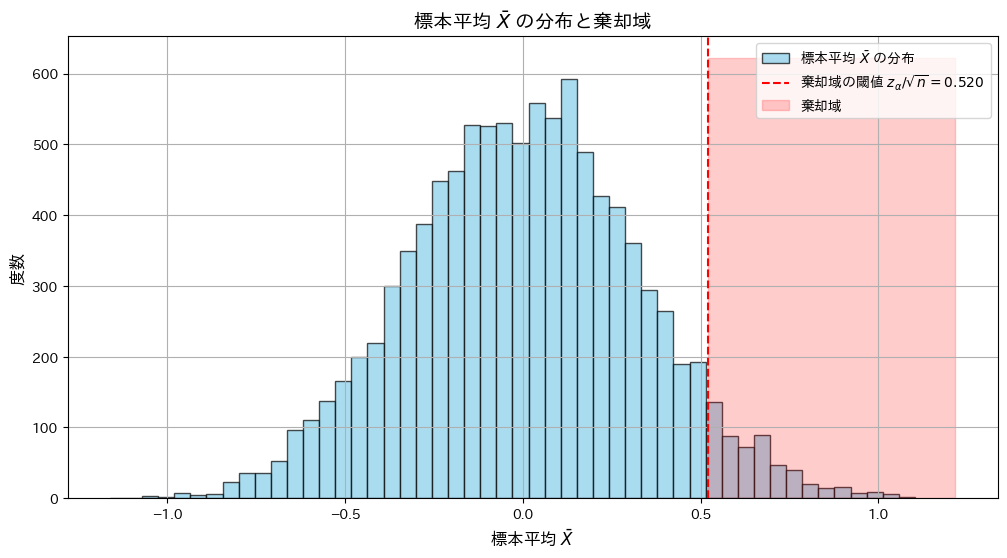
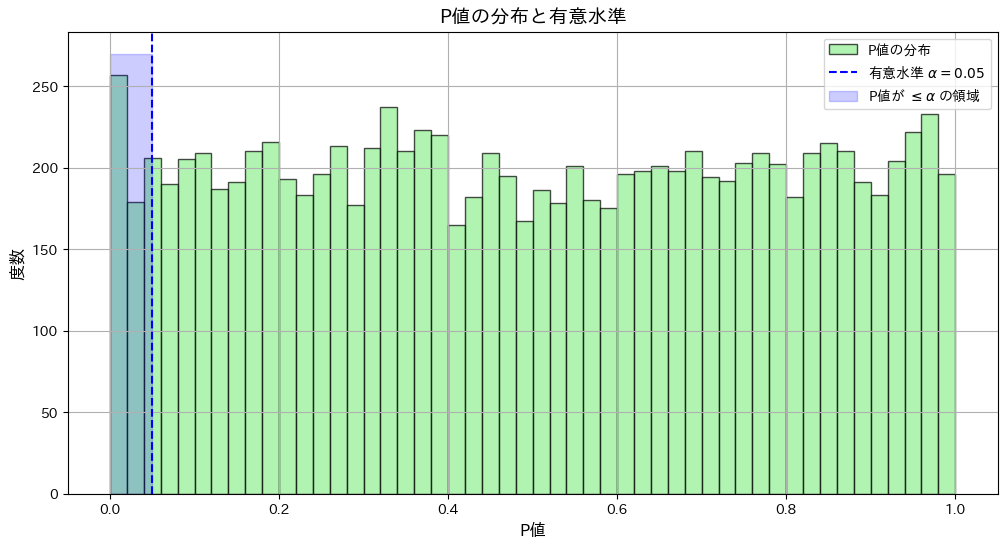
シミュレーションの結果、標本平均が棄却域に入る条件と、P値が有意水準 α以下となる条件が一致しました。
2015 Q2(1)
標本平均とP値の関係をグラフで描きました。

コード
n=10のときの標本平均とP値の関係をグラフで示します。また のP値を計算します。
のP値を計算します。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 問題の設定
n = 10 # サンプルサイズ
mu_0 = 0 # 帰無仮説の平均
sigma = 1 # 分散1なので標準偏差は1
alpha = 0.05 # 有意水準
critical_value = norm.ppf(1 - alpha) # 上側確率100α%点
threshold = critical_value / np.sqrt(n) # 棄却域の閾値
# 標本平均の値
x_bar_values = np.linspace(0, 1, 100) # 標本平均の範囲
p_values = 1 - norm.cdf((x_bar_values - mu_0) * np.sqrt(n)) # P値を計算
# 指定された x̄ = 0.3, 0.6 の場合の P値
x_bar_special = [0.3, 0.6]
p_values_special = 1 - norm.cdf((np.array(x_bar_special) - mu_0) * np.sqrt(n))
# 結果出力
print("指定された標本平均 x̄ に対応する P値:")
for x, p in zip(x_bar_special, p_values_special):
print(f" 標本平均 x̄ = {x:.1f} の場合の P値: {p:.3f}")
# グラフの描画
plt.figure(figsize=(8, 5))
plt.plot(x_bar_values, p_values, label="P値の挙動", color="orange")
plt.axhline(y=alpha, color="red", linestyle="--", label=f"有意水準 α={alpha}")
plt.scatter(x_bar_special, p_values_special, color="blue", label="指定点 (0.3, 0.6)")
for x, p in zip(x_bar_special, p_values_special):
plt.text(x, p, f"({x:.1f}, {p:.3f})", fontsize=10, color="blue")
plt.xlabel("標本平均 $\\bar{x}$", fontsize=12)
plt.ylabel("P値", fontsize=12)
plt.title("P値の挙動 (標本平均 $\\bar{x}$ の範囲)", fontsize=14)
plt.legend()
plt.grid(True)
plt.show()指定された標本平均 x̄ に対応する P値:
標本平均 x̄ = 0.3 の場合の P値: 0.171
標本平均 x̄ = 0.6 の場合の P値: 0.029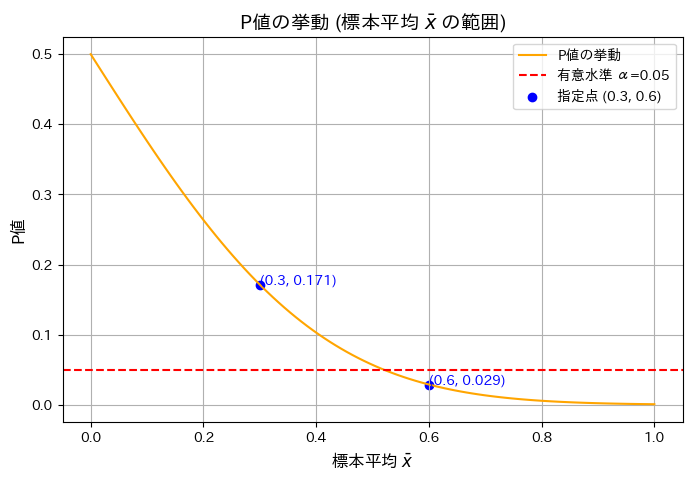
グラフの概形が描けました。標本平均が大きくなるにつれてP値が減少することを確認しました。
2015 Q1(5)
不偏分散の定数C倍を母分散の推定量とし平均二乗誤差を最小とするCを求めました。
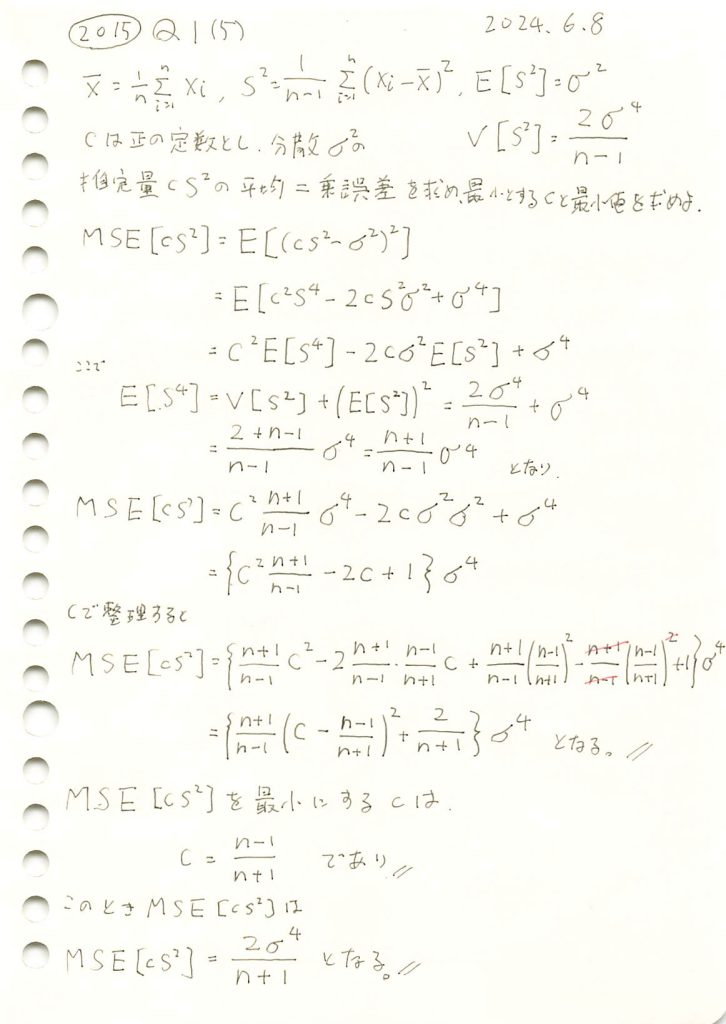
コード
![\text{MSE}[cS^2]](https://statistics.blue/wp-content/ql-cache/quicklatex.com-fd063d11fa9bbd8af614d71270639dbb_l3.png "Rendered by QuickLaTeX.com") を最小にするcが
を最小にするcが であるか確認するため、シミュレーションを行います。n=20の場合において、c≒0.9がMSEの最小になることを検証します。
であるか確認するため、シミュレーションを行います。n=20の場合において、c≒0.9がMSEの最小になることを検証します。
# 2015 Q1(5) 2024.12.6
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
sigma2 = 4 # 母分散
sigma = np.sqrt(sigma2) # 母標準偏差
n = 20 # 標本サイズ
num_simulations = 1000 # シミュレーション回数
# 理論値計算
c_theoretical = (n - 1) / (n + 1) # 理論的に最適な c
mse_theoretical_min = sigma2**2 * (2 / (n + 1)) # 最小 MSE の理論値
# シミュレーションで MSE を計算
c_values = np.linspace(0.5, 1.5, 100) # c をいろいろ変化させる
mse_simulated = []
for c in c_values:
simulated_errors = []
for _ in range(num_simulations):
sample = np.random.normal(0, sigma, n)
s2 = np.var(sample, ddof=1) # 不偏分散
error = (c * s2 - sigma2) ** 2 # 誤差の二乗
simulated_errors.append(error)
mse_simulated.append(np.mean(simulated_errors))
# グラフを描画
plt.figure(figsize=(10, 6))
plt.plot(c_values, mse_simulated, label="シミュレーションによる MSE", color='blue')
plt.axvline(c_theoretical, color='orange', linestyle='--', label=f"理論的な c={c_theoretical:.2f}")
plt.axhline(mse_theoretical_min, color='green', linestyle='--', label=f"最小理論 MSE={mse_theoretical_min:.2f}")
plt.title("MSE のシミュレーションと理論値")
plt.xlabel("c の値")
plt.ylabel("MSE")
plt.legend()
plt.grid()
plt.tight_layout()
plt.show()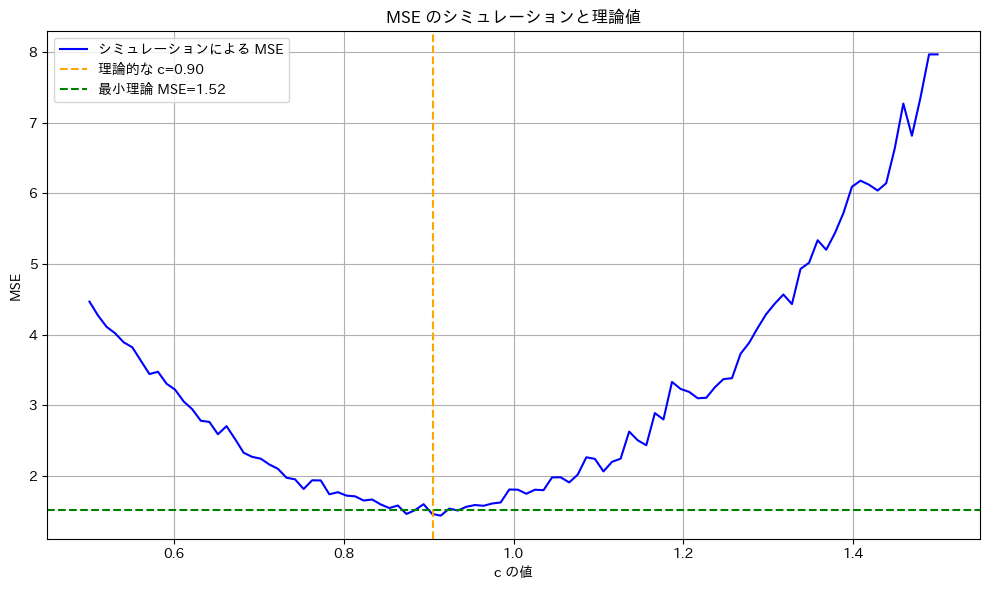
は、n=20の場合において、理論通りc≒0.9のとき最小になることが確認されました。
2015 Q1(4)
不偏分散が母分散の一致推定量であることを確認しました。

コード
 が
が の一致推定量であるか確認するため、
の一致推定量であるか確認するため、![\text{Var}[S^2] = \frac{2\sigma^4}{n - 1}](https://statistics.blue/wp-content/ql-cache/quicklatex.com-0980585e801034ee6b555ed91237e5b3_l3.png "Rendered by QuickLaTeX.com") をシミュレーションし、理論値とともにグラフで確認してみます。
をシミュレーションし、理論値とともにグラフで確認してみます。
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
mu = 0 # 母平均
sigma2 = 4 # 母分散
sigma = np.sqrt(sigma2) # 母標準偏差
n_values = [10, 20, 50, 100, 200] # 標本サイズ
num_simulations = 1000 # シミュレーション回数
# 不偏分散の分散をシミュレーションで計算
simulated_variances = []
theoretical_variances = []
for n in n_values:
sample_variances = []
for _ in range(num_simulations):
sample = np.random.normal(mu, sigma, n)
unbiased_variance = np.var(sample, ddof=1) # 不偏分散
sample_variances.append(unbiased_variance)
# サンプル分散の分散を計算
var_of_sample_variance = np.var(sample_variances)
simulated_variances.append(var_of_sample_variance)
# 理論値を計算
theoretical_variance = 2 * sigma2**2 / (n - 1)
theoretical_variances.append(theoretical_variance)
# グラフの作成
plt.figure(figsize=(10, 6))
plt.plot(n_values, simulated_variances, marker='o', linestyle='-', color='blue', label="シミュレーション値")
plt.plot(n_values, theoretical_variances, marker='o', linestyle='--', color='orange', label="理論値")
# グラフの装飾
plt.title("不偏分散の分散の収束 (シミュレーション vs 理論)")
plt.xlabel("標本サイズ n")
plt.ylabel("分散 (Var[$S^2$])")
plt.grid()
plt.legend()
plt.tight_layout()
plt.show()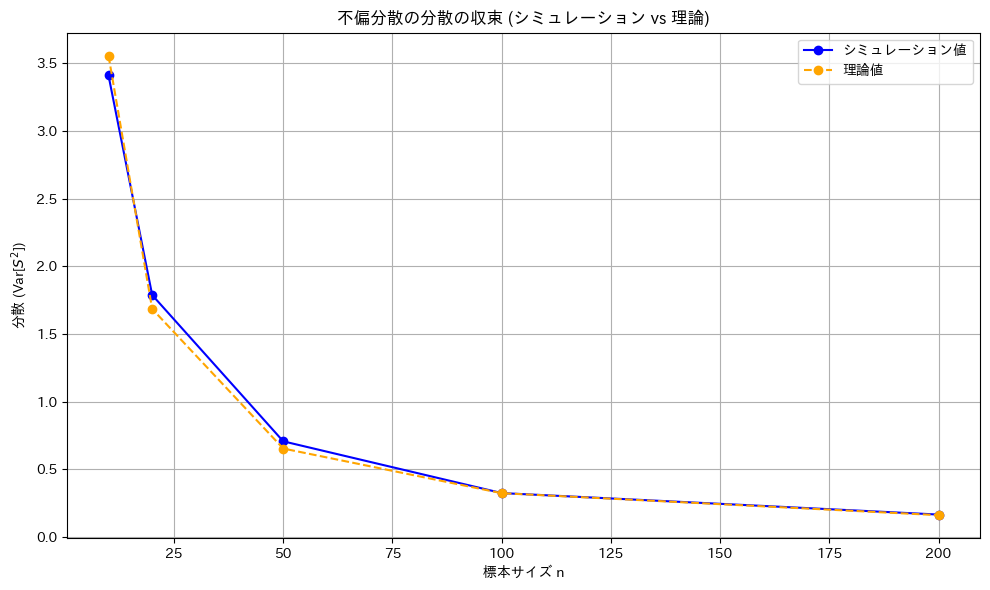
のシミュレーション結果は、理論値とよく一致しました。また、nが増加すると分散が0に近づき、がの一致推定量であることが確認できました。
2015 Q1(3)
平均周りの標本平均のk次モーメントを求めました。
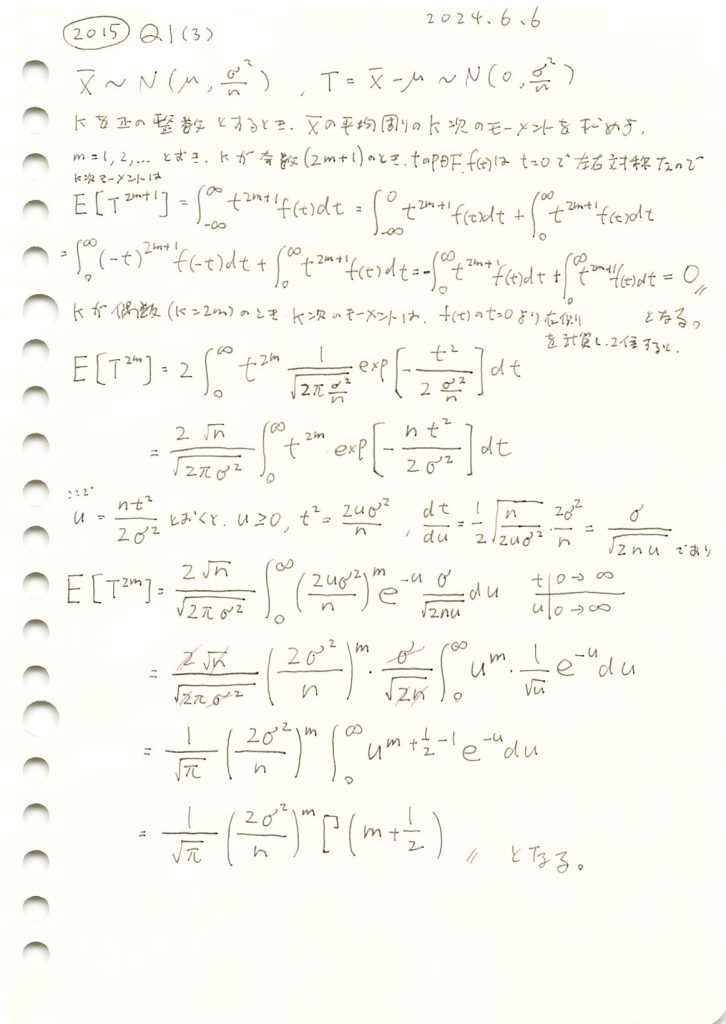
コード
 の平均周りのk次モーメント
の平均周りのk次モーメント を、kとnを変化させてグラフの形状を確認します。
を、kとnを変化させてグラフの形状を確認します。
# 2015 Q1(3) 2024.12.4
import numpy as np
import matplotlib.pyplot as plt
from scipy.special import gamma
# パラメータ設定
sigma2 = 4 # 母分散(固定)
k_values = [2, 4, 6, 8] # 偶数次モーメント
n_values = [12, 14, 16, 18, 20] # 標本サイズ
# 理論式計算の関数
def theoretical_moment_m(m, sigma2, n):
return (gamma(m + 0.5) / np.sqrt(np.pi)) * (2 * sigma2 / n) ** m
# グラフの準備
plt.figure(figsize=(10, 6))
# 各 n に対するモーメント値を計算してプロット
for n in n_values:
moment_values = [theoretical_moment_m(k // 2, sigma2, n) for k in k_values]
plt.plot(k_values, moment_values, marker='o', linestyle='-', label=f"n={n}")
# グラフ
#plt.title(r"モーメント $\frac{\Gamma(m + 1/2)}{\sqrt{\pi}} \left(\frac{2\sigma^2}{n}\right)^m$ の形状")
plt.title(r"$\overline{X}$ の平均周りの $k$ 次モーメントの形状")
plt.xlabel(r"$k$ (偶数次モーメントの次数)")
plt.ylabel("モーメント値")
plt.xticks(k_values)
plt.grid()
plt.legend()
plt.tight_layout()
plt.show()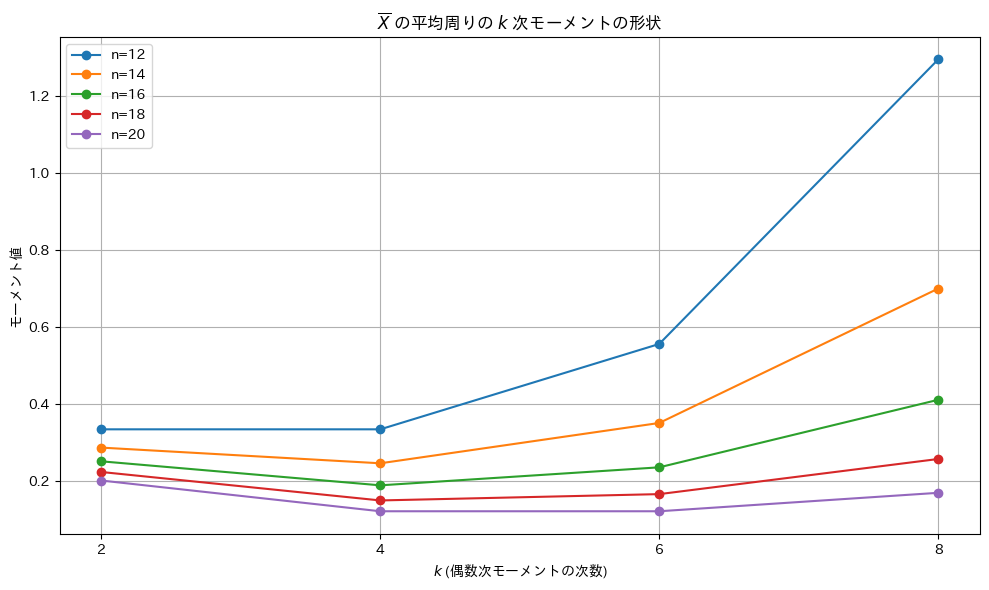
グラフの形状は谷型になっていることが確認され、特定の範囲でモーメント値が最小値を取ることがわかりました。
次に、シミュレーションを行います。標本サイズn=10の場合について実行し、理論値とシミュレーション結果が一致するかを確認します。
# 2015 Q1(3) 2024.12.4
import numpy as np
import matplotlib.pyplot as plt
from scipy.special import gamma
# パラメータ設定
mu = 0 # 母平均
sigma2 = 4 # 母分散
sigma = np.sqrt(sigma2) # 母標準偏差
n = 10 # 標本サイズ
k_values = [2, 4, 6, 8] # 偶数次モーメントを検証
num_simulations = 10000 # シミュレーション回数
# 理論値計算の関数
def theoretical_moment(k, sigma2, n):
m = k // 2
return (gamma(m + 0.5) / np.sqrt(np.pi)) * (2 * sigma2 / n) ** m
# シミュレーション値と理論値を計算
sim_results = []
theory_results = []
for k in k_values:
# シミュレーションで k 次モーメントを計算
sample_means = [np.mean(np.random.normal(mu, sigma, n)) for _ in range(num_simulations)]
k_moment_sim = np.mean([(x - mu) ** k for x in sample_means])
# 理論値を計算
k_moment_theory = theoretical_moment(k, sigma2, n)
# 保存
sim_results.append(k_moment_sim)
theory_results.append(k_moment_theory)
# 棒グラフを作成
x = np.arange(len(k_values))
width = 0.4
plt.figure(figsize=(10, 6))
# プロット
plt.bar(x - width / 2, sim_results, width, label="シミュレーション値", color='blue', alpha=0.7)
plt.bar(x + width / 2, theory_results, width, label="理論値", color='orange', alpha=0.7)
# 軸とラベル
plt.xticks(x, [f"k={k}" for k in k_values])
plt.title(f"標本サイズ n={n} におけるモーメント比較")
plt.xlabel("k 次モーメント")
plt.ylabel("モーメント値")
plt.legend()
plt.grid(axis='y')
# 表示
plt.tight_layout()
plt.show()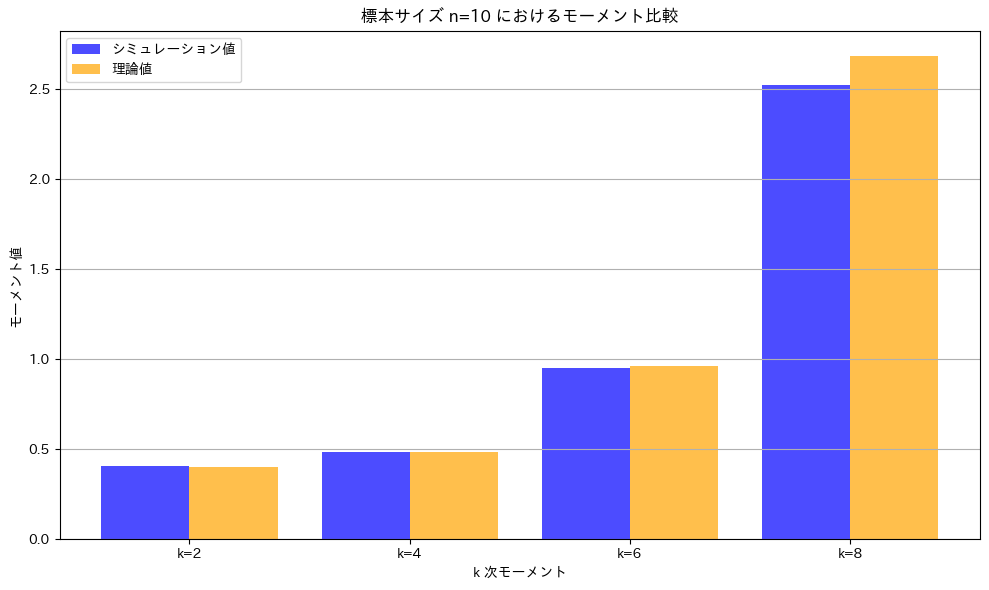
理論値とシミュレーションによる値はよく一致しています。
n=20でもう一度実行します。
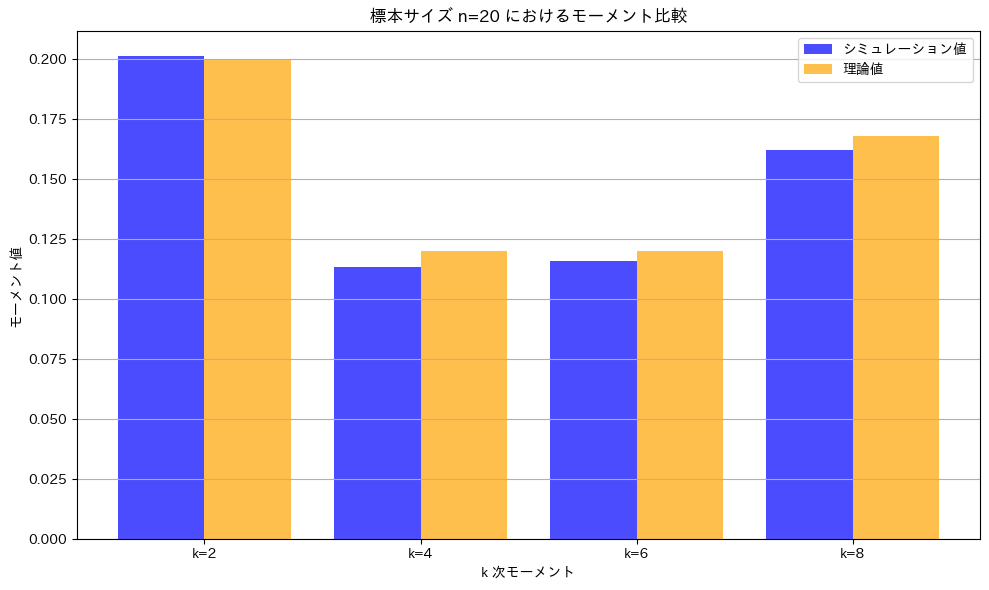
こちらもよく一致しています。グラフの形状が谷型になっていることも確認できました。
2015 Q1(2)
不偏分散が母分散の不偏推定量である事を示しました。
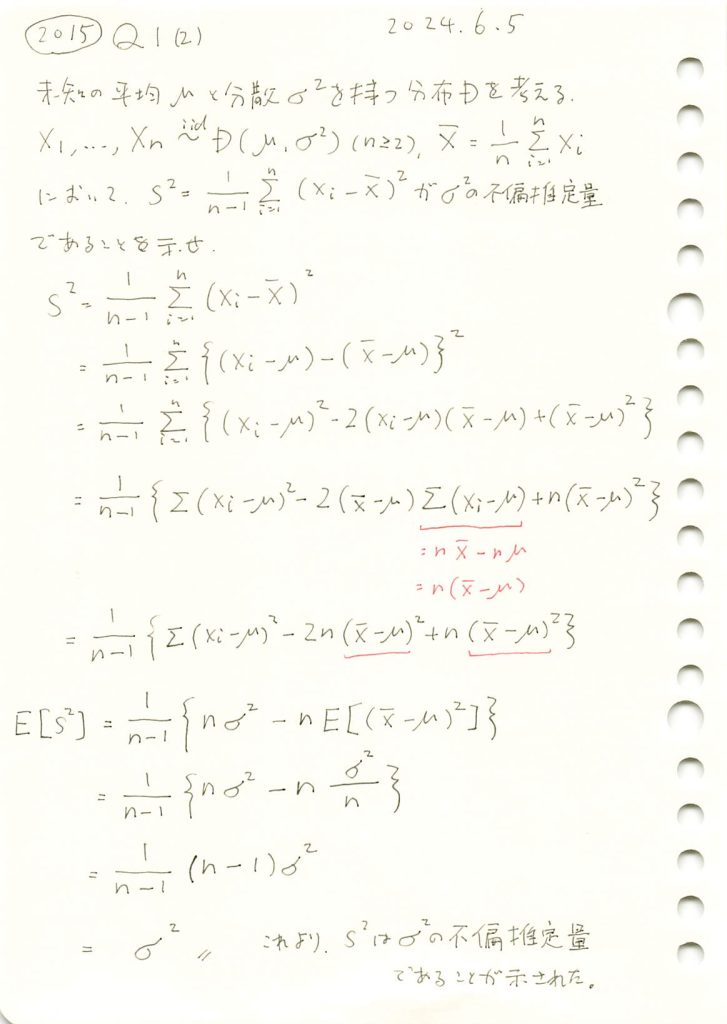
コード
※2018 Q1(1)から引用https://statistics.blue/2018-q11/
nを2~100に変化させて、不偏分散と標本分散を比較してみます。
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
mu = 0 # 母集団平均
sigma = 2 # 母集団標準偏差
sigma_squared = sigma ** 2 # 真の母分散
n_values = range(2, 101, 2) # サンプルサイズ n を2から100まで2ステップで変化させる
num_trials = 3000 # 各 n に対して100回の試行を行う
# 不偏分散 (1/(n-1)) と 標本分散 (1/n) を計算するためのリスト
unbiased_variances = []
biased_variances = []
# 各サンプルサイズ n で分散を計算
for n in n_values:
unbiased_variance_sum = 0
biased_variance_sum = 0
# 各サンプルサイズ n に対して複数回試行して平均を計算
for _ in range(num_trials):
# 正規分布に従うサンプルを生成
sample = np.random.normal(mu, sigma, n)
# 標本平均
sample_mean = np.mean(sample)
# 不偏分散 (1/(n-1))
unbiased_variance = np.sum((sample - sample_mean) ** 2) / (n - 1)
unbiased_variance_sum += unbiased_variance
# 標本分散 (1/n)
biased_variance = np.sum((sample - sample_mean) ** 2) / n
biased_variance_sum += biased_variance
# 各 n に対する平均分散をリストに追加
unbiased_variances.append(unbiased_variance_sum / num_trials)
biased_variances.append(biased_variance_sum / num_trials)
# グラフを描画
plt.plot(n_values, unbiased_variances, label="不偏分散 (1/(n-1))", color='blue', marker='o')
plt.plot(n_values, biased_variances, label="標本分散 (1/n)", color='red', linestyle='--', marker='x')
# 真の分散を水平線で描画
plt.axhline(y=sigma_squared, color='green', linestyle='-', label=f'真の分散 = {sigma_squared}')
# グラフの設定
plt.title('サンプルサイズに対する標本分散と不偏分散の比較')
plt.xlabel('サンプルサイズ n')
plt.ylabel('分散')
plt.legend()
plt.grid(True)
plt.show()
標本分散には不偏性はなく、不偏分散には不偏性があることが確認できました。
次に、![E[(X - \overline{X})^2]](https://statistics.blue/wp-content/ql-cache/quicklatex.com-a70e8dfdd00843d3ea3b68039ff842a7_l3.png "Rendered by QuickLaTeX.com") と
と![E[(X - \mu)^2]](https://statistics.blue/wp-content/ql-cache/quicklatex.com-4e448b67ed48f975378054c14509f99f_l3.png "Rendered by QuickLaTeX.com") を棒グラフで比較してみます。
を棒グラフで比較してみます。
# 2015 Q1(2) 2024.12.3
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
mu = 0 # 母平均
sigma = 2 # 母標準偏差
n = 10 # 標本サイズ
num_simulations = 30 # シミュレーション回数
# 共通のシミュレーションサンプルを生成
samples = [np.random.normal(mu, sigma, n) for _ in range(num_simulations)]
# 各シミュレーションで E[(X - X̄)^2] と E[(X - μ)^2] を計算
var_sample_mean = [np.mean((sample - np.mean(sample))**2) for sample in samples] # E[(X - X̄)^2]
var_population_mean = [np.mean((sample - mu)**2) for sample in samples] # E[(X - μ)^2]
# 棒グラフの準備
x = np.arange(1, num_simulations + 1) # シミュレーション番号
plt.figure(figsize=(12, 6))
# 棒グラフをプロット
plt.bar(x - 0.2, var_sample_mean, width=0.4, label=r"$E[(X - \overline{X})^2]$", color='blue', alpha=0.7)
plt.bar(x + 0.2, var_population_mean, width=0.4, label=r"$E[(X - \mu)^2]$", color='orange', alpha=0.7)
# グラフ
plt.title(r"$E[(X - \overline{X})^2]$ と $E[(X - \mu)^2]$ の比較")
plt.xlabel("シミュレーション番号")
plt.ylabel("値")
plt.xticks(x) # シミュレーション番号をx軸に設定
plt.legend()
plt.grid(axis='y')
# 表示
plt.tight_layout()
plt.show()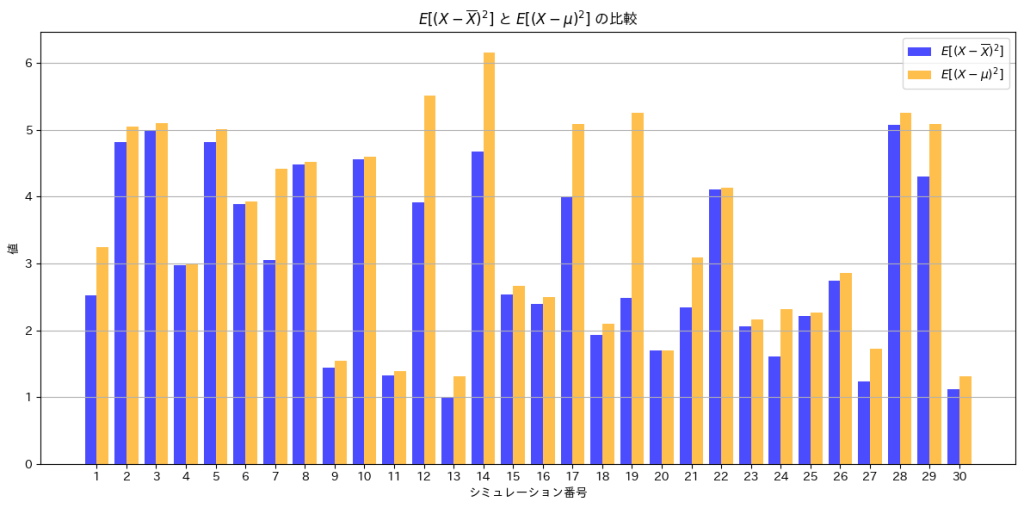
は、よりも小さくなっていることが分かります。不偏分散 は、nでなくn-1で割ることで、母分散の推定値として偏りを修正しています。
は、nでなくn-1で割ることで、母分散の推定値として偏りを修正しています。
2015 Q1(1)
任意の分布に従う確率変数の平均の二乗の期待値を求めました。
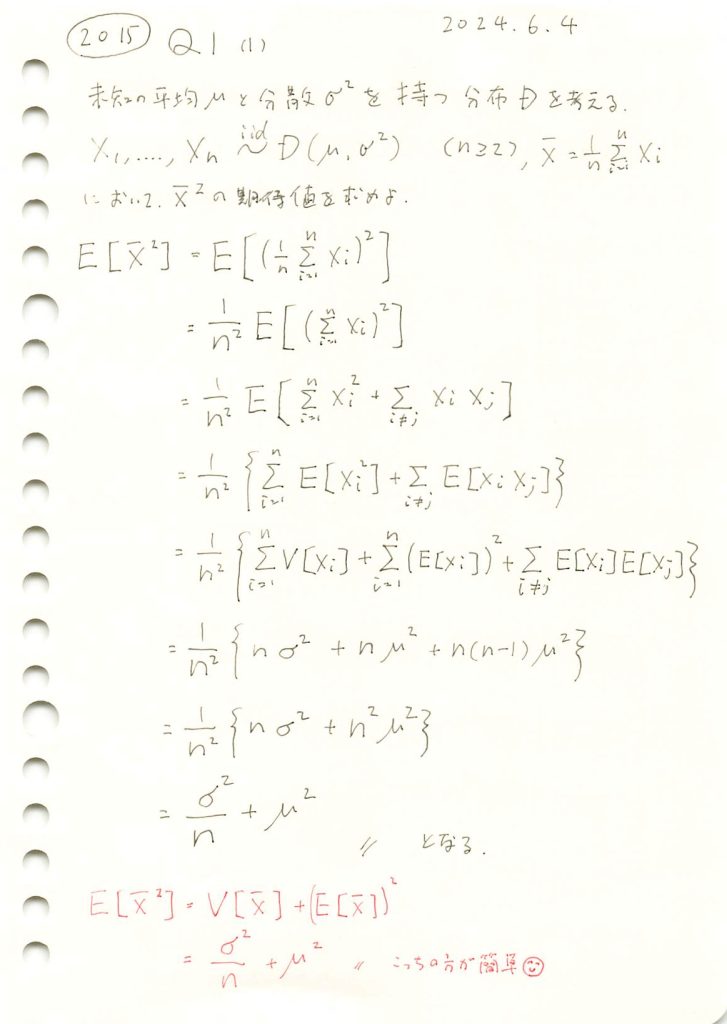
コード
![E[\overline{X}^2] = \frac{\sigma^2}{n} + \mu^2](https://statistics.blue/wp-content/ql-cache/quicklatex.com-00b4325e23c7fb182686e80abc003c74_l3.png "Rendered by QuickLaTeX.com") を確かめるためにシミュレーションを行います。nを変化させながら乱数を発生させ、計算した
を確かめるためにシミュレーションを行います。nを変化させながら乱数を発生させ、計算した を理論値(非心カイ二乗分布)と比較し、プロットしてみます。
を理論値(非心カイ二乗分布)と比較し、プロットしてみます。
#2015 Q1(1) 2024.12.2
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import ncx2
# パラメータ設定(nを複数用意)
n_values = [5, 10, 20, 50] # 標本サイズのリスト
mu = 4 # 母平均
sigma2 = 5 # 母分散
sigma = np.sqrt(sigma2) # 母標準偏差
num_simulations = 10000 # シミュレーション回数
# 暖色系カラーパレットの設定
colors = plt.cm.autumn(np.linspace(0, 1, len(n_values)))
# 描画の準備
plt.figure(figsize=(10, 8))
# 結果格納用
results = []
# nごとに分布をシミュレーションし、プロット
for i, n in enumerate(n_values):
# シミュレーションによる標本平均の二乗 (X̄^2) の生成
sample_means_squared = np.array([
np.mean(np.random.normal(mu, sigma, n))**2 for _ in range(num_simulations)
])
# シミュレーションによる期待値 E[X̄^2] の計算
simulated_mean = np.mean(sample_means_squared)
# 理論値の計算
theoretical_mean = sigma2 / n + mu**2
# 結果を記録
results.append((n, theoretical_mean, simulated_mean))
# ヒストグラムをプロット
plt.hist(
sample_means_squared, bins=30, density=True, alpha=0.5,
label=f"n={n}, 理論値: {theoretical_mean:.3f}, シミュレーション値: {simulated_mean:.3f}",
color=colors[i]
)
# 非心カイ二乗分布のPDFをプロット
x_values = np.linspace(0, np.max(sample_means_squared), 1000)
df = 1 # 自由度は標本平均の二乗の場合、1となる
nc = (n * mu**2) / sigma2 # 非心度 λ
theoretical_pdf = ncx2.pdf(x_values, df, nc, scale=sigma2 / n)
plt.plot(
x_values, theoretical_pdf, linewidth=2, label=f"n={n} の非心カイ二乗分布", color=colors[i]
)
# グラフ
plt.title("標本平均の二乗 ($\\overline{X}^2$) の分布と非心カイ二乗分布")
plt.xlabel("$\\overline{X}^2$")
plt.ylabel("密度")
plt.legend()
plt.grid()
plt.show()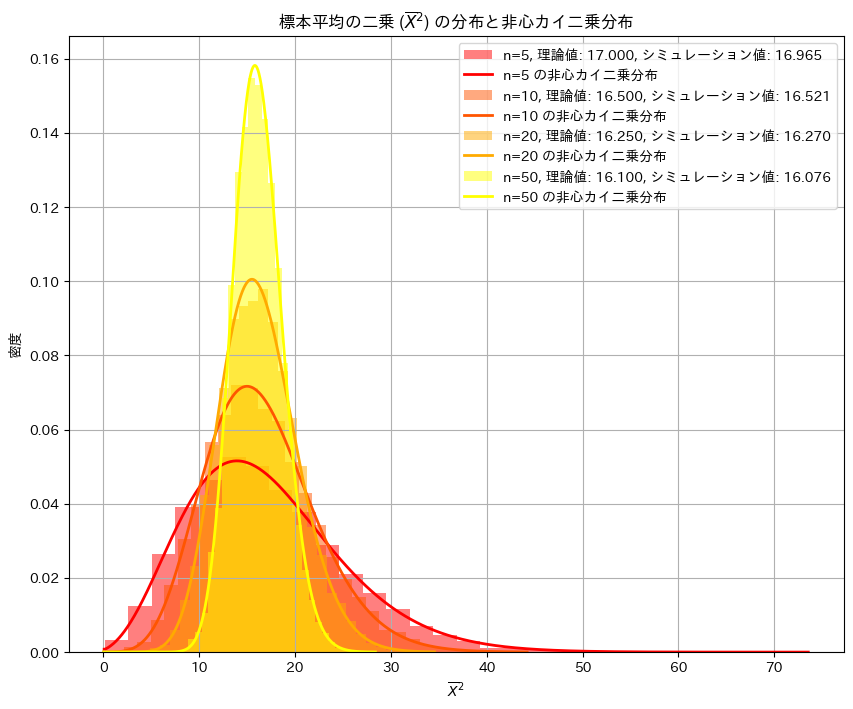
シミュレーションの結果、![E[\overline{X}^2]](https://statistics.blue/wp-content/ql-cache/quicklatex.com-d7337d40d5f8d132b9055c52cd973889_l3.png "Rendered by QuickLaTeX.com") と
と は概ね一致しました。またの分布は理論値(非心カイ二乗分布)の形状とよく重なっていることが確認できました。
は概ね一致しました。またの分布は理論値(非心カイ二乗分布)の形状とよく重なっていることが確認できました。
2016 Q5(4)(5)
欠測のメカニズムがMCARであるか検定する手法の有効性について学びました。

コード
MCARと非MCARの場合の の分布を、棄却域とともに描画をしてみます。
の分布を、棄却域とともに描画をしてみます。
# 2016 Q5(4) 2024.11.30
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import f
# シミュレーションパラメータ
n = 100 # 全サンプル数
m = 60 # 観測可能なデータ数
repeats = 1000 # シミュレーション回数
alpha = 0.05 # 有意水準
# F分布の上位5%点を計算
df1 = 1 # F分布の分子自由度
df2 = n - 2 # F分布の分母自由度
F_critical = f.ppf(1 - alpha, dfn=df1, dfd=df2)
# d^2 の上位5%点を計算
d2_critical = (n - 1) * F_critical / (n - 2 + F_critical)
# MCARデータの生成
def generate_mcar_data(n, m):
X = np.random.normal(0, 1, n)
Y = np.random.normal(0, 1, n)
observed_indices = np.random.choice(n, m, replace=False) # ランダムにm個観測
X_obs, Y_obs = X[observed_indices], Y[observed_indices]
X_miss = np.delete(X, observed_indices) # 欠測部分
return X_obs, X_miss
# MCARではないデータの生成 (欠測がXに依存)
def generate_non_mcar_data(n, m):
X = np.random.normal(0, 1, n)
Y = np.random.normal(0, 1, n)
# ロジスティック関数を使用して、全実数を0~1の確率に変換
prob = 1 / (1 + np.exp(-X)) # Xに依存した欠測確率
observed_indices = np.random.choice(n, m, replace=False, p=prob / prob.sum())
X_obs, Y_obs = X[observed_indices], Y[observed_indices]
X_miss = np.delete(X, observed_indices) # 欠測部分
return X_obs, X_miss
# d^2 の計算
def calculate_d2(X_obs, X_miss):
n = len(X_obs) + len(X_miss)
m = len(X_obs)
X_bar = np.mean(np.concatenate([X_obs, X_miss]))
X_obs_bar = np.mean(X_obs)
X_miss_bar = np.mean(X_miss)
S2 = np.var(np.concatenate([X_obs, X_miss]), ddof=1)
d2 = (1 / S2) * (m * (X_obs_bar - X_bar)**2 + (n - m) * (X_miss_bar - X_bar)**2)
return d2
# MCARデータと非MCARデータで帰無仮説を棄却した割合を計算
results_mcar = [calculate_d2(*generate_mcar_data(n, m)) > d2_critical for _ in range(repeats)]
results_non_mcar = [calculate_d2(*generate_non_mcar_data(n, m)) > d2_critical for _ in range(repeats)]
# 結果を出力
mcar_rejection_rate = np.mean(results_mcar) * 100 # 棄却率 (%)
non_mcar_rejection_rate = np.mean(results_non_mcar) * 100 # 棄却率 (%)
print(f"MCARデータで帰無仮説を棄却した割合: {mcar_rejection_rate:.2f}%")
print(f"非MCARデータで帰無仮説を棄却した割合: {non_mcar_rejection_rate:.2f}%")
# MCARデータと非MCARデータのd^2値を収集
d2_values_mcar = [calculate_d2(*generate_mcar_data(n, m)) for _ in range(repeats)]
d2_values_non_mcar = [calculate_d2(*generate_non_mcar_data(n, m)) for _ in range(repeats)]
# 理論的なd^2の曲線を計算するためのx軸範囲を設定
x_theoretical = np.linspace(0, max(max(d2_values_mcar), max(d2_values_non_mcar)), 500)
# d^2の理論的な確率密度関数を計算
d2_pdf_theoretical = f.pdf(x_theoretical * (n - 2) / (n - 1 - x_theoretical), dfn=df1, dfd=df2)
scaling_factor = (n - 2) / (n - 1)
d2_pdf_theoretical *= scaling_factor
# ヒストグラムの可視化
plt.figure(figsize=(12, 6))
# MCARデータのヒストグラム
plt.hist(d2_values_mcar, bins=30, alpha=0.7, label="MCARデータ", color="blue", density=True)
# 非MCARデータのヒストグラム
plt.hist(d2_values_non_mcar, bins=30, alpha=0.7, label="非MCARデータ", color="orange", density=True)
# 理論的な曲線をプロット
plt.plot(x_theoretical, d2_pdf_theoretical, label="理論的な $d^2$ 分布", color="green", linewidth=2)
# 臨界値をラインで表示
plt.axvline(d2_critical, color="red", linestyle="--", label=r"$d^2$ の臨界値", linewidth=2)
# グラフの装飾
plt.title(r"$d^2$ の分布と理論曲線: MCAR vs 非MCAR", fontsize=14)
plt.xlabel(r"$d^2$ の値", fontsize=12)
plt.ylabel("密度", fontsize=12)
plt.legend(fontsize=12)
plt.grid(alpha=0.3)
# x軸の範囲を制限
plt.xlim(0, 20)
plt.tight_layout()
plt.show()MCARデータで帰無仮説を棄却した割合: 4.10%
非MCARデータで帰無仮説を棄却した割合: 91.70%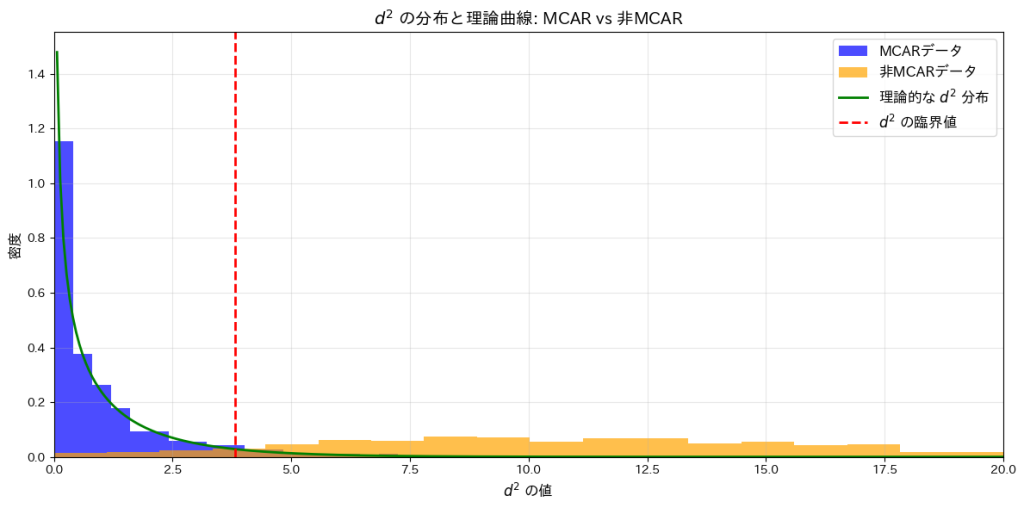
これらの結果から、有意水準を基準にした検定がMCARと非MCARの違いを正確に識別できることが確認されました。
次に、分散の違いを検出するため、非MCARの観測データと欠測データについてF検定を実施します。分布を可視化するとともに、F値とp値を計算して結果を確認します。
# 2016 Q5(5) 2024.12.1
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import f
# データ生成関数
def generate_non_mcar_data(n, m):
"""非MCARデータ生成: Xに依存して欠測"""
X = np.random.normal(0, 1, n) # 母集団は正規分布
Y = np.random.normal(0, 1, n) # ただし今回は使用しない
prob = 1 / (1 + np.exp(-5 * X)) # 欠測確率 (Xに依存)
observed_indices = np.random.choice(n, m, replace=False, p=prob / prob.sum())
X_obs = X[observed_indices]
X_miss = np.delete(X, observed_indices)
return X_obs, X_miss
# パラメータ設定
n = 100 # 全体のサンプル数
m = 60 # 観測されるサンプル数
# 非MCARデータ生成
X_obs, X_miss = generate_non_mcar_data(n, m)
# 平均と分散の計算
mean_obs = np.mean(X_obs)
var_obs = np.var(X_obs, ddof=1)
mean_miss = np.mean(X_miss)
var_miss = np.var(X_miss, ddof=1)
# F検定
F_statistic = var_obs / var_miss # F値
df1 = m - 1 # 観測データの自由度
df2 = n - m - 1 # 欠測データの自由度
p_value = 2 * min(f.cdf(F_statistic, df1, df2), 1 - f.cdf(F_statistic, df1, df2))
# 結果の表示
print(f"観測データの平均: {mean_obs:.5f}, 分散: {var_obs:.5f}")
print(f"欠測データの平均: {mean_miss:.5f}, 分散: {var_miss:.5f}")
print(f"F値: {F_statistic:.5f}")
print(f"p値: {p_value:.5f}")
# 可視化
plt.figure(figsize=(12, 6))
# ヒストグラムをプロット
plt.hist(X_obs, bins=15, alpha=0.7, label=f"観測データ (平均: {mean_obs:.2f}, 分散: {var_obs:.2f})", color="blue", density=True)
plt.hist(X_miss, bins=15, alpha=0.7, label=f"欠測データ (平均: {mean_miss:.2f}, 分散: {var_miss:.2f})", color="orange", density=True)
# グラフ設定
plt.title("非MCARの観測データと欠測データの分布", fontsize=14)
plt.xlabel("値", fontsize=12)
plt.ylabel("密度", fontsize=12)
plt.legend(fontsize=10)
plt.grid(alpha=0.3)
plt.show()観測データの平均: 0.67735, 分散: 0.55682
欠測データの平均: -0.88573, 分散: 0.46808
F値: 1.18958
p値: 0.57003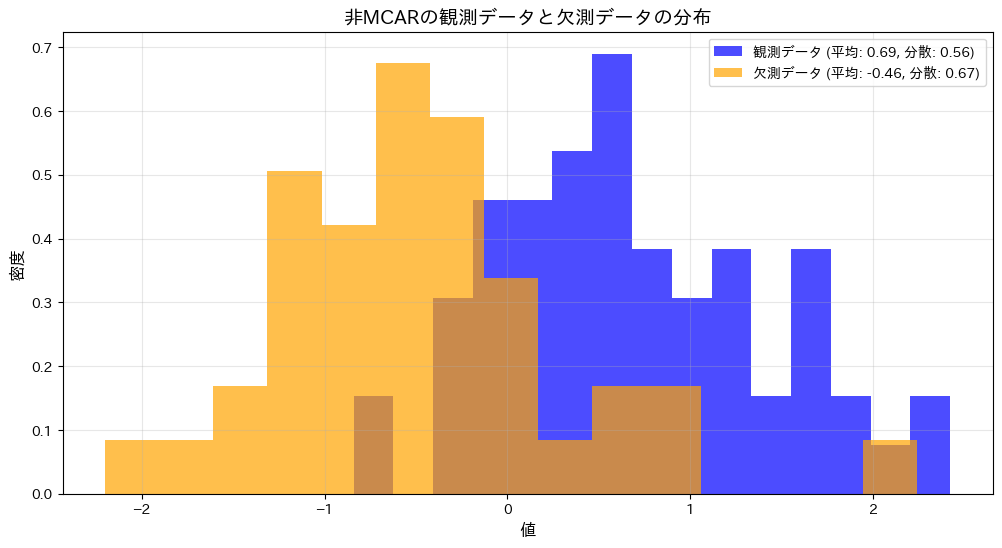
p値0.57003は有意水準を大きく上回り、非MCARの観測データと欠測データの分散に統計的な差があるとは言えません。また、グラフからも両者のばらつきに大きな違いがないことが視覚的に確認されました。
2016 Q5(3)
2群の一元配置分散分析のF検定が、2群の差の両側T検定と、本質的に同等であることを示しました。
コード
t検定(自由度n-2)と F 検定(自由度1,n-2)の p 値が等しいかシミュレーションによって検証してみます。
# 2016 Q5(3) 2024.11.29
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import t, f
# シミュレーションパラメータ
n = 100 # サンプルサイズ
repeats = 10000 # シミュレーションの繰り返し回数
alpha = 0.05 # 有意水準
# 自由度
df1 = 1 # F検定の分子自由度
df2 = n - 2 # F検定の分母自由度(t分布の自由度と一致)
# 検定結果の一致数を記録
agreement_count = 0
# p値を格納するリスト
p_values_t = []
p_values_f = []
# シミュレーションを実行
for _ in range(repeats):
# 2群のデータを生成
group1 = np.random.normal(loc=0, scale=1, size=n // 2)
group2 = np.random.normal(loc=0, scale=1, size=n // 2)
# 群間平均差の標準誤差
pooled_var = ((np.var(group1, ddof=1) + np.var(group2, ddof=1)) / 2)
se = np.sqrt(pooled_var * 2 / (n // 2))
# t統計量
t_stat = (np.mean(group1) - np.mean(group2)) / se
t_squared = t_stat**2
# F統計量
f_stat = t_squared # t^2 = F の関係を利用
# 両検定のp値を計算
p_value_t = 2 * (1 - t.cdf(np.abs(t_stat), df=df2)) # 両側検定
p_value_f = 1 - f.cdf(f_stat, dfn=df1, dfd=df2) # F検定の片側p値
# p値を保存
p_values_t.append(p_value_t)
p_values_f.append(p_value_f)
# 両検定が同じ結論を出したか確認
reject_t = p_value_t < alpha # t検定の結果
reject_f = p_value_f < alpha # F検定の結果
if reject_t == reject_f:
agreement_count += 1
# 一致率を計算
agreement_rate = agreement_count / repeats
# 結果を出力
print(f"t^2 検定と F 検定が一致した割合: {agreement_rate:.2%}")
# 散布図を作成
plt.figure(figsize=(8, 6))
plt.scatter(p_values_t, p_values_f, alpha=0.5, s=10, label="p値の散布図")
plt.plot([0, 1], [0, 1], 'r--', label="$y=x$") # y=xの基準線
plt.title(r"t検定(自由度 $n-2$)と F 検定(自由度 1, $n-2$)の p 値の比較", fontsize=14)
plt.xlabel("t検定のp値", fontsize=12)
plt.ylabel("F検定のp値", fontsize=12)
plt.legend(fontsize=12) # 凡例を追加
plt.grid(alpha=0.3) # グリッドを薄く表示
plt.show()t^2 検定と F 検定が一致した割合: 100.00%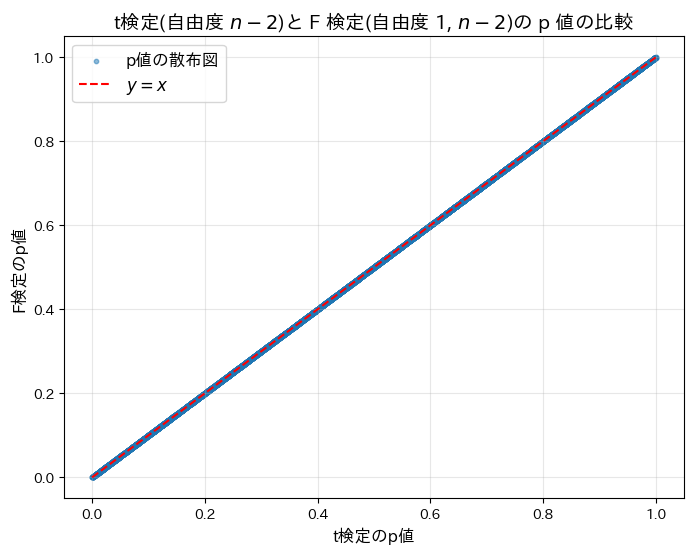
t検定(自由度n-2)と F 検定(自由度1,n-2)の p 値が等しいことがシミュレーションによって確認されました。両検定が同等であることが示されました。
次に、t分布(自由度n-2)と F分布(自由度1,n-2)を描画します。また、t分布の臨界点|t|=1,2と、対応するF分布の臨界点F=1,4( に基づく)を示し、それらで区切られた領域の確率を計算し、それらを視覚的に確認してみます。
に基づく)を示し、それらで区切られた領域の確率を計算し、それらを視覚的に確認してみます。
# 2016 Q5(3) 2024.11.29
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import t, f
# パラメータ設定
n = 12 # サンプルサイズ(自由度は n-2)
df1 = 1 # F分布の分子自由度
df2 = n - 2 # t分布とF分布の分母自由度
x_t = np.linspace(-5, 5, 500) # t分布用のx軸範囲
x_f = np.linspace(0, 25, 500) # F分布用のx軸範囲
# t分布とF分布の確率密度関数を計算
t_pdf = t.pdf(x_t, df=df2) # t分布のPDF
f_pdf = f.pdf(x_f, dfn=df1, dfd=df2) # F分布のPDF
# t分布の新しい臨界点
critical_t_1 = 1 # ±1
critical_t_2 = 2 # ±2
# F分布の新しい臨界点
critical_f_1 = 1 # F=1
critical_f_2 = 4 # F=4
# P値の計算
# t分布のP値
p_t_between = 2 * (t.cdf(critical_t_2, df=df2) - t.cdf(critical_t_1, df=df2)) # 1 <= |t| <= 2
p_t_outside = 2 * (1 - t.cdf(critical_t_2, df=df2)) # |t| > 2
# F分布のP値
p_f_between = f.cdf(critical_f_2, dfn=df1, dfd=df2) - f.cdf(critical_f_1, dfn=df1, dfd=df2) # 1 <= F <= 4
p_f_outside = 1 - f.cdf(critical_f_2, dfn=df1, dfd=df2) # F > 4
# P値の結果を表示
print("t分布のP値:")
print(f" 1 <= |t| <= 2 の P値: {p_t_between:.5f}")
print(f" |t| > 2 の P値: {p_t_outside:.5f}")
print("\nF分布のP値:")
print(f" 1 <= F <= 4 の P値: {p_f_between:.5f}")
print(f" F > 4 の P値: {p_f_outside:.5f}")
# 可視化
plt.figure(figsize=(12, 6))
# t分布のプロット
plt.subplot(1, 2, 1)
plt.plot(x_t, t_pdf, label=r"$t$分布 (自由度 $n-2$)", color="blue")
plt.axvline(-critical_t_1, color="red", linestyle="--", label=r"臨界値 ($|t| = 1$)")
plt.axvline(critical_t_1, color="red", linestyle="--")
plt.axvline(-critical_t_2, color="orange", linestyle="--", label=r"臨界値 ($|t| = 2$)")
plt.axvline(critical_t_2, color="orange", linestyle="--")
plt.fill_between(x_t, t_pdf, where=(np.abs(x_t) <= critical_t_2) & (np.abs(x_t) >= critical_t_1), color="yellow", alpha=0.3, label=r"P値 ($1 \leq |t| \leq 2$)")
plt.fill_between(x_t, t_pdf, where=(np.abs(x_t) >= critical_t_2), color="orange", alpha=0.3, label=r"P値 ($|t| > 2$)")
plt.title("t分布と臨界値", fontsize=14)
plt.xlabel("t値", fontsize=12)
plt.ylabel("確率密度", fontsize=12)
plt.legend(fontsize=10)
plt.grid(alpha=0.3)
plt.xlim(-5, 5)
plt.ylim(0, 0.4)
# F分布のプロット
plt.subplot(1, 2, 2)
plt.plot(x_f, f_pdf, label=r"$F$分布 (自由度 $1, n-2$)", color="green")
plt.axvline(critical_f_1, color="red", linestyle="--", label=r"臨界値 ($F = 1$)")
plt.axvline(critical_f_2, color="orange", linestyle="--", label=r"臨界値 ($F = 4$)")
plt.fill_between(x_f, f_pdf, where=(x_f <= critical_f_2) & (x_f >= critical_f_1), color="yellow", alpha=0.3, label=r"P値 ($1 \leq F \leq 4$)")
plt.fill_between(x_f, f_pdf, where=(x_f >= critical_f_2), color="orange", alpha=0.3, label=r"P値 ($F > 4$)")
plt.title("F分布と臨界値", fontsize=14)
plt.xlabel("F値", fontsize=12)
plt.ylabel("確率密度", fontsize=12)
plt.legend(fontsize=10)
plt.grid(alpha=0.3)
plt.xlim(0, 10)
plt.ylim(0, 0.4)
plt.tight_layout()
plt.show()t分布のP値:
1 <= |t| <= 2 の P値: 0.26751
|t| > 2 の P値: 0.07339
F分布のP値:
1 <= F <= 4 の P値: 0.26751
F > 4 の P値: 0.07339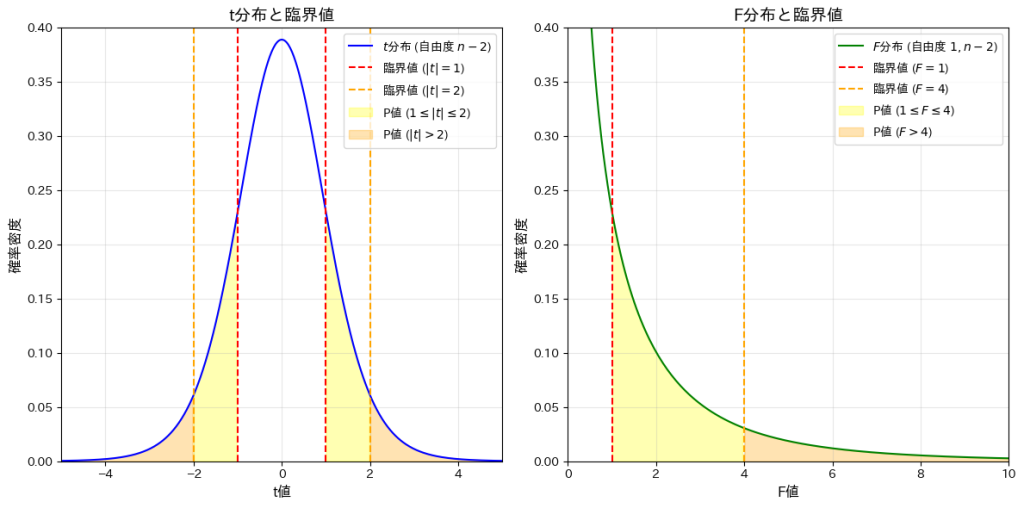
t分布の臨界で区切られた領域の確率と、それに対応するF分布の領域の確率が一致することを確認しました。