ホーム » コードあり (ページ 11)
「コードあり」カテゴリーアーカイブ
2018 Q2(5)-1
非復元無作為抽出による未知の母数N個の推定を行いました。

コード
複数回シミュレーションし のヒストグラムを描画します。
のヒストグラムを描画します。
# 2018 Q2(5)-1 2024.10.9
import numpy as np
import matplotlib.pyplot as plt
# パラメータの設定
N_true = 100 # 真の青球の数 N (これを推定する)
K = 30 # 赤球の数 K (既知)
n = 20 # 抽出する回数
n_trials = 10000 # シミュレーションの試行回数
# 推定量 Nハットのシミュレーション
N_hat_values = []
for _ in range(n_trials):
# 青球 N 個 + 赤球 K 個のボールを作成
balls = [0] * N_true + [1] * K # 0が青球、1が赤球
drawn_balls = np.random.choice(balls, size=n, replace=False) # 非復元抽出
X = np.sum(drawn_balls) # 抽出された赤球の個数
# X を使って N の推定量 N_hat を計算
if X > 0: # Xが0でない場合
N_hat = K * (n - X) / X
N_hat_values.append(N_hat)
# シミュレーション結果の分析
N_hat_mean = np.mean(N_hat_values)
N_hat_var = np.var(N_hat_values)
# 結果表示
print(f"推定量 N_hat の平均: {N_hat_mean}")
print(f"推定量 N_hat の分散: {N_hat_var}")
# ヒストグラム表示
plt.figure(figsize=(10, 6))
plt.hist(N_hat_values, bins=50, density=True, alpha=0.7, color='b', edgecolor='black')
plt.axvline(x=N_true, color='r', linestyle='--', label=f'真の N = {N_true}')
plt.title(f'推定量 N_hat の分布 (N={N_true}, K={K}, n={n})')
plt.xlabel('推定量 N_hat')
plt.ylabel('確率密度')
plt.legend()
plt.grid(True)
plt.show()推定量 N_hat の平均: 126.09541441704363
推定量 N_hat の分散: 8070.195087794488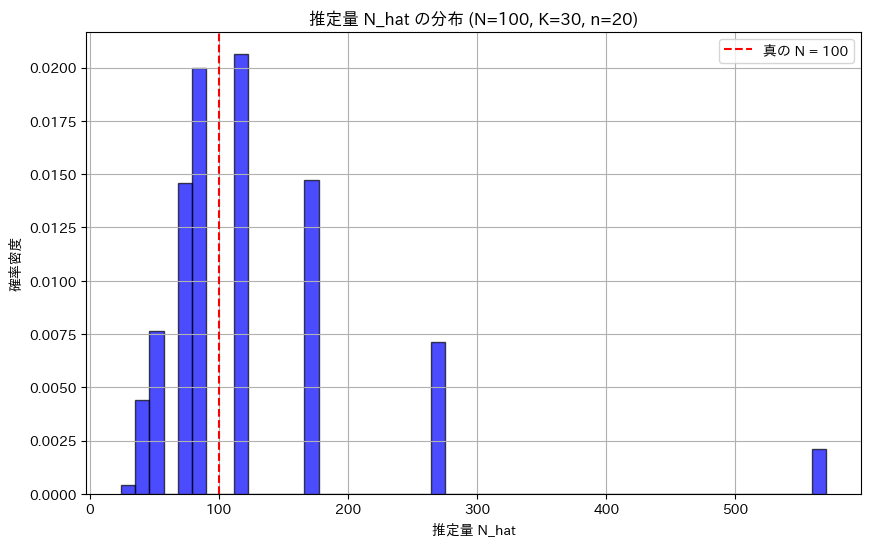
 は、真のNから離れた値も取ることがあり、特に飛び飛びの値を取りやすく、右側に裾が長い形をしていることが分かりました。
は、真のNから離れた値も取ることがあり、特に飛び飛びの値を取りやすく、右側に裾が長い形をしていることが分かりました。
2018 Q2(4)
超幾何分布の期待値と分散を求めました。

コード
NとMを変化させて期待値E[X]と分散V[X]についてシミュレーションを行い理論値と一致するか確認します。
# 2018 Q2(4) 2024.10.8
import numpy as np
import matplotlib.pyplot as plt
# パラメータの設定
N_values = [50, 70, 100] # 総球数 N のバリエーション
M_steps = 10 # 赤球のステップ数
n = 10 # 抽出回数
n_trials = 10000 # シミュレーションの試行回数
# グラフ描画の準備
plt.figure(figsize=(12, 8))
for N in N_values:
M_values = np.arange(M_steps, N + 1, M_steps) # 赤球数をステップで変化
# 理論値の計算
E_X_theory = n * M_values / N
V_X_theory = n * M_values / N * (N - M_values) / N * (N - n) / (N - 1)
# シミュレーションによる期待値と分散の計算
E_X_simulation = []
V_X_simulation = []
for M in M_values:
X_values = []
for _ in range(n_trials):
balls = [1] * M + [0] * (N - M)
drawn_balls = np.random.choice(balls, size=n, replace=False)
X_values.append(np.sum(drawn_balls)) # 赤球の数
E_X_simulation.append(np.mean(X_values))
V_X_simulation.append(np.var(X_values))
# 期待値のグラフに追加描画
plt.subplot(2, 1, 1) # 期待値のグラフ (上側)
plt.plot(M_values, E_X_theory, label=f'理論値 (N={N})', linestyle='--')
plt.plot(M_values, E_X_simulation, label=f'シミュレーション (N={N})', marker='o', linestyle='None')
# 分散のグラフに追加描画
plt.subplot(2, 1, 2) # 分散のグラフ (下側)
plt.plot(M_values, V_X_theory, label=f'理論値 (N={N})', linestyle='--')
plt.plot(M_values, V_X_simulation, label=f'シミュレーション (N={N})', marker='o', linestyle='None')
# グラフの設定
plt.subplot(2, 1, 1)
plt.xlabel('赤球の数 (M)')
plt.ylabel('期待値 E[X]')
plt.title('異なる N における期待値 E[X] の理論値とシミュレーション結果の比較')
plt.legend()
plt.grid(True)
plt.subplot(2, 1, 2)
plt.xlabel('赤球の数 (M)')
plt.ylabel('分散 V[X]')
plt.title('異なる N における分散 V[X] の理論値とシミュレーション結果の比較')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()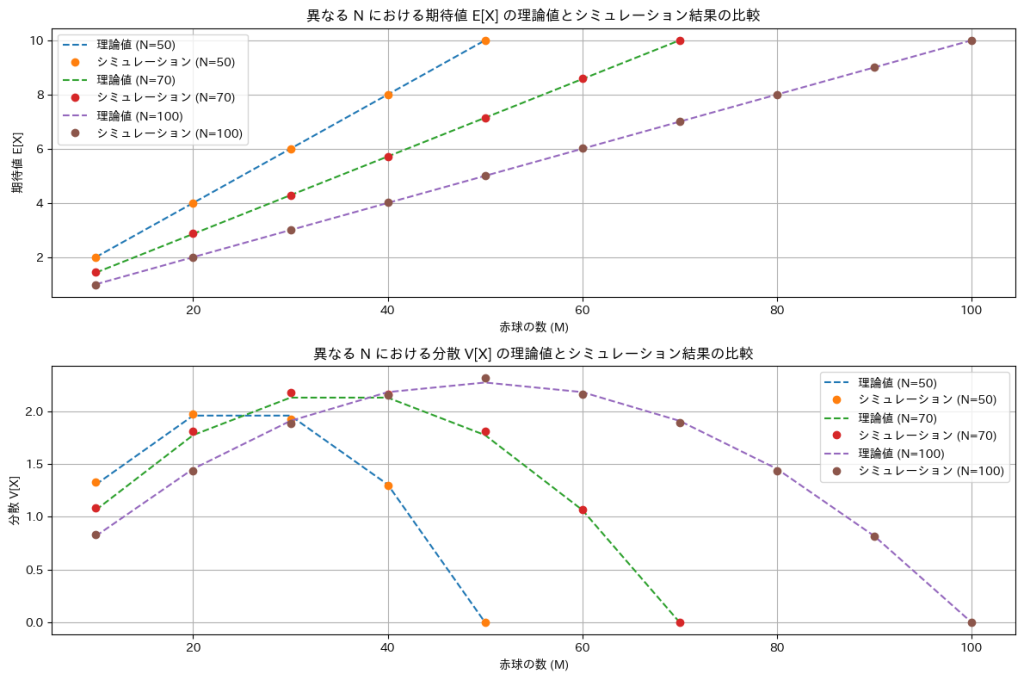
ミュレーションによる結果は理論値と一致しました。
2018 Q2(3)
非復元無作為抽出の当たり数を確率変数とする確率質量関数を求めました。

コード
超幾何分布HG(N,M,n)に従う確率変数XのシミュレーションをNとMを変化させて実行し理論値と一致するか確認してみます。
# 2018 Q2(3) 2024.10.7
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import hypergeom
# パラメータの設定
N_values = [50, 70, 100] # 総球数 N のバリエーション (列ごとに固定)
M_values = [10, 20, 30, 40, 50] # 赤球の数 M のバリエーション (行ごとに変化)
n = 10 # 抽出する回数
n_trials = 10000 # シミュレーションの試行回数
# グラフのレイアウト設定 (5行x3列)
fig, axes = plt.subplots(5, 3, figsize=(15, 20)) # 5行3列のサブプロット
# 各 M に対してシミュレーションと理論値を計算
for row, M in enumerate(M_values): # 行が M を表す
for col, N in enumerate(N_values): # 列が N を表す
# 理論値の計算
x_values = np.arange(0, n + 1) # 可能な赤球の数 x の範囲
rv = hypergeom(N, M, n) # 超幾何分布のインスタンス
P_X_theory = rv.pmf(x_values) # 理論値(超幾何分布)
# シミュレーションによる確率計算
drawn_red_balls = []
for _ in range(n_trials):
balls = [1] * M + [0] * (N - M) # 赤球 M 個、青球 N-M 個のリスト
drawn_balls = np.random.choice(balls, size=n, replace=False) # n 回非復元抽出
x = np.sum(drawn_balls) # 赤球の個数を数える
drawn_red_balls.append(x)
# 各サブプロットにグラフを描画
ax = axes[row, col]
ax.plot(x_values, P_X_theory, 'bo-', label=f'理論値 (N={N}, M={M})')
ax.hist(drawn_red_balls, bins=np.arange(-0.5, n + 1.5, 1), density=True, alpha=0.6, color='r', label='シミュレーション結果')
ax.set_xlabel('赤球の個数 (x)')
ax.set_ylabel('確率 P(X = x)')
ax.set_title(f'N={N}, M={M}, n={n}')
ax.grid(True)
# 全体のレイアウト調整
plt.tight_layout()
plt.show()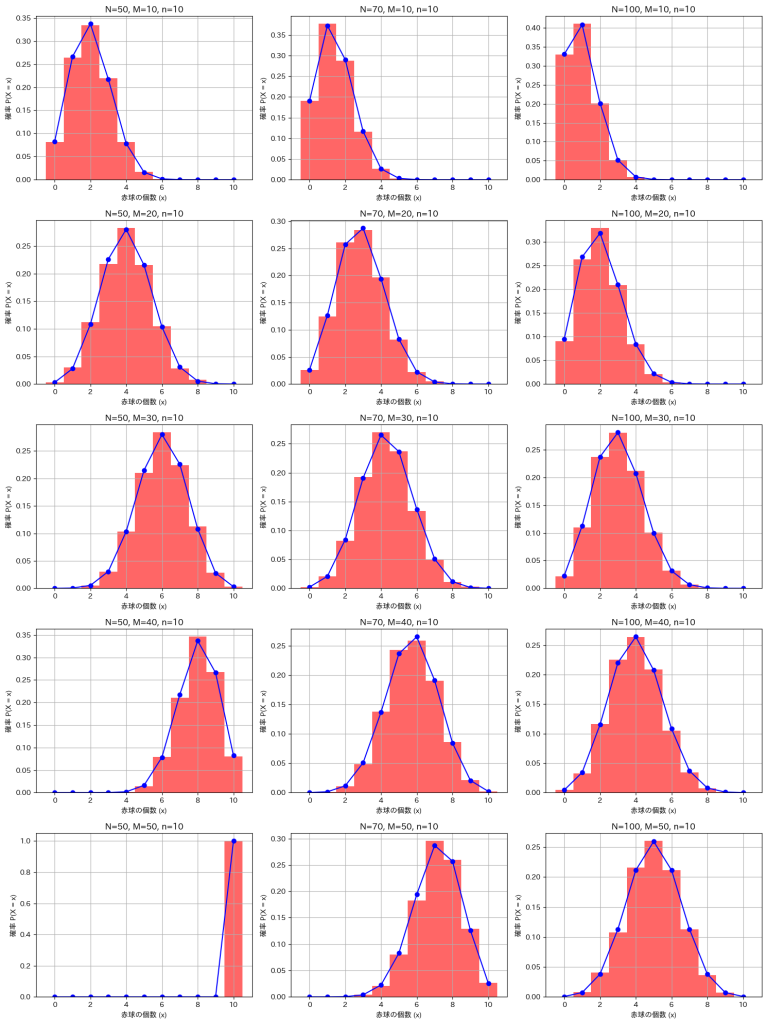
シミュレーションによる結果は理論値と一致しました。
2018 Q2(2)
非復元無作為抽出の期待値と分散と共分散を求めました。
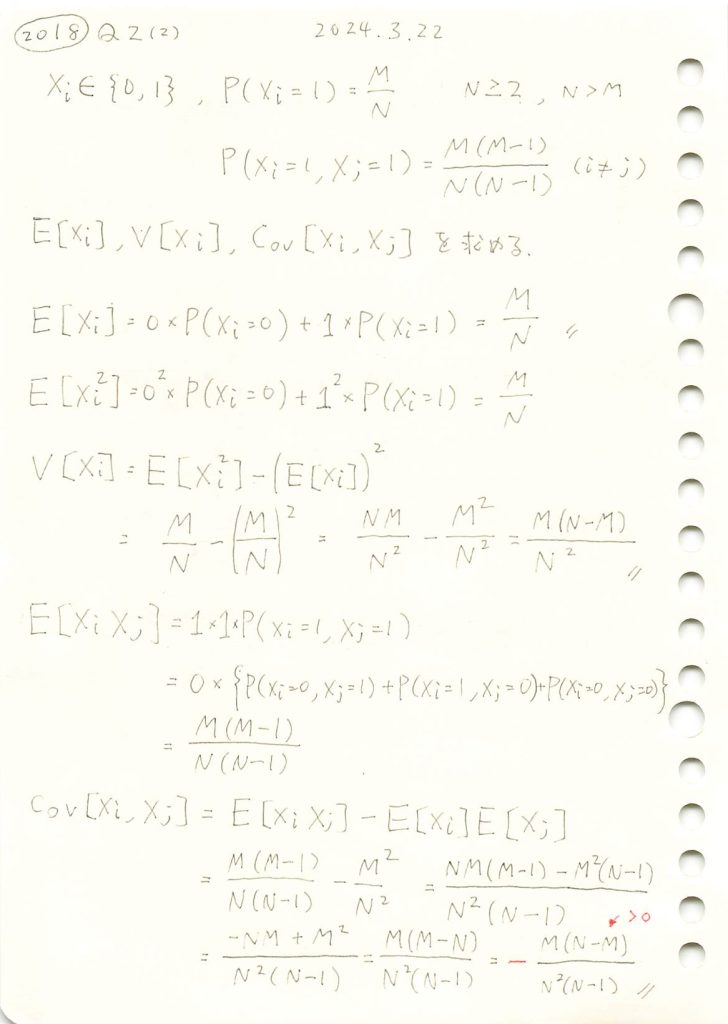
コード
NとMを変化させて期待値E[Xi]についてシミュレーションを行い理論値と一致するか確認します。
# 2018 Q2(2) 2024.10.6
import numpy as np
import matplotlib.pyplot as plt
# パラメータの設定
N_values = [50, 70, 100] # 総球数 N のバリエーション
M_steps = 10 # 赤球のステップ数
n_trials = 10000 # シミュレーションの試行回数
# 期待値 E[X_i] のグラフ描画
plt.figure(figsize=(10, 6))
for N in N_values:
M_values = np.arange(2, N + 1, M_steps) # 赤球数をステップで変化
# 理論値の計算
E_Xi_theory = M_values / N
# シミュレーションによる期待値の計算
E_Xi_simulation = []
for M in M_values:
count_Xi_1 = 0
for _ in range(n_trials):
balls = [1] * M + [0] * (N - M)
drawn_ball = np.random.choice(balls, size=1, replace=False)
count_Xi_1 += drawn_ball[0]
E_Xi_simulation.append(count_Xi_1 / n_trials)
# グラフに追加描画
plt.plot(M_values, E_Xi_theory, label=f'理論値 (N={N})', linestyle='--')
plt.plot(M_values, E_Xi_simulation, label=f'シミュレーション (N={N})', marker='o', linestyle='None')
plt.xlabel('赤球の数 (M)')
plt.ylabel('期待値 E[X_i]')
plt.title('異なる N における 期待値 E[X_i] の理論値とシミュレーション結果の比較')
plt.legend()
plt.grid(True)
plt.show()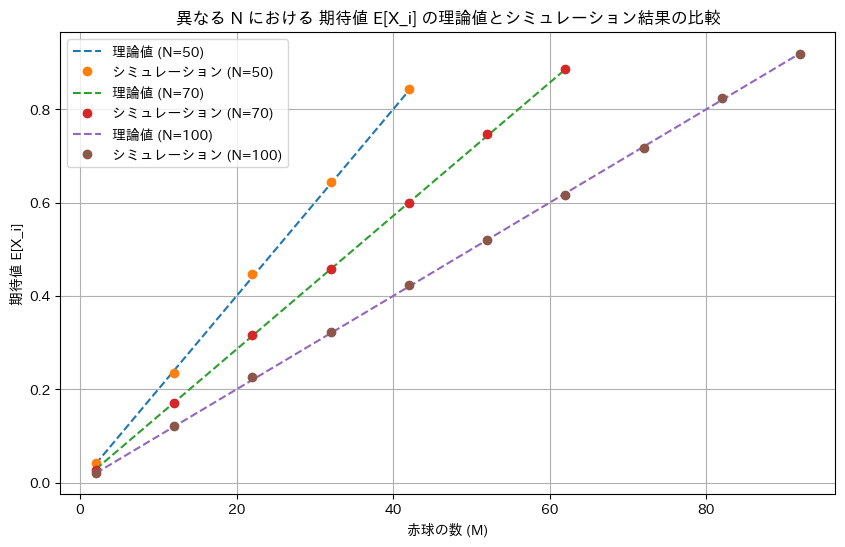
ミュレーションによる結果は理論値と一致しました。
次に、分散V[Xi]についてシミュレーションを行い理論値と一致するか確認します。
# 2018 Q2(2) 2024.10.6
import numpy as np
import matplotlib.pyplot as plt
# パラメータの設定
N_values = [50, 70, 100] # 総球数 N のバリエーション
M_steps = 10 # 赤球のステップ数
n_trials = 10000 # シミュレーションの試行回数
# 分散 V[X_i] のグラフ描画
plt.figure(figsize=(10, 6))
for N in N_values:
M_values = np.arange(2, N + 1, M_steps)
# 理論値の計算
V_Xi_theory = M_values * (N - M_values) / N**2
# シミュレーションによる分散の計算
V_Xi_simulation = []
for M in M_values:
Xi_values = []
for _ in range(n_trials):
balls = [1] * M + [0] * (N - M)
drawn_ball = np.random.choice(balls, size=1, replace=False)
Xi_values.append(drawn_ball[0])
V_Xi_simulation.append(np.var(Xi_values))
# グラフに追加描画
plt.plot(M_values, V_Xi_theory, label=f'理論値 (N={N})', linestyle='--')
plt.plot(M_values, V_Xi_simulation, label=f'シミュレーション (N={N})', marker='o', linestyle='None')
plt.xlabel('赤球の数 (M)')
plt.ylabel('分散 V[X_i]')
plt.title('異なる N における 分散 V[X_i] の理論値とシミュレーション結果の比較')
plt.legend()
plt.grid(True)
plt.show()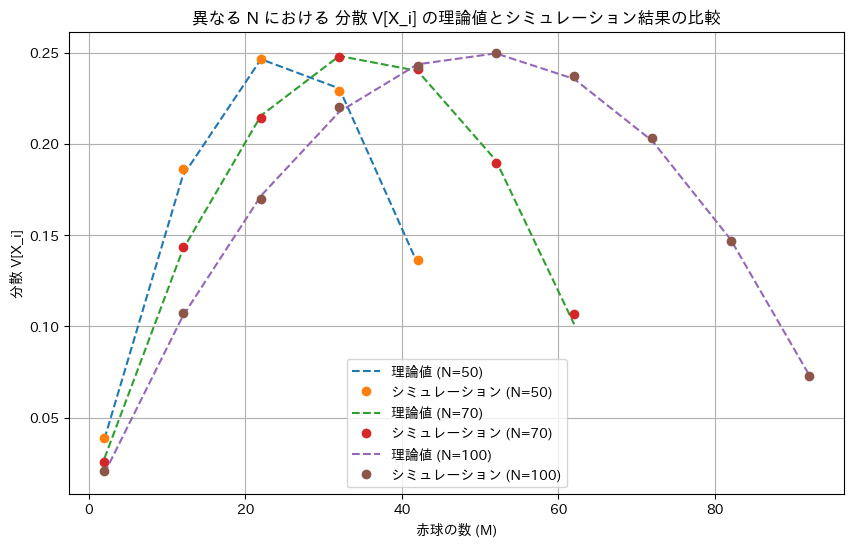
ミュレーションによる結果は理論値と一致しました。
次に、共分散Cov[Xi,Xj]についてシミュレーションを行い理論値と一致するか確認します。ただし、共分散は二変数を扱うため誤差が大きくなりやすいので、シミュレーションの試行回数を多め(1,000,000回)でやってみます。実行は環境により数十分かかることもあります。
# 2018 Q2(2) 2024.10.6
import numpy as np
import matplotlib.pyplot as plt
# パラメータの設定
N_values = [50, 70, 100] # 総球数 N のバリエーション
M_steps = 10 # 赤球のステップ数
n_trials = 1000000 # シミュレーションの試行回数
# 共分散 Cov[X_i, X_j] のグラフ描画
plt.figure(figsize=(10, 6))
for N in N_values:
M_values = np.arange(2, N + 1, M_steps)
# 理論値の計算
Cov_Xi_Xj_theory = -(M_values * (N - M_values)) / (N**2 * (N - 1))
# シミュレーションによる共分散の計算
Cov_Xi_Xj_simulation = []
for M in M_values:
Xi_values = []
Xj_values = []
for _ in range(n_trials):
balls = [1] * M + [0] * (N - M)
drawn_balls = np.random.choice(balls, size=2, replace=False)
Xi_values.append(drawn_balls[0])
Xj_values.append(drawn_balls[1])
Cov_Xi_Xj_simulation.append(np.cov(Xi_values, Xj_values)[0, 1])
# グラフに追加描画
plt.plot(M_values, Cov_Xi_Xj_theory, label=f'理論値 (N={N})', linestyle='--')
plt.plot(M_values, Cov_Xi_Xj_simulation, label=f'シミュレーション (N={N})', marker='o', linestyle='None')
plt.xlabel('赤球の数 (M)')
plt.ylabel('共分散 Cov[X_i, X_j]')
plt.title('異なる N における 共分散 Cov[X_i, X_j] の理論値とシミュレーション結果の比較')
plt.legend()
plt.grid(True)
plt.show()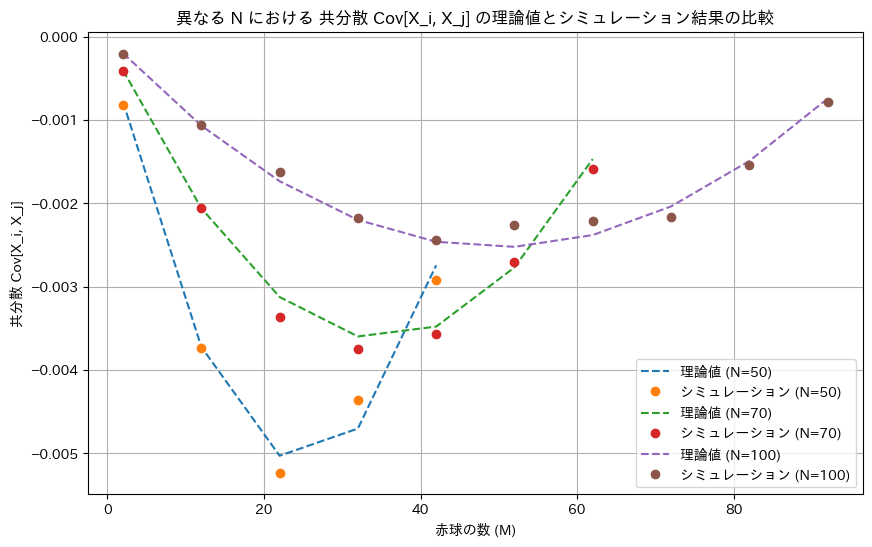
シミュレーションによる結果は概ね一致しました。
2018 Q2(1)-2
非復元無作為抽出でi番目とj番目が当たりになる確率を求めました。

コード
NとMを変化させてシミュレーションを行い理論値と一致するか確認します。
# 2018 Q2(1)-2 2024.10.5
import numpy as np
import matplotlib.pyplot as plt
# パラメータの設定
N_values = [50, 70, 100] # 総球数 N のバリエーション
M_steps = 10 # 赤球のステップ数を指定
n_trials = 10000 # シミュレーションの試行回数
# グラフ描画の準備
plt.figure(figsize=(10, 6))
# 各 N に対してシミュレーションと理論値を計算
for N in N_values:
M_values = np.arange(2, N + 1, M_steps) # 赤球数をステップで変化 (M >= 2 に設定)
# 理論値の計算
P_Xi_Xj_theory = (M_values / N) * ((M_values - 1) / (N - 1))
# シミュレーションによる確率計算
P_Xi_Xj_simulation = []
for M in M_values:
count_Xi_Xj_1 = 0
for _ in range(n_trials):
# 箱の中の球を準備(赤球 M 個、青球 N-M 個)
balls = [1] * M + [0] * (N - M)
# 非復元抽出で2つの球を無作為に抽出
drawn_balls = np.random.choice(balls, size=2, replace=False)
# 2回連続で赤球が引かれたか確認
if drawn_balls[0] == 1 and drawn_balls[1] == 1:
count_Xi_Xj_1 += 1
# シミュレーション結果の確率
P_Xi_Xj_simulation.append(count_Xi_Xj_1 / n_trials)
# グラフに追加描画
plt.plot(M_values, P_Xi_Xj_theory, label=f'理論値 (N={N})', linestyle='--')
plt.plot(M_values, P_Xi_Xj_simulation, label=f'シミュレーション (N={N})', marker='o', linestyle='None')
# グラフのラベルとタイトル設定
plt.xlabel('赤球の数 (M)')
plt.ylabel('P(X_i = 1, X_j = 1) の確率')
plt.title('異なる N における P(X_i = 1, X_j = 1) の理論値とシミュレーション結果の比較')
plt.legend()
plt.grid(True)
plt.show()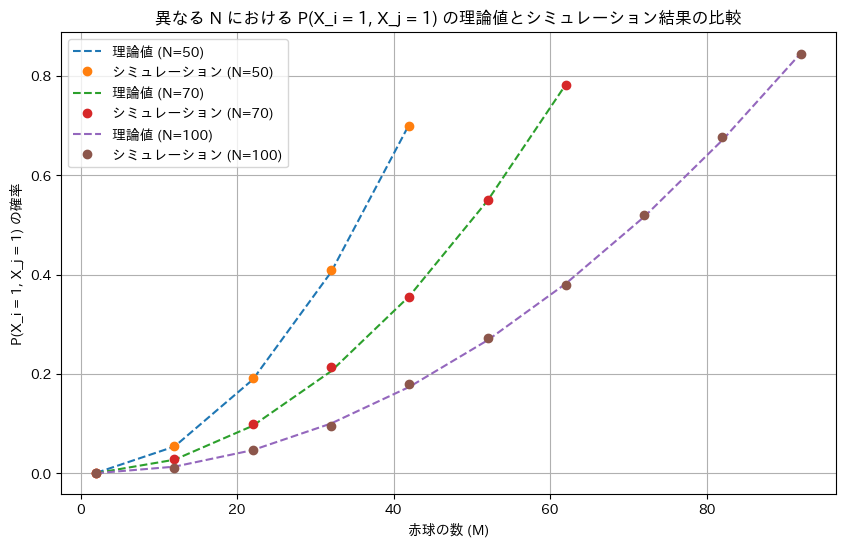
シミュレーションによる結果は理論値と一致しました。
2018 Q2(1)-1
非復元無作為抽出で当たりの出る確率を求めました。

コード
NとMを変化させてシミュレーションを行い理論値と一致するか確認します。
# 2018 Q2(1)-1 2024.10.5
import numpy as np
import matplotlib.pyplot as plt
# パラメータの設定
N_values = [50, 70, 100] # 総球数 N のバリエーション
M_steps = 10 # 赤球のステップ数を指定
n_trials = 10000 # シミュレーションの試行回数
# グラフ描画の準備
plt.figure(figsize=(10, 6))
# 各 N に対してシミュレーションと理論値を計算
for N in N_values:
M_values = np.arange(1, N + 1, M_steps) # 赤球数をステップで変化
P_Xi_1_theory = M_values / N # 理論値
# シミュレーションによる確率計算
P_Xi_1_simulation = []
for M in M_values:
count_Xi_1 = 0
for _ in range(n_trials):
# 箱の中の球を準備(赤球 M 個、青球 N-M 個)
balls = [1] * M + [0] * (N - M)
# 1回の無作為抽出で赤球が引かれるかどうかを確認
drawn_ball = np.random.choice(balls)
if drawn_ball == 1:
count_Xi_1 += 1
# シミュレーション結果の確率
P_Xi_1_simulation.append(count_Xi_1 / n_trials)
# グラフに追加描画
plt.plot(M_values, P_Xi_1_theory, label=f'理論値 (N={N})', linestyle='--')
plt.plot(M_values, P_Xi_1_simulation, label=f'シミュレーション (N={N})', marker='o', linestyle='None')
# グラフのラベルとタイトル設定
plt.xlabel('赤球の数 (M)')
plt.ylabel('P(X_i = 1) の確率')
plt.title('異なる N における理論値とシミュレーション結果の比較')
plt.legend()
plt.grid(True)
plt.show()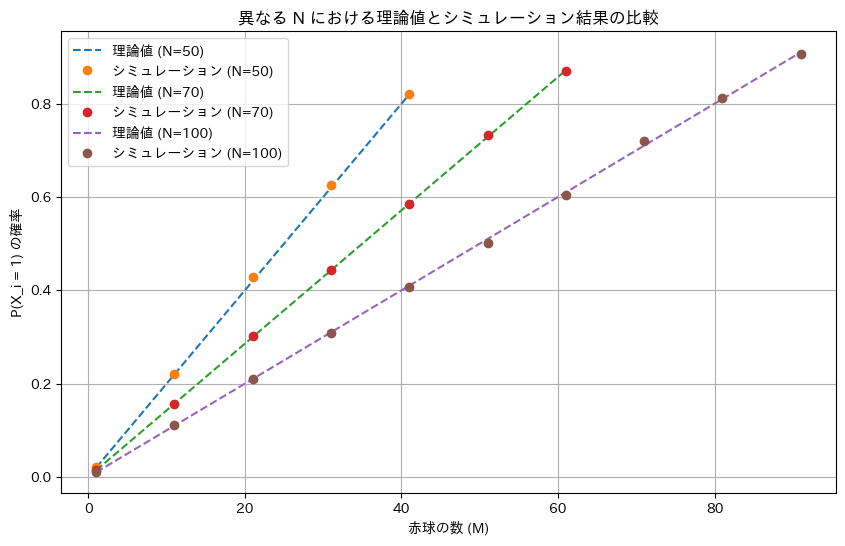
シミュレーションによる結果は理論値と一致しました。
2018 Q1(4)-2
(別解)不偏分散の平方根の期待値の母標準偏差に対する偏りを求めました。
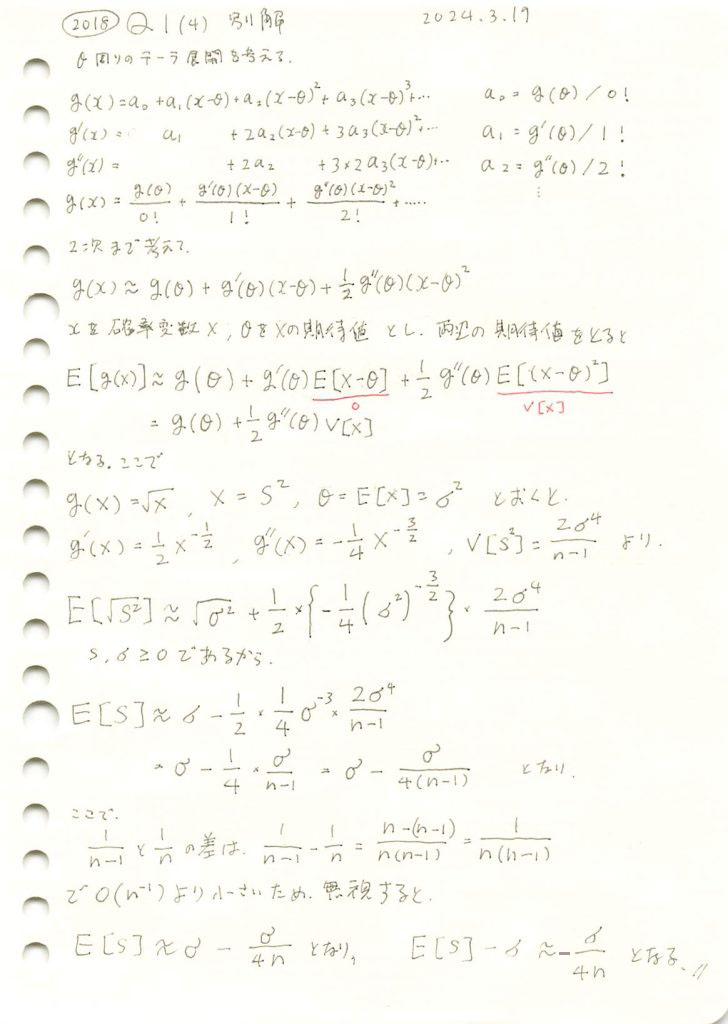
コード
数値シミュレーションでE[S] 求め、理論値![E[S] = \sigma - \frac{\sigma}{4n}](https://statistics.blue/wp-content/ql-cache/quicklatex.com-6087946335ec7d9b0f7f98e97af974ed_l3.png "Rendered by QuickLaTeX.com") と一致するか確認します。
と一致するか確認します。
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
sigma = 2 # 母標準偏差
n_values = np.array([10, 20, 50, 100, 200]) # サンプルサイズの値
num_simulations = 10000 # シミュレーションの回数
# 結果を格納するリスト
simulated_means = []
theoretical_means = []
sigma_values = [sigma] * len(n_values) # 母標準偏差の値をリストで作成
# シミュレーション実行
for n in n_values:
# カイ二乗分布に従う乱数を生成
chi_squared_samples = np.random.chisquare(df=n-1, size=num_simulations)
# 標本標準偏差 S のシミュレーション
S_simulation = sigma * np.sqrt(chi_squared_samples / (n - 1))
# シミュレーションの期待値 (平均)
simulated_mean = np.mean(S_simulation)
simulated_means.append(simulated_mean)
# 理論値 E[S] = σ - σ / (4n)
theoretical_mean = sigma - sigma / (4 * n)
theoretical_means.append(theoretical_mean)
# 結果表示
for i, n in enumerate(n_values):
print(f"n = {n}: シミュレーション平均 = {simulated_means[i]:.4f}, 理論値 = {theoretical_means[i]:.4f}, 母標準偏差 = {sigma:.4f}")
# グラフ描画
plt.figure(figsize=(8, 6))
plt.plot(n_values, simulated_means, 'bo-', label='シミュレーション平均')
plt.plot(n_values, theoretical_means, 'r--', label='理論値')
plt.plot(n_values, sigma_values, 'g-', label='母標準偏差 σ')
plt.xlabel('サンプルサイズ n')
plt.ylabel('期待値 E[S]')
plt.title('標本標準偏差 E[S] のシミュレーションと理論値の比較')
plt.legend()
plt.grid(True)
plt.show()n = 10: シミュレーション平均 = 1.9394, 理論値 = 1.9500, 母標準偏差 = 2.0000
n = 20: シミュレーション平均 = 1.9747, 理論値 = 1.9750, 母標準偏差 = 2.0000
n = 50: シミュレーション平均 = 1.9888, 理論値 = 1.9900, 母標準偏差 = 2.0000
n = 100: シミュレーション平均 = 1.9961, 理論値 = 1.9950, 母標準偏差 = 2.0000
n = 200: シミュレーション平均 = 1.9974, 理論値 = 1.9975, 母標準偏差 = 2.0000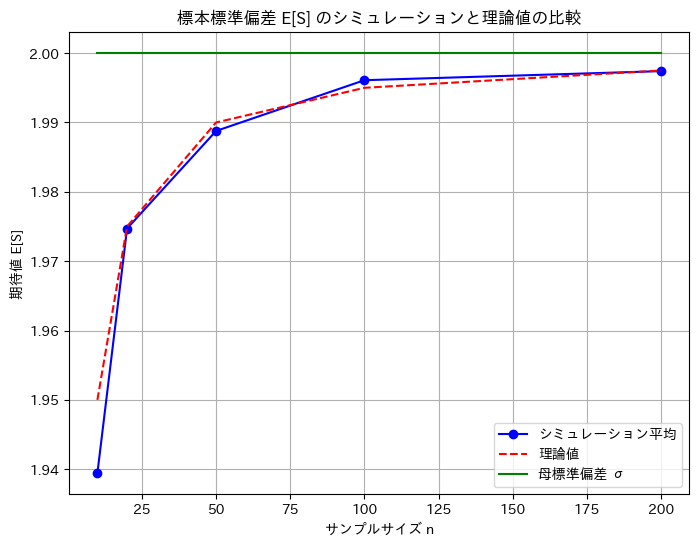
数値シミュレーションでのE[S]は、理論値に一致することが確認できました。
2018 Q1(4)-1
不偏分散の平方根の期待値に於いて、母標準偏差に対する偏りを求めました。
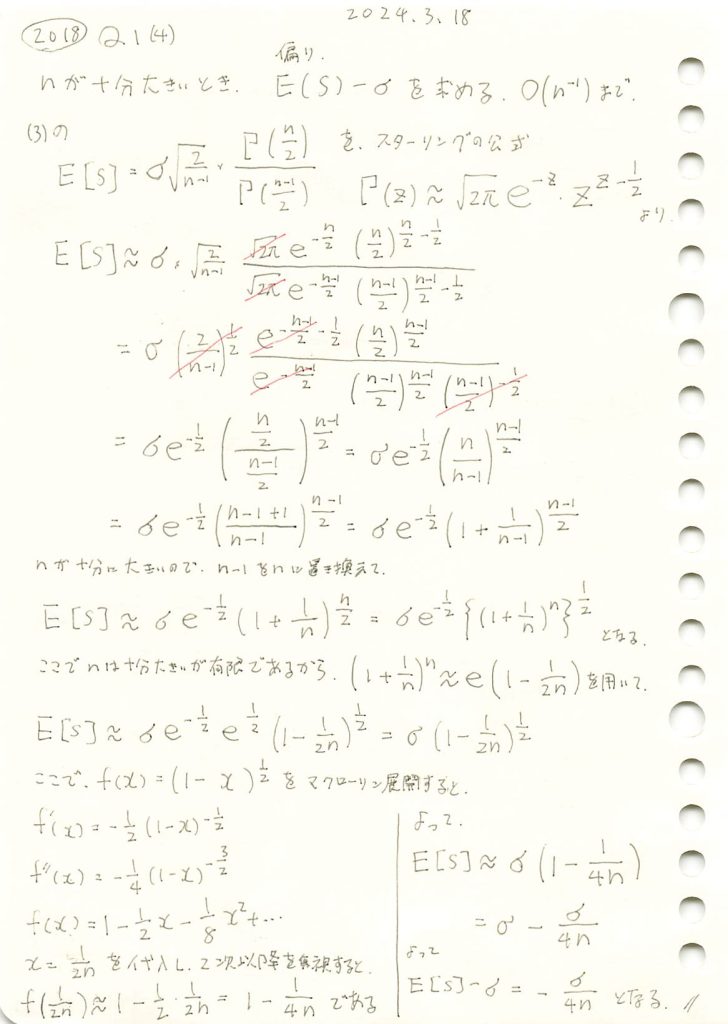
コード
数値シミュレーションでE[S] 求め、理論値と一致するか確認します。
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
sigma = 2 # 母標準偏差
n_values = np.array([10, 20, 50, 100, 200]) # サンプルサイズの値
num_simulations = 10000 # シミュレーションの回数
# 結果を格納するリスト
simulated_means = []
theoretical_means = []
sigma_values = [sigma] * len(n_values) # 母標準偏差の値をリストで作成
# シミュレーション実行
for n in n_values:
# カイ二乗分布に従う乱数を生成
chi_squared_samples = np.random.chisquare(df=n-1, size=num_simulations)
# 標本標準偏差 S のシミュレーション
S_simulation = sigma * np.sqrt(chi_squared_samples / (n - 1))
# シミュレーションの期待値 (平均)
simulated_mean = np.mean(S_simulation)
simulated_means.append(simulated_mean)
# 理論値 E[S] = σ - σ / (4n)
theoretical_mean = sigma - sigma / (4 * n)
theoretical_means.append(theoretical_mean)
# 結果表示
for i, n in enumerate(n_values):
print(f"n = {n}: シミュレーション平均 = {simulated_means[i]:.4f}, 理論値 = {theoretical_means[i]:.4f}, 母標準偏差 = {sigma:.4f}")
# グラフ描画
plt.figure(figsize=(8, 6))
plt.plot(n_values, simulated_means, 'bo-', label='シミュレーション平均')
plt.plot(n_values, theoretical_means, 'r--', label='理論値')
plt.plot(n_values, sigma_values, 'g-', label='母標準偏差 σ')
plt.xlabel('サンプルサイズ n')
plt.ylabel('期待値 E[S]')
plt.title('標本標準偏差 E[S] のシミュレーションと理論値の比較')
plt.legend()
plt.grid(True)
plt.show()n = 10: シミュレーション平均 = 1.9394, 理論値 = 1.9500, 母標準偏差 = 2.0000
n = 20: シミュレーション平均 = 1.9747, 理論値 = 1.9750, 母標準偏差 = 2.0000
n = 50: シミュレーション平均 = 1.9888, 理論値 = 1.9900, 母標準偏差 = 2.0000
n = 100: シミュレーション平均 = 1.9961, 理論値 = 1.9950, 母標準偏差 = 2.0000
n = 200: シミュレーション平均 = 1.9974, 理論値 = 1.9975, 母標準偏差 = 2.0000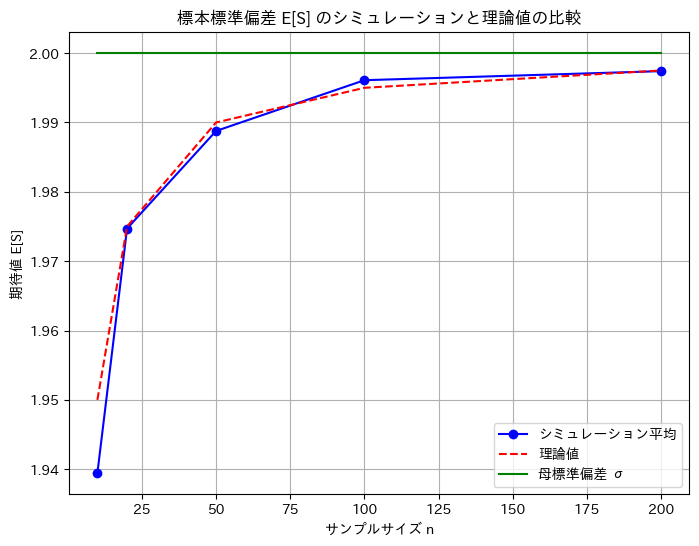
数値シミュレーションでのE[S]は、理論値に一致することが確認できました。
2018 Q1(3)
カイ二乗分布の平方根の期待値と標本標準偏差の期待値を求めました。不偏分散の期待値は母分散なのにその平方根の期待値は母標準偏差にはならないのが面白い。

コード
数式を使って期待値E[√Y]とE[S]を求めます。
# 2018 Q1(3) 2024.10.3
import sympy as sp
# 変数の定義
y, n, sigma = sp.symbols('y n sigma', positive=True)
k = n - 1 # 自由度
# カイ二乗分布の確率密度関数 g(y)
g_y = (1/2)**(k/2) * y**(k/2 - 1) * sp.exp(-y/2) / sp.gamma(k/2)
# 平方根の期待値 E[√Y] の積分を計算
E_sqrt_Y = sp.integrate(sp.sqrt(y) * g_y, (y, 0, sp.oo))
# 標本標準偏差 S の期待値 E[S] を計算
E_S = sigma * E_sqrt_Y / sp.sqrt(n-1)
# 結果の表示
display(E_sqrt_Y.simplify()) # E[√Y] の表示
display(E_S.simplify()) # E[S] の表示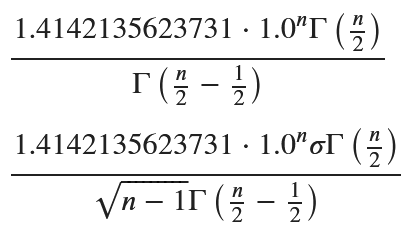
余分な1.0^nが含まれますが手計算と一致しました。
次に、期待値E[√Y]とE[S]を数値シミュレーションで求めてみます。
# 2018 Q1(3) 2024.10.3
import numpy as np
import matplotlib.pyplot as plt
from scipy.special import gamma
# パラメータ設定
n = 10 # サンプルサイズ (自由度は n-1)
degrees_of_freedom = n - 1 # 自由度
sigma = 2 # 母標準偏差
num_simulations = 10000 # シミュレーションの回数
# カイ二乗分布に従う乱数を生成
chi_squared_samples = np.random.chisquare(df=degrees_of_freedom, size=num_simulations)
# 平方根 E[√Y] のシミュレーション
sqrt_Y_simulation = np.mean(np.sqrt(chi_squared_samples))
# 標本標準偏差 S のシミュレーション
S_simulation = np.mean(sigma * np.sqrt(chi_squared_samples / (n - 1)))
# 理論値 E[√Y] と E[S] の計算
E_sqrt_Y_theoretical = np.sqrt(2) * gamma(n / 2) / gamma((n - 1) / 2)
E_S_theoretical = sigma * np.sqrt(2 / (n - 1)) * gamma(n / 2) / gamma((n - 1) / 2)
# 結果表示
print(f"平方根 E[√Y] の理論値: {E_sqrt_Y_theoretical:.4f}")
print(f"平方根 E[√Y] のシミュレーション結果: {sqrt_Y_simulation:.4f}")
print(f"標本標準偏差 E[S] の理論値: {E_S_theoretical:.4f}")
print(f"標本標準偏差 E[S] のシミュレーション結果: {S_simulation:.4f}")
# ヒストグラムの描画
plt.figure(figsize=(10, 6))
# 平方根 E[√Y] のヒストグラム
plt.hist(np.sqrt(chi_squared_samples), bins=50, alpha=0.5, color='b', edgecolor='black', label='sqrt(Y) サンプル', density=True)
# 標本標準偏差 E[S] のヒストグラム
plt.hist(sigma * np.sqrt(chi_squared_samples / (n - 1)), bins=50, alpha=0.5, color='r', edgecolor='black', label='S サンプル', density=True)
# 平方根 E[√Y] の理論値の線
plt.axvline(E_sqrt_Y_theoretical, color='blue', linestyle='dashed', linewidth=2, label='理論 E[√Y]')
# 標本標準偏差 E[S] の理論値の線
plt.axvline(E_S_theoretical, color='red', linestyle='dashed', linewidth=2, label='理論 E[S]')
# グラフの設定
plt.title('平方根 E[√Y] と 標本標準偏差 E[S] の分布')
plt.xlabel('値')
plt.ylabel('頻度')
plt.legend()
plt.grid(True)
plt.show()平方根 E[√Y] の理論値: 2.9180
平方根 E[√Y] のシミュレーション結果: 2.9222
標本標準偏差 E[S] の理論値: 1.9453
標本標準偏差 E[S] のシミュレーション結果: 1.9481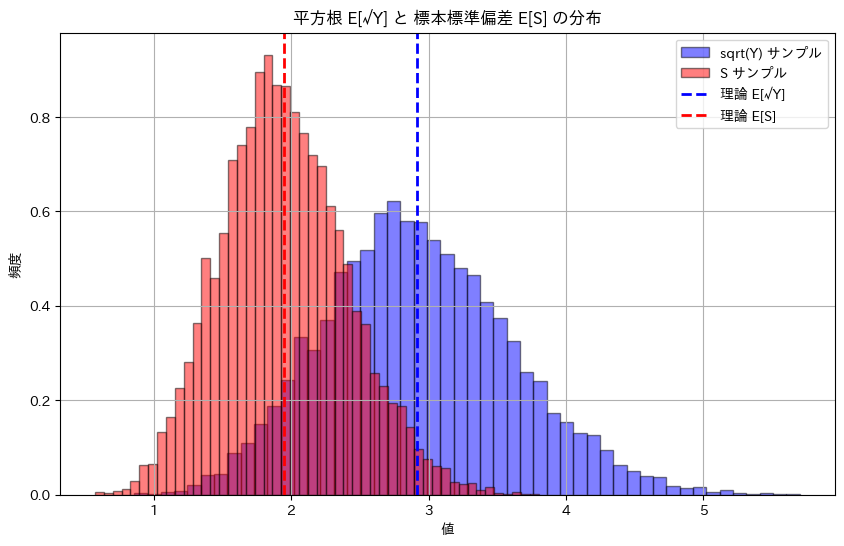
シミュレーションによる期待値E[√Y]とE[S]は理論値に近い値をとりました。E[S^2]=σ^2であっても面白いことにE[S]=σにはならない。上の例ではσ=2ですがシミュレーションと一致しません。標本標準偏差 Sは母標準偏差 σの不偏推定量ではないためです。
2018 Q1(2)-3
不偏分散の分散を求めました。
コード
数値シミュレーションにより標本分散の分散を求めてみます。
# 2018 Q1(2) 2024.10.2
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
sigma = 2 # 母分散の標準偏差
sigma_squared = sigma ** 2 # 母分散
n = 30 # サンプルサイズ
num_simulations = 10000 # シミュレーションの回数
# 理論上の標本分散の分散 Var(S^2)
theoretical_variance = (2 * sigma_squared ** 2) / (n - 1)
# シミュレーション結果を保存するリスト
sample_variances = []
# シミュレーションを繰り返す
for _ in range(num_simulations):
# 正規分布 N(0, sigma^2) に従うサンプルを生成
sample = np.random.normal(0, sigma, n)
# 標本平均
sample_mean = np.mean(sample)
# 標本分散 (S^2)
sample_variance = np.sum((sample - sample_mean) ** 2) / (n - 1)
# 計算した標本分散をリストに追加
sample_variances.append(sample_variance)
# サンプル分散の分散を計算
empirical_variance = np.var(sample_variances)
# 結果表示
print(f"理論的な標本分散の分散: {theoretical_variance:.4f}")
print(f"シミュレーションで得られた標本分散の分散: {empirical_variance:.4f}")
# ヒストグラムを描画して標本分散の分布を確認
plt.hist(sample_variances, bins=50, alpha=0.7, color='b', edgecolor='black')
plt.axvline(np.mean(sample_variances), color='r', linestyle='dashed', linewidth=2, label='平均分散')
plt.title('標本分散の分布')
plt.xlabel('標本分散 S^2')
plt.ylabel('頻度')
plt.legend()
plt.grid(True)
plt.show()理論的な標本分散の分散: 1.1034
シミュレーションで得られた標本分散の分散: 1.1286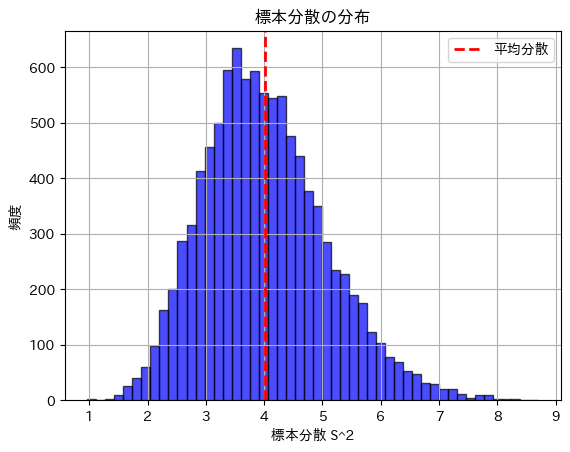
標本分散の分散は理論値に近い値になりました。