ホーム » コードあり (ページ 4)
「コードあり」カテゴリーアーカイブ
2015 Q4(3)
確率の分割表に対称性があるという仮説の下での尤度比検定を行いp値が0.01より小さいか判定しました。

コード
 が成り立つかを確認するために、尤度比検定量
が成り立つかを確認するために、尤度比検定量 を求め、尤度比検定を行います。
を求め、尤度比検定を行います。
# 2015 Q4(3) 2024.12.19
import numpy as np
from scipy.stats import chi2
# 観測度数表
observed_counts = np.array([[1520, 266, 124, 66],
[234, 1512, 432, 78],
[117, 362, 1772, 205],
[36, 82, 179, 492]])
I = observed_counts.shape[0] # 行・列のサイズ
# 尤度比統計量 G^2 の計算 (対角要素を除外)
G2 = 2 * sum(
observed_counts[i, j] * np.log(2 * observed_counts[i, j] / (observed_counts[i, j] + observed_counts[j, i]))
for i in range(I) for j in range(I) if i != j
)
# 自由度の計算 (非対角要素の数: I(I-1)/2)
df = (I * (I - 1)) // 2
# P値の計算
p_value = 1 - chi2.cdf(G2, df)
# 結果の表示
print(f"尤度比統計量 G^2: {G2:.4f}")
print(f"自由度: {df}")
print(f"P値: {p_value:.10f}")
# 帰無仮説の判定
if p_value < 0.01:
print("P値は0.01より小さいため、帰無仮説 H_0 は棄却されます。")
else:
print("P値は0.01以上のため、帰無仮説 H_0 は棄却されません。")
尤度比統計量 G^2: 19.2492
自由度: 6
P値: 0.0037628518
P値は0.01より小さいため、帰無仮説 H_0 は棄却されます。P値は0.01より小さいため、帰無仮説  は棄却されました。
は棄却されました。
2015 Q4(2)
確率の分割表に対称性があるという仮説の下での期待度数の最尤推定を行いました。
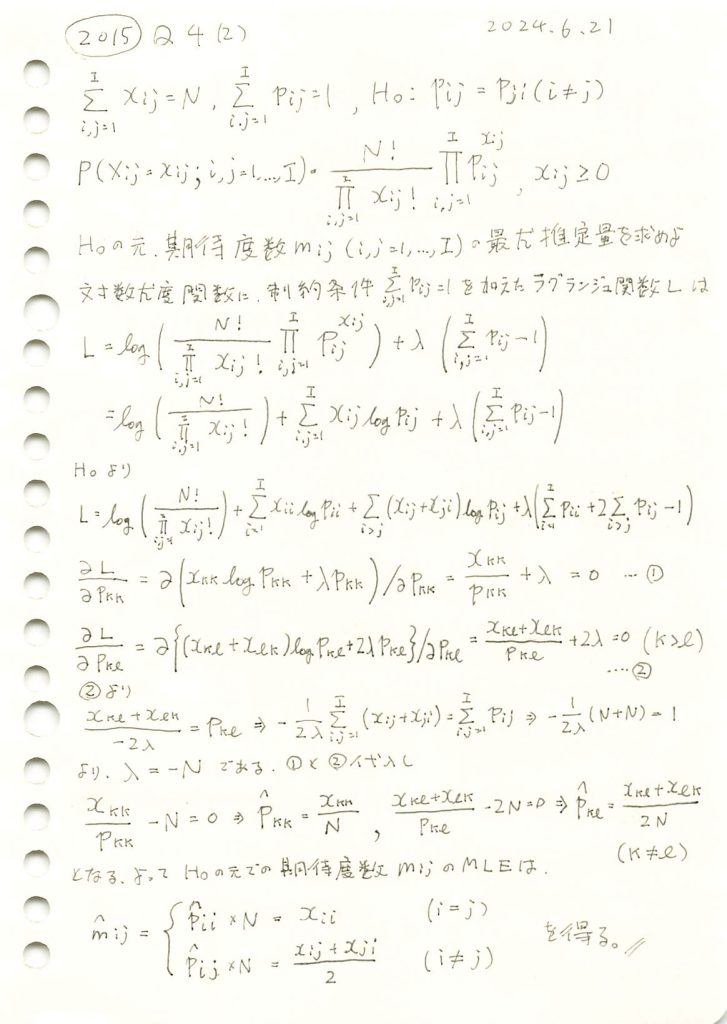
与えられた観測度数表から に基づき期待度数を求めます。
に基づき期待度数を求めます。
# 2015 Q4(2) 2024.12.18
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 1. 観測度数表
observed_counts = np.array([[1520, 266, 124, 66],
[234, 1512, 432, 78],
[117, 362, 1772, 205],
[36, 82, 179, 492]])
# 2. 総サンプルサイズ N
N = observed_counts.sum()
# 3. 期待度数 m_ij の計算 (対称性の仮説)
m_ij = np.zeros_like(observed_counts, dtype=float)
I = observed_counts.shape[0]
for i in range(I):
for j in range(I):
if i == j: # 対角要素
m_ij[i, j] = observed_counts[i, j]
else: # 非対角要素
m_ij[i, j] = (observed_counts[i, j] + observed_counts[j, i]) / 2
# 4. 観測度数と期待度数をDataFrameにまとめる
row_labels = col_labels = ["Highest", "Second", "Third", "Lowest"]
df_observed = pd.DataFrame(observed_counts, index=row_labels, columns=col_labels)
df_expected = pd.DataFrame(np.round(m_ij, 2), index=row_labels, columns=col_labels)
# 5. 観測度数と期待度数のヒートマップを作成
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# 観測度数のヒートマップ
sns.heatmap(df_observed, annot=True, fmt=".0f", cmap="Blues", ax=axes[0])
axes[0].set_title("観測度数表 $x_{ij}$")
# 期待度数のヒートマップ
sns.heatmap(df_expected, annot=True, fmt=".2f", cmap="Greens", ax=axes[1])
axes[1].set_title("期待度数表 $\hat{m}_{ij}$ (対称性の仮説)")
plt.tight_layout()
plt.show()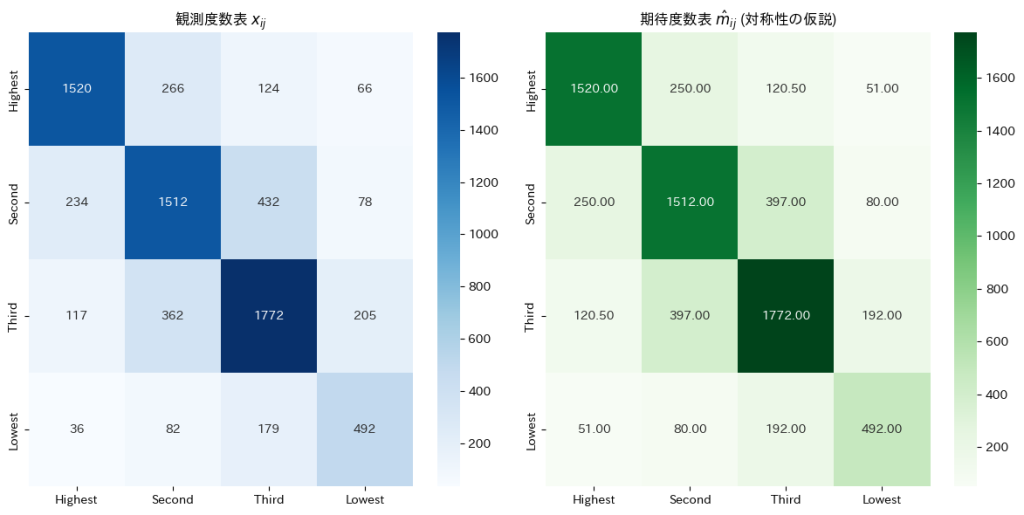
与えられた観測度数表からに基づいて期待度数を求めると、非対角要素は対応する2つの観測度数の平均として表され、対角要素は観測度数そのものが期待度数となりました。
2015 Q4(1)
観測度数と確率の分割表から、そうなり得る確率を求めました。

コード
与えられた観測度数表から仮にセル確率を計算し、その観測度数が多項分布に基づいて得られる確率を計算をします。
# 2015 Q4(1) 2024.12.17
import numpy as np
import pandas as pd
from scipy.stats import multinomial
# 観測度数表 (与えられたデータ)
observed_counts = np.array([[1520, 266, 124, 66],
[234, 1512, 432, 78],
[117, 362, 1772, 205],
[36, 82, 179, 492]])
# 総サンプルサイズ N の計算
N = observed_counts.sum()
# セル確率 pij の計算 (観測度数を総数で割る)
p_ij = observed_counts / N
# 観測度数とセル確率
row_labels = ["Highest", "Second", "Third", "Lowest"]
col_labels = ["Highest", "Second", "Third", "Lowest"]
# 観測度数
df_counts = pd.DataFrame(observed_counts, columns=col_labels, index=row_labels)
# セル確率
df_probs = pd.DataFrame(np.round(p_ij, 6), columns=col_labels, index=row_labels)
print("観測度数表 (x_ij):")
print(df_counts)
print("\nセル確率表 (p_ij):")
print(df_probs)
# 観測度数が得られる確率を計算
x_flat = observed_counts.flatten()
p_flat = p_ij.flatten()
# 多項分布の確率を計算
prob = multinomial.pmf(x_flat, n=N, p=p_flat)
print(f"\nこの観測度数表が得られる確率: {prob:.10e}")観測度数表 (x_ij):
Highest Second Third Lowest
Highest 1520 266 124 66
Second 234 1512 432 78
Third 117 362 1772 205
Lowest 36 82 179 492
セル確率表 (p_ij):
Highest Second Third Lowest
Highest 0.203290 0.035576 0.016584 0.008827
Second 0.031296 0.202220 0.057777 0.010432
Third 0.015648 0.048415 0.236993 0.027417
Lowest 0.004815 0.010967 0.023940 0.065802
この観測度数表が得られる確率: 7.0375704386e-24得られた確率はとても小さな数字になりました。これは、特定の具体的な度数の組み合わせが発生する確率であるため小さくなります。
2015 Q3(4)
重回帰モデルの重みの2種類の推定量のMSEを求め比較しました。

コード
 を
を  と
と  の変化に対してプロットし、その符号の変化を確認します。
の変化に対してプロットし、その符号の変化を確認します。
# 2015 Q3(4) 2024.12.16
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
r12_squared_vals = np.linspace(0, 0.99, 50) # r12^2の値(0から0.99まで)
beta2_squared_vals = np.linspace(0, 1.5, 50) # β2^2の値(0から1.5まで)
sigma2 = 1 # 誤差分散 σ^2
S11 = 10 # S11の仮定値
S12 = 5 # S12の仮定値
S22 = 15 # S22の仮定値
# グリッド生成
R12_squared, Beta2_squared = np.meshgrid(r12_squared_vals, beta2_squared_vals)
# MSEの差の計算
Var_beta2_hat = (sigma2 / S22) * (1 / (1 - R12_squared)) # Var(β2)
MSE_diff = (S12 / S11)**2 * (Var_beta2_hat - Beta2_squared) # MSEの差
# 3Dプロットの描画
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111, projection='3d')
# 3Dサーフェスプロット
surf = ax.plot_surface(R12_squared, Beta2_squared, MSE_diff, cmap='coolwarm', edgecolor='none')
# 軸ラベルとタイトル
ax.set_title(r'3Dプロット: $\mathrm{MSE}(\hat{\beta}_1) - \mathrm{MSE}(\tilde{\beta}_1)$ の符号反転', fontsize=14)
ax.set_xlabel(r'$r_{12}^2$ (相関係数の二乗)', fontsize=12)
ax.set_ylabel(r'$\beta_2^2$ (回帰係数の二乗)', fontsize=12)
ax.set_zlabel(r'$\mathrm{MSE}(\hat{\beta}_1) - \mathrm{MSE}(\tilde{\beta}_1)$', fontsize=12)
# カラーバーの追加
fig.colorbar(surf, ax=ax, shrink=0.5, aspect=10, label='MSEの差')
plt.tight_layout()
plt.show()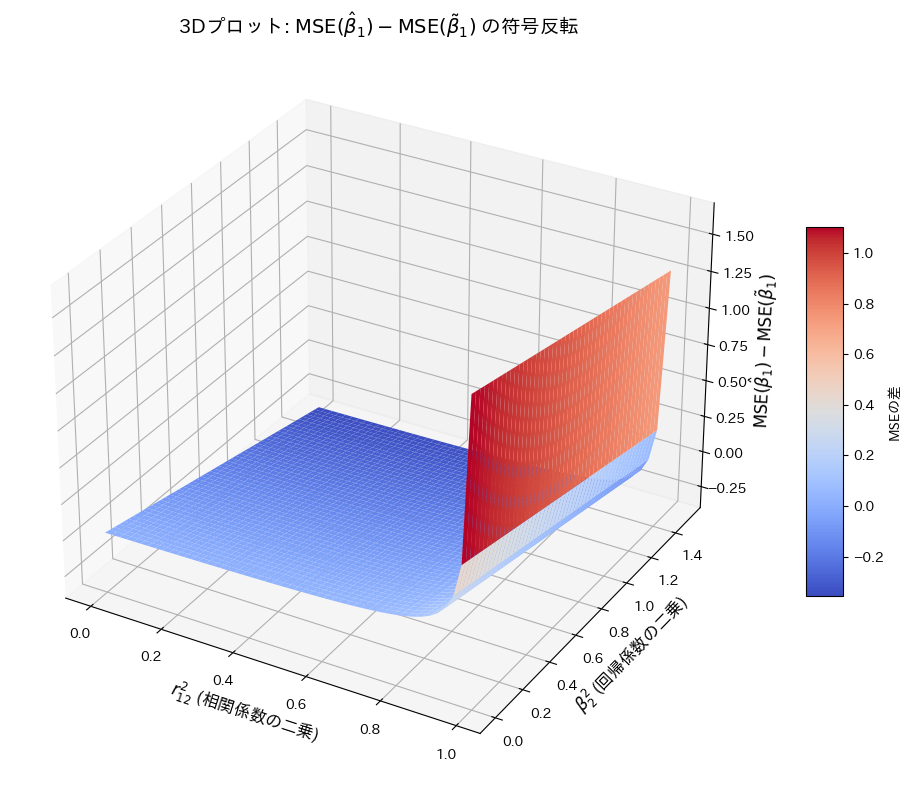
の符号は と の値に依存して変化することが確認できました。
2015 Q3(4)
重回帰モデルの重みの推定量の分散と、説明変数を減らした時のそれとの差を求め、説明変数間の相関係数によるどのような関数になるのか調べました。

コード
 の変化が
の変化が と
と に与える影響を、グラフで描画して確認します。
に与える影響を、グラフで描画して確認します。
# 2015 Q3(4) 2024.12.15
import numpy as np
import matplotlib.pyplot as plt
# 1. パラメータ設定
r12_vals = np.linspace(-0.99, 0.99, 200) # r12の値(-0.99から0.99まで)
sigma2 = 1 # 分散 σ^2
S11 = 10 # S11の仮定値
# 重回帰と単回帰の分散計算
Var_beta1_hat = (sigma2 / S11) * (1 / (1 - r12_vals**2)) # 重回帰(r12に依存)
Var_beta1_tilde = sigma2 / S11 # 単回帰(r12=0の分散)
# 2. グラフのプロット
plt.figure(figsize=(10, 6))
plt.plot(r12_vals, Var_beta1_hat, label=r'$\mathrm{Var}(\hat{\beta}_1)$ (重回帰)', color='blue', linewidth=2)
plt.axhline(y=Var_beta1_tilde, color='orange', linestyle='--', label=r'$\mathrm{Var}(\tilde{\beta}_1)$ (単回帰, $r_{12}=0$)')
# 軸ラベルとタイトル
plt.title(r'$\mathrm{Var}(\tilde{\beta}_1)$ と $\mathrm{Var}(\hat{\beta}_1)$ の比較', fontsize=14, fontweight='bold')
plt.xlabel(r'$r_{12}$($x_1$と$x_2$の相関)', fontsize=12)
plt.ylabel(r'分散', fontsize=12)
# 凡例とグリッド
plt.legend(fontsize=10, loc='upper right')
plt.grid(alpha=0.5)
# グラフ表示
plt.tight_layout()
plt.show()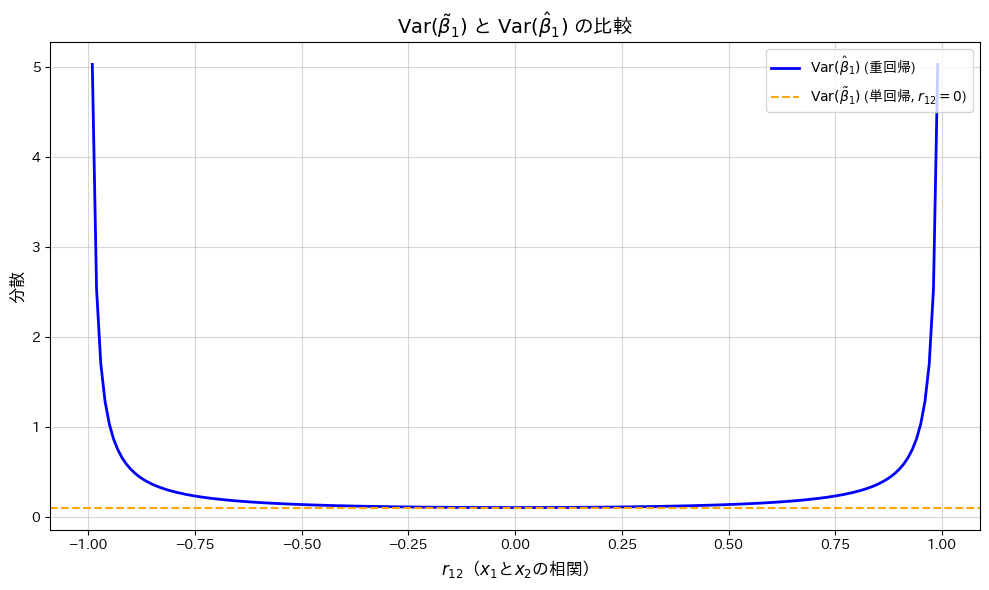
が0に近いほどは最小となり、相関が高まると分散が増加する一方で、は一定であることが確認されました。
次に、横軸をとして、との変化をプロットし、両者の差も併せて確認します。
# 2015 Q3(4) 2024.12.15
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
r12_vals = np.linspace(-0.99, 0.99, 200) # r12の値(-0.99から0.99まで)
sigma2 = 1 # 分散 σ^2
S11 = 10 # S11の仮定値
# r12^2 の計算
r12_squared_vals = r12_vals**2 # r12^2 の値
# 重回帰と単回帰の分散計算
Var_beta1_hat = (sigma2 / S11) * (1 / (1 - r12_squared_vals)) # 重回帰(r12に依存)
Var_beta1_tilde = sigma2 / S11 # 単回帰(r12=0の分散)
# 分散の差の計算
Var_diff = Var_beta1_hat - Var_beta1_tilde # 分散の差
# グラフのプロット
plt.figure(figsize=(10, 6))
# 分散のプロット
plt.plot(r12_squared_vals, Var_beta1_hat, label=r'$\mathrm{Var}(\hat{\beta}_1)$ (重回帰)', color='blue', linewidth=2)
plt.axhline(y=Var_beta1_tilde, color='orange', linestyle='--', label=r'$\mathrm{Var}(\tilde{\beta}_1)$ (単回帰, $r_{12}=0$)')
# 分散の差をプロット
plt.plot(r12_squared_vals, Var_diff, label=r'$\mathrm{Var}(\hat{\beta}_1) - \mathrm{Var}(\tilde{\beta}_1)$', color='green', linewidth=2, linestyle=':')
# 軸ラベルとタイトル
plt.title(r'$\mathrm{Var}(\tilde{\beta}_1)$, $\mathrm{Var}(\hat{\beta}_1)$ とその差の比較 ($r_{12}^2$)', fontsize=14, fontweight='bold')
plt.xlabel(r'$r_{12}^2$(相関係数の二乗)', fontsize=12)
plt.ylabel(r'分散 / 差', fontsize=12)
# 凡例とグリッド
plt.legend(fontsize=10, loc='upper right')
plt.grid(alpha=0.5)
# グラフ表示
plt.tight_layout()
plt.show()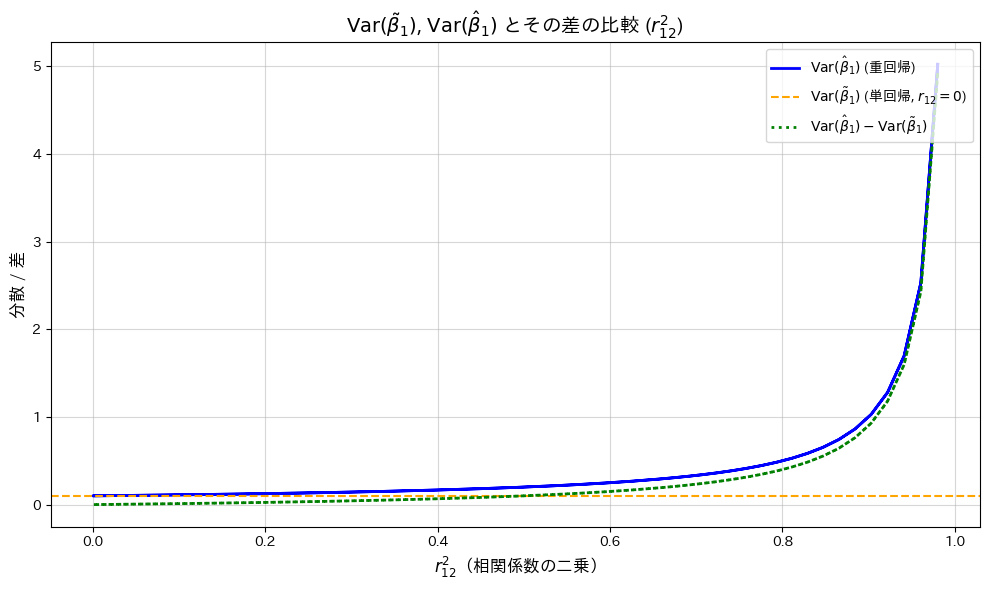
 がの単調増加関数であることが確認されました。
がの単調増加関数であることが確認されました。
2015 Q3(3)
重回帰モデルの重みの推定量の分散を求め、説明変数間の相関がそれにどのように影響するか確認しました。
コード
の変化がと に与える影響を、グラフで描画して確認します。
に与える影響を、グラフで描画して確認します。
# 2015 Q3(3) 2024.12.14
import numpy as np
import matplotlib.pyplot as plt
# 1. パラメータ設定
r12_vals = np.linspace(-0.99, 0.99, 200) # r12の値(-0.99から0.99まで)
sigma2 = 1 # 分散 σ^2
S11 = 10 # S11の仮定値
S22 = 15 # S22の仮定値
# 2. 分散の計算
Var_beta1 = (sigma2 / S11) * (1 / (1 - r12_vals**2)) # Var(β1)
Var_beta2 = (sigma2 / S22) * (1 / (1 - r12_vals**2)) # Var(β2)
# 3. グラフのプロット
plt.figure(figsize=(10, 6))
plt.plot(r12_vals, Var_beta1, label=r'$\mathrm{Var}(\hat{\beta}_1)$', color='blue', linewidth=2)
plt.plot(r12_vals, Var_beta2, label=r'$\mathrm{Var}(\hat{\beta}_2)$', color='orange', linewidth=2)
plt.axhline(y=sigma2 / S11, color='blue', linestyle='--', label=r'$r_{12}=0$ の $\mathrm{Var}(\hat{\beta}_1)$')
plt.axhline(y=sigma2 / S22, color='orange', linestyle='--', label=r'$r_{12}=0$ の $\mathrm{Var}(\hat{\beta}_2)$')
# 軸ラベルとタイトル
plt.title(r'$\mathrm{Var}(\hat{\beta}_1)$ と $\mathrm{Var}(\hat{\beta}_2)$ の $r_{12}$ に対する変化', fontsize=14, fontweight='bold')
plt.xlabel(r'$r_{12}$($x_1$と$x_2$の相関)', fontsize=12)
plt.ylabel(r'分散', fontsize=12)
# 凡例とグリッド
plt.legend(fontsize=10, loc='upper right')
plt.grid(alpha=0.5)
# グラフ表示
plt.tight_layout()
plt.show()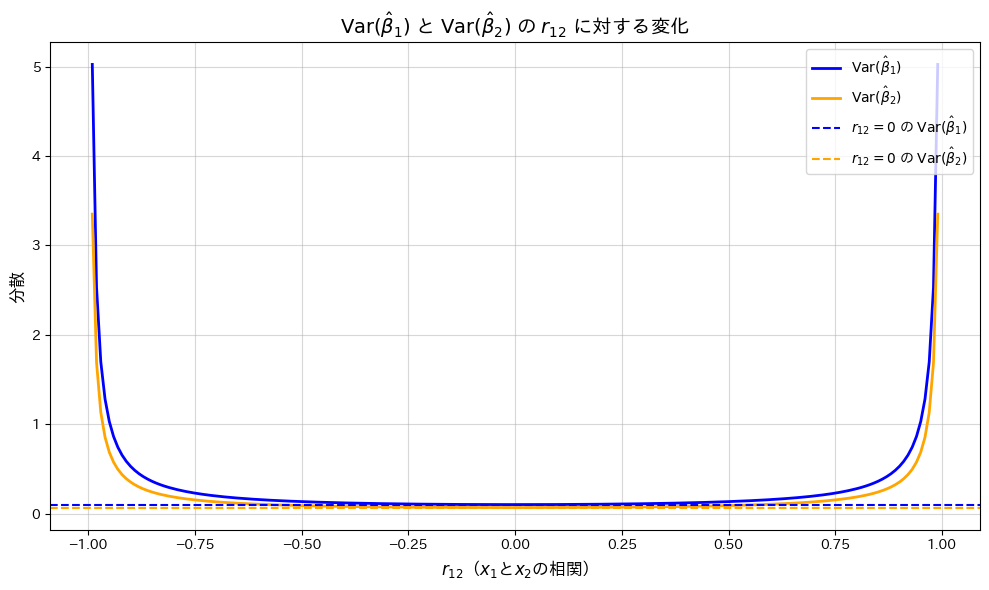
が0に近いほどとは最小となり、相関が高まると分散が増加することが確認されました。
2015 Q3(2)
重回帰モデルの重みβ1を3つの相関係数を使って表し、それが負になる必要十分条件を求めました。
コード
が大きな値をとる場合、 が負の値をとりやすくなることを確認するため、とは、正の数に固定した上で、グラフで可視化します。
が負の値をとりやすくなることを確認するため、とは、正の数に固定した上で、グラフで可視化します。
# 2015 Q3(2) 2024.12.13
import numpy as np
import matplotlib.pyplot as plt
# 1. パラメータの設定
n = 100 # サンプルサイズ
r12_vals = np.linspace(-0.99, 0.99, 100) # r12 を -0.99 から 0.99 まで変化させる
r1y = 0.5 # r1y を固定
r2y = 0.6 # r2y を固定
# 2. Beta1 の計算
beta1_vals = []
for r12 in r12_vals:
if abs(r12) >= 1:
beta1_vals.append(np.nan) # r12 = ±1 の場合は計算不能
continue
beta1 = (r1y - r12 * r2y) / (1 - r12**2) # 簡略化された Beta1 の符号条件
beta1_vals.append(beta1)
# 3. 結果の可視化
plt.figure(figsize=(8, 6))
plt.plot(r12_vals, beta1_vals, label=r'$\hat{\beta}_1$', color='blue')
plt.axhline(0, color='red', linestyle='--', label='ゼロライン (基準)')
plt.title(r'$\hat{\beta}_1$ と $r_{12}$ の関係', fontsize=14, fontweight='bold')
plt.xlabel(r'$r_{12}$($x_1$と$x_2$の相関)', fontsize=12)
plt.ylabel(r'$\hat{\beta}_1$', fontsize=12)
plt.legend(fontsize=10, loc='upper left')
plt.grid(alpha=0.7)
plt.tight_layout()
plt.show()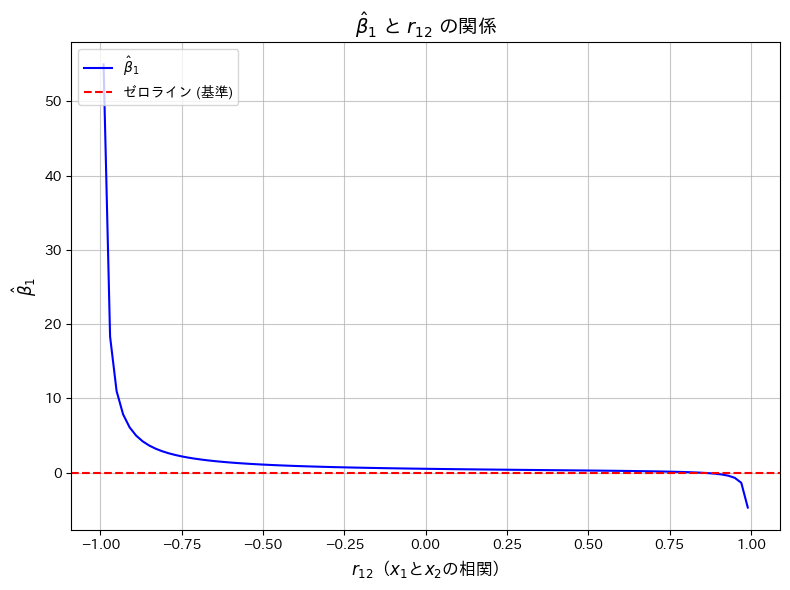
が1に近い値をとると、が負の値をとる傾向があることが確認できました。
2015 Q3(1)
重回帰モデルにおいて正規方程式を用い、各重みの最小二乗推定量を求めました。
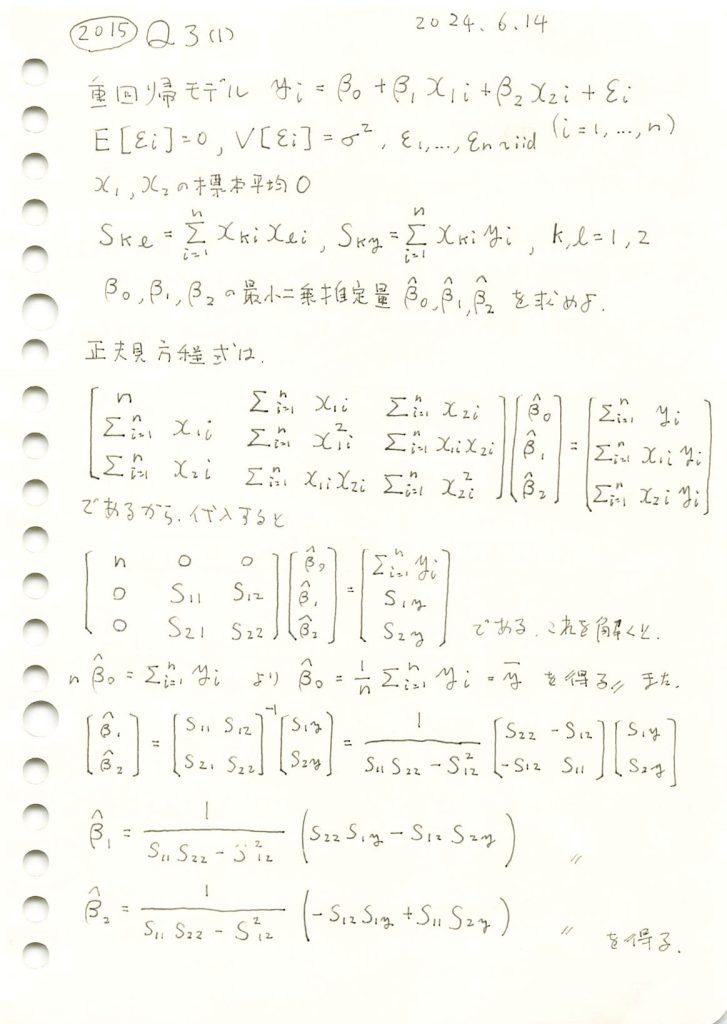
コード
重回帰モデルのシミュレーションを行い、パラメータβ0,β1,β2の推定量を計算し、真の値と比較します。
# 2015 Q3(1) 2024.12.12
import numpy as np
# 1. パラメータの設定 (再現性のため同じ設定を使用)
n = 100
beta_0, beta_1, beta_2 = 2.0, 1.0, -0.5
sigma = 1.0
# 2. 説明変数と誤差の生成
x1 = np.random.randn(n)
x2 = np.random.randn(n)
epsilon = np.random.randn(n) * sigma
# 3. 応答変数の生成
y = beta_0 + beta_1 * x1 + beta_2 * x2 + epsilon
# 4. S11, S22, S12, S1y, S2y を計算
S11 = np.sum(x1**2)
S22 = np.sum(x2**2)
S12 = np.sum(x1 * x2)
S1y = np.sum(x1 * y)
S2y = np.sum(x2 * y)
# 5. 推定値の計算 (導出した式に基づく)
denominator = S11 * S22 - S12**2
beta1_hat = (S22 * S1y - S12 * S2y) / denominator
beta2_hat = (S11 * S2y - S12 * S1y) / denominator
beta0_hat = np.mean(y) - beta1_hat * np.mean(x1) - beta2_hat * np.mean(x2)
# 推定値の表示
print(f"推定値 (導出した式):")
print(f" β0 = {beta0_hat:.3f}")
print(f" β1 = {beta1_hat:.3f}")
print(f" β2 = {beta2_hat:.3f}")
# 真の値と比較
print("\n真の値:")
print(f" β0 = {beta_0:.3f}")
print(f" β1 = {beta_1:.3f}")
print(f" β2 = {beta_2:.3f}")推定値 (導出した式):
β0 = 1.909
β1 = 0.863
β2 = -0.505
真の値:
β0 = 2.000
β1 = 1.000
β2 = -0.500シミュレーションの結果、パラメータβ0,β1,β2の推定量はわずかな誤差はあるものの、真の値に近い値を示しました。
2015 Q2(5)
前問の検定がネイマン-ピアソンの基本定理に基づき一様最強力検定であることを示しました。

コード
有意水準α=0.05のもと、検出力を理論値とシミュレーションで描画し比較します。
# 2015 Q2(5) 2024.12.11
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# シミュレーション設定
alpha = 0.05 # 有意水準
z_alpha = norm.ppf(1 - alpha) # 臨界値 z_alpha
num_simulations = 10000 # シミュレーション回数
n = 10 # 標本サイズ
mu_values = np.linspace(0, 2, 10) # 真の平均 μ の範囲
# 臨界値の計算
critical_value = z_alpha / np.sqrt(n) # 棄却域の閾値
# 検出力を計算する関数
def compute_power_for_mu(mu, n, z_alpha):
return 1 - norm.cdf(z_alpha - mu * np.sqrt(n))
# シミュレーションで検出力を計算
empirical_powers = []
for mu in mu_values:
samples = np.random.normal(mu, 1 / np.sqrt(n), num_simulations) # 標本生成
rejection_rate = np.mean(samples > critical_value) # 棄却割合
empirical_powers.append(rejection_rate)
# 理論的な検出力を計算
theoretical_powers = [compute_power_for_mu(mu, n, z_alpha) for mu in mu_values]
# グラフの描画
plt.figure(figsize=(10, 6))
plt.plot(mu_values, theoretical_powers, label="理論的検出力", linestyle="--", color="blue")
plt.scatter(mu_values, empirical_powers, label="シミュレーションによる検出力", color="red", zorder=5)
plt.axhline(y=0.05, color="green", linestyle="--", label="有意水準 $\\alpha = 0.05$")
# グラフ設定
plt.xlabel("真の平均 $\\mu$", fontsize=12)
plt.ylabel("検出力 (Power)", fontsize=12)
plt.title("理論値とシミュレーションによる検出力の比較", fontsize=14)
plt.legend()
plt.grid(True)
plt.show()
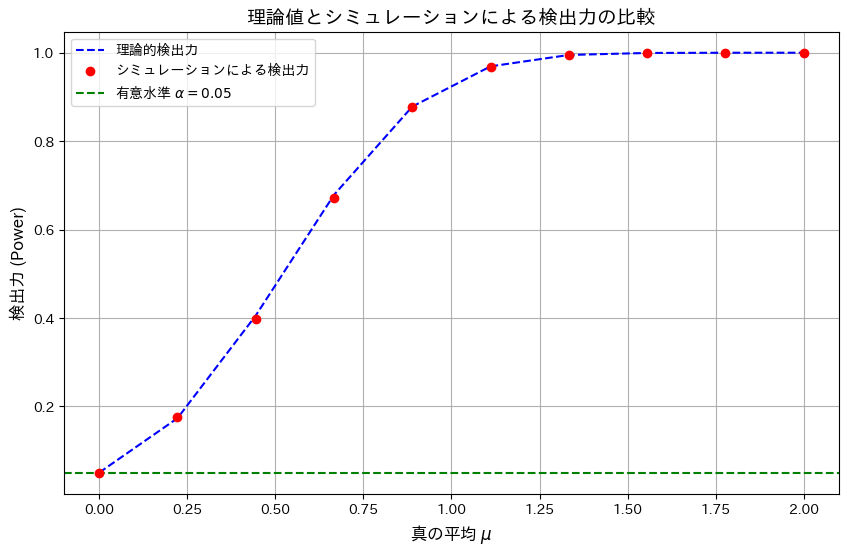
検出力は理論値とシミュレーションでよく一致し、検定が正しく機能していることを確認しました。また、真の平均μ>0に対して検出力が単調増加することが分かり、この検定が一様最強力検定の特徴を備えていることが確認できました。
2015 Q2(4)
標本平均の片側検定での検出力を特定の値以上にするために必要なサンプル数を求めました。
コード
有意水準α=0.05において、標本サイズnと検出力の関係を理論値とシミュレーションで比較し、目標の検出力0.8を達成するために必要な標本サイズnを調べます。
# 2015 Q2(4) 2024.12.10
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 設定
alpha = 0.05 # 有意水準
target_power = 0.8 # 目標検出力
mu = 0.5 # 真の平均
z_alpha = norm.ppf(1 - alpha) # 臨界値 z_alpha
z_power = norm.ppf(target_power) # 検出力に対応する Z 値
# 理論的な検出力の計算
n_values = np.arange(1, 51, 1) # 標本の大きさ n = 1, 2, ..., 50
powers_theoretical = [1 - norm.cdf(z_alpha - mu * np.sqrt(n)) for n in n_values]
# 実際の検出力を乱数シミュレーションで計算
num_simulations = 10000 # シミュレーション回数
n_sim_values = np.arange(5, 51, 5) # n = 5, 10, ..., 50
powers_simulated = []
for n in n_sim_values:
# 標本平均を生成
samples = np.random.normal(mu, 1 / np.sqrt(n), num_simulations)
# 標本平均が臨界値を超えた割合を計算
rejection_rate = np.mean(samples > z_alpha / np.sqrt(n))
powers_simulated.append(rejection_rate)
# グラフの描画
plt.figure(figsize=(10, 6))
# 理論的な検出力の曲線
plt.plot(n_values, powers_theoretical, label="理論的な検出力 (Power)", color="blue")
# シミュレーションによる検出力
plt.scatter(n_sim_values, powers_simulated, color="red", label="シミュレーションによる検出力", zorder=5)
# 検出力の目標ラインと必要な標本サイズライン
plt.axhline(y=target_power, color="red", linestyle="--", label=f"目標検出力 Power = {target_power}")
plt.axvline(x=25, color="green", linestyle="--", label="必要な標本数 n = 25")
# グラフの設定
plt.xlabel("標本の大きさ $n$", fontsize=12)
plt.ylabel("検出力 (Power)", fontsize=12)
plt.title("理論値とシミュレーションによる検出力の比較", fontsize=14)
plt.legend()
plt.grid(True)
plt.show()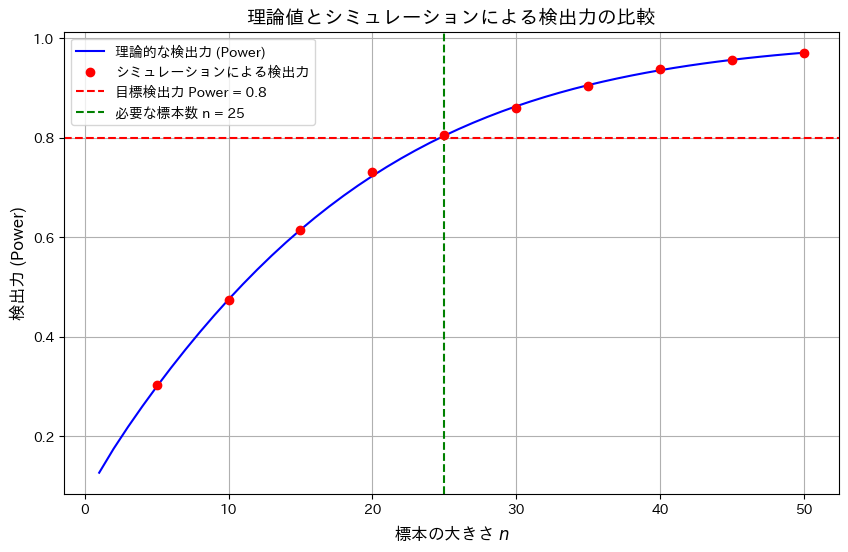
標本サイズnの増加が検出力の向上に寄与することを確認しました。また理論とシミュレーション結果が一致し、目標の検出力0.8を達成するためにはn=25が必要であることが確認できました。