2021 Q3(2)[2-1]
ポアソン分布の再生性をモーメント母関数の積から示す問題をやりました。

コード
数式を使った計算
# 2021 Q3(2)[2-1] 2024.8.26
import sympy as sp
# 変数の定義
s, lambda_, n = sp.symbols('s lambda_ n', real=True, positive=True)
# 各 X_i のモーメント母関数
M_X = sp.exp(lambda_ * (sp.exp(s) - 1))
# 和 T のモーメント母関数 M_T(s)
M_T = M_X**n
# M_T(s) を簡略化
M_T_simplified = sp.simplify(M_T)
# 結果を表示
display(M_T_simplified)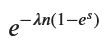
Po(nλ)のモーメント母関数に等しいです。
モーメント母関数を使って期待値と分散を求めます。
# 2021 Q3(2)[2-1] 2024.8.26
import sympy as sp
# 変数の定義
s, lambda_, n = sp.symbols('s lambda_ n', real=True, positive=True)
# モーメント母関数 M_T(s)
M_T = sp.exp(-lambda_ * n * (1 - sp.exp(s)))
# 1次モーメント(期待値)の計算
M_T_prime = sp.diff(M_T, s)
expectation = M_T_prime.subs(s, 0)
# 2次モーメントの計算
M_T_double_prime = sp.diff(M_T_prime, s)
second_moment = M_T_double_prime.subs(s, 0)
# 分散の計算
variance = second_moment - expectation**2
# 結果を表示
display(expectation, variance)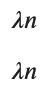
Po(nλ)の期待値と分散に一致します。