2022 Q5(1)
正規分布の差の分布を求める問題をやりました。

コード
シミュレーションによる計算
# 2022 Q4(5) 2024.8.13
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
# パラメータの設定
mu_i = 5.0 # 平均値 mu_i
theta = 3.0 # シフトパラメータ θ
sigma = 1.0 # 標準偏差 σ
n = 1000 # サンプル数
# X_i と Y_i のサンプル生成
X_i = np.random.normal(mu_i, sigma, n)
Y_i = np.random.normal(mu_i + theta, sigma, n)
# D_i の計算
D_i = Y_i - X_i
# シミュレーション結果の平均と分散を計算
mean_simulation = np.mean(D_i)
variance_simulation = np.var(D_i)
# 理論上の平均と分散
mean_theoretical = theta
variance_theoretical = 2 * sigma**2
# 結果の表示
print(f"シミュレーション結果: 平均 = {mean_simulation}, 分散 = {variance_simulation}")
print(f"理論値: 平均 = {mean_theoretical}, 分散 = {variance_theoretical}")
# サンプルのヒストグラムを作成
plt.hist(D_i, bins=30, density=True, alpha=0.6, color='g', label='サンプルデータ')
# 理論上の分布を重ねる
x = np.linspace(min(D_i), max(D_i), 1000)
plt.plot(x, stats.norm.pdf(x, mean_theoretical, np.sqrt(variance_theoretical)), 'r', label='理論的な確率密度関数')
plt.title("差 $D_i = Y_i - X_i$ の分布")
plt.xlabel("$D_i$")
plt.ylabel("密度")
plt.legend()
plt.show()シミュレーション結果: 平均 = 2.975536685240219, 分散 = 2.005575154363111
理論値: 平均 = 3.0, 分散 = 2.0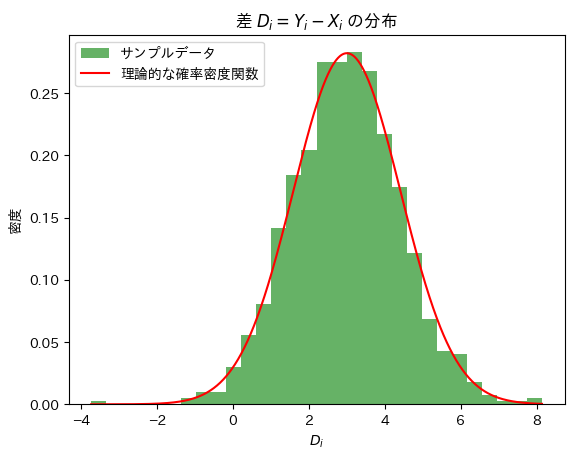
2022 Q4(5)
パラメータの推定量の期待値と分散を求めました。

コード
数式を使った計算
# 2022 Q4(5) 2024.8.12
import sympy as sp
# シンボリック変数の定義
gamma = sp.Symbol('gamma', positive=True)
x = sp.Symbol('x', positive=True)
# 確率密度関数 f_X(x) の定義
f_X = (1/gamma) * x**(-(1/gamma + 1))
# E[log X] の計算
E_log_X = sp.integrate(sp.log(x) * f_X, (x, 1, sp.oo))
# E[(log X)^2] の計算
E_log_X2 = sp.integrate((sp.log(x))**2 * f_X, (x, 1, sp.oo))
# V[log X] の計算
V_log_X = E_log_X2 - E_log_X**2
# E[hat_gamma] と V[hat_gamma] の計算
n = sp.Symbol('n', positive=True, integer=True)
E_hat_gamma = E_log_X
V_hat_gamma = V_log_X / n
# 結果の表示
display(E_hat_gamma, V_hat_gamma)
# LaTeXで表示できなときは、こちら
#sp.pprint(E_hat_gamma, use_unicode=True)
#sp.pprint(V_hat_gamma, use_unicode=True)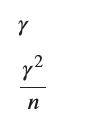
シミュレーションによる計算
# 2022 Q4(5) 2024.8.12
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
# パラメータ設定
gamma_true = 1.0 # 真のγの値
n = 100 # サンプルサイズ
num_simulations = 10000 # シミュレーションの回数
# 最尤推定量 \hat{gamma} を格納するリスト
gamma_hats = []
# シミュレーションの実行
for _ in range(num_simulations):
# 累積分布関数 F(x) に従う乱数を生成
X = np.random.uniform(size=n)**(-gamma_true)
# \hat{gamma} の計算
gamma_hat = np.mean(np.log(X))
gamma_hats.append(gamma_hat)
# シミュレーション結果の期待値と分散
E_hat_gamma_sim = np.mean(gamma_hats)
V_hat_gamma_sim = np.var(gamma_hats)
# 理論値を計算
# 理論値の計算は、sympyを使って導出した結果を使用
E_hat_gamma_theoretical = 1 / gamma_true # gammaが1の場合は1が期待値になります
V_hat_gamma_theoretical = (np.pi ** 2) / (6 * n * gamma_true**2)
# 結果の表示
print(f"シミュレーションによる期待値 E[hat_gamma]: {E_hat_gamma_sim}")
print(f"シミュレーションによる分散 V[hat_gamma]: {V_hat_gamma_sim}")
print(f"理論値による期待値 E[hat_gamma]: {E_hat_gamma_theoretical}")
print(f"理論値による分散 V[hat_gamma]: {V_hat_gamma_theoretical}")
# ヒストグラムのプロット
plt.hist(gamma_hats, bins=50, density=True, alpha=0.6, color='g')
plt.axvline(E_hat_gamma_sim, color='r', linestyle='dashed', linewidth=2, label='シミュレーション平均')
plt.axvline(E_hat_gamma_theoretical, color='b', linestyle='dashed', linewidth=2, label='理論値')
plt.xlabel(r'$\hat{\gamma}$の値')
plt.ylabel('密度')
plt.title(r'$\hat{\gamma}$の分布')
plt.legend()
plt.show()
シミュレーションによる期待値 E[hat_gamma]: 0.9995206635186084
シミュレーションによる分散 V[hat_gamma]: 0.010015979040467726
理論値による期待値 E[hat_gamma]: 1.0
理論値による分散 V[hat_gamma]: 0.016449340668482262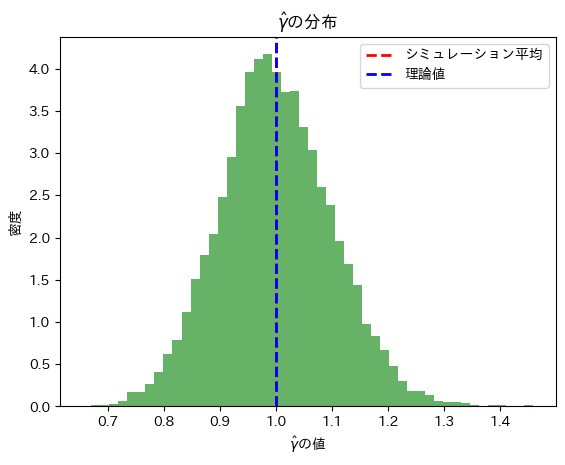
アルゴリズム
サンプル生成:
X = np.random.uniform(size=n)**(-gamma_true)で累積分布関数 F(x) に従う乱数を生成します。逆関数法を使用しています。
最尤推定量の計算:
gamma_hat = np.mean(np.log(X))で各サンプルから計算された をリスト
をリスト gamma_hatsに格納します。
シミュレーション結果の期待値と分散:
- シミュレーション結果の期待値と分散を
E_hat_gamma_simとV_hat_gamma_simに計算し、理論値と比較します。
理論値との比較:
- 理論値を計算して表示し、シミュレーション結果と比較します。
2022 Q4(4)
対数で変数変換した場合の分布を求めました。
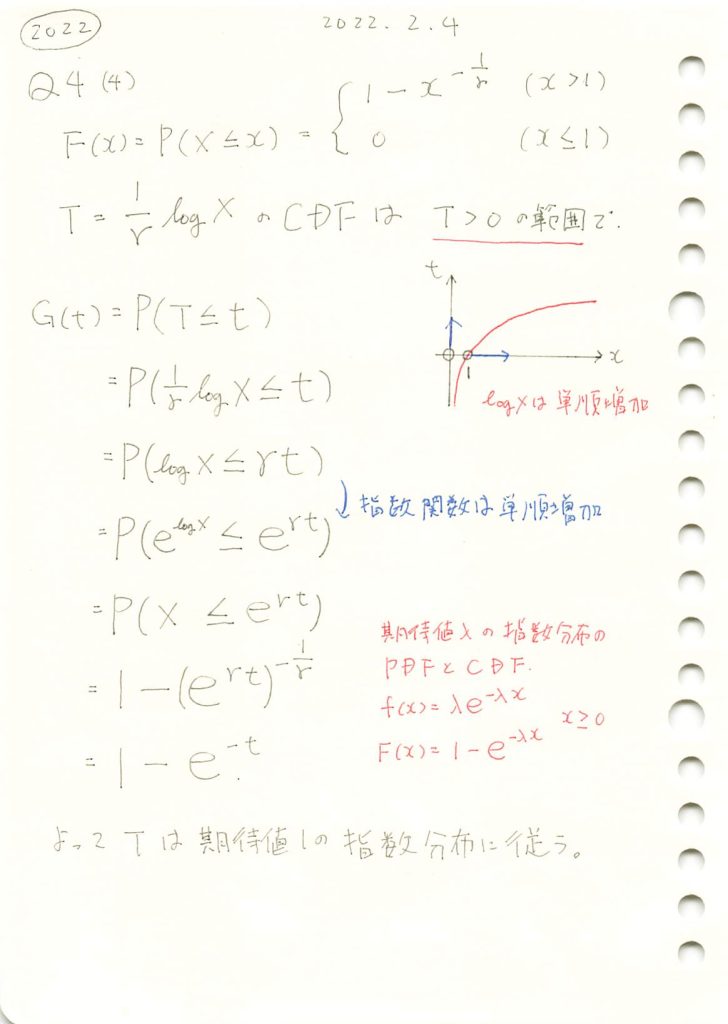
コード
数式を使った計算
# 2022 Q4(4) 2024.8.11
import sympy as sp
# シンボリック変数の定義
t, gamma = sp.symbols('t gamma', positive=True)
x = sp.symbols('x', real=True, positive=True)
# 累積分布関数 F_X(x) の定義
F_X = sp.Piecewise((0, x <= 1), (1 - x**(-1/gamma), x > 1))
# F_T(t) の計算
F_T = F_X.subs(x, sp.exp(gamma * t))
# f_T(t) の計算(F_T(t) を t で微分)
f_T = sp.diff(F_T, t)
# 結果の表示
display(F_T, f_T)
# LaTeXで表示できなときは、こちら
#sp.pprint(F_T, use_unicode=True)
#sp.pprint(f_T, use_unicode=True)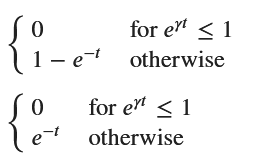
シミュレーションによる計算
# 2022 Q4(4) 2024.8.11
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
# パラメータ設定
gamma = 1.0 # γの値(例えば1)
num_samples = 10000 # サンプルサイズ
# 累積分布関数 F(x) に従う乱数を生成
X = (np.random.uniform(size=num_samples))**(-gamma)
# T = (1/γ) * log(X) の計算
T = (1/gamma) * np.log(X)
# ヒストグラムをプロット
plt.hist(T, bins=50, density=True, alpha=0.6, color='g', label="シミュレーションによる T")
# 理論的な指数分布の密度関数をプロット
x = np.linspace(0, 8, 100)
pdf = stats.expon.pdf(x) # 指数分布(λ=1)の密度関数
plt.plot(x, pdf, 'r-', lw=2, label='指数分布の理論値')
# グラフの設定(日本語でキャプションとラベルを設定)
plt.xlabel('Tの値')
plt.ylabel('確率密度')
plt.title(r'$T = \frac{1}{\gamma} \log X$ のヒストグラムと指数分布の比較')
plt.legend()
plt.show()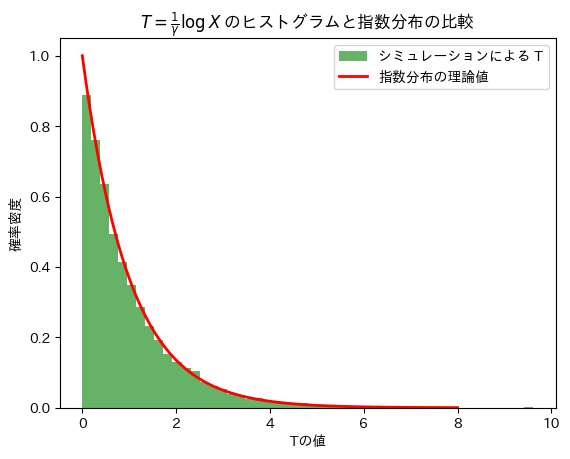
2022 Q4(3)
対数尤度関数を用いてパラメータの最尤推定量を求めました。

コード
数式を使った計算
# 2022 Q4(3) 2024.8.10
import sympy as sp
# シンボリック変数の定義
gamma = sp.Symbol('gamma', positive=True)
n = 10 # 具体的なサンプル数を設定
X = sp.symbols('X1:%d' % (n+1), positive=True) # X1, X2, ..., Xn を定義
# 尤度関数の定義
L_gamma = sp.prod((1/gamma) * X[i]**(-(1/gamma + 1)) for i in range(n))
# 対数尤度関数の定義
log_L_gamma = sp.log(L_gamma)
# 對数尤度関数を γ で微分
diff_log_L_gamma = sp.diff(log_L_gamma, gamma)
# 微分した結果を 0 に等しいとおいて解く
gamma_hat_eq = sp.Eq(diff_log_L_gamma, 0)
gamma_hat = sp.solve(gamma_hat_eq, gamma)
# 結果の表示
sp.pprint(gamma_hat[0], use_unicode=True)
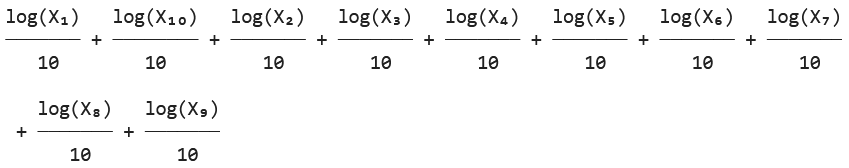
シミュレーションによる計算
# 2022 Q4(3) 2024.8.10
import numpy as np
# 観測データ(例としてランダムに生成)
n = 1000 # データ点の数
gamma_true = 0.5 # 実際の γ (例として)
# CDFの逆関数
X = (np.random.uniform(size=n))**(-gamma_true)
# 最尤推定量 gamma_hat} の計算
log_X = np.log(X)
gamma_hat = np.mean(log_X)
print(f"観測(ランダム)データからの最尤推定量 gamma_hat: {gamma_hat}")観測(ランダム)データからの最尤推定量 gamma_hat: 0.49849744820263612022 Q4(2)
とある分布の期待値と分散を求めました。
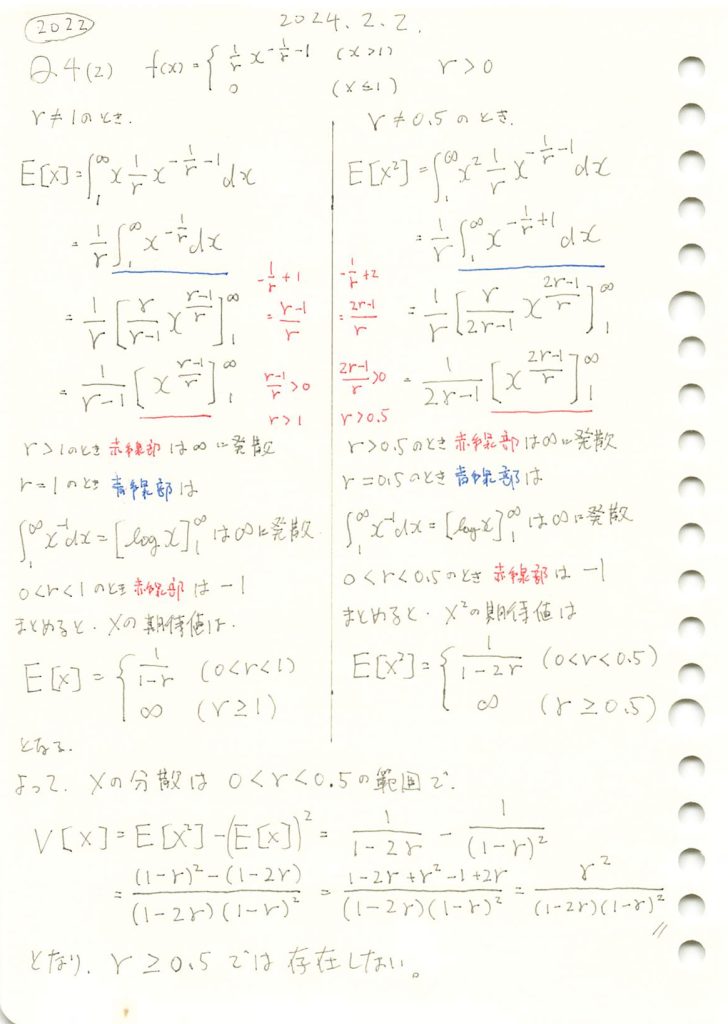
コード
数式を使った計算
# 2022 Q4(2) 2024.8.9
from sympy import init_printing
import sympy as sp
# これでTexの表示ができる
init_printing()
# シンボリック変数の定義
x, gamma = sp.symbols('x gamma', positive=True)
# 確率密度関数 f(x) の定義
f_x = (1/gamma) * x**(-(1/gamma + 1))
# 期待値 E[X] の計算
E_X = sp.integrate(x * f_x, (x, 1, sp.oo))
E_X_simplified = sp.simplify(E_X)
# E[X^2] の計算
E_X2 = sp.integrate(x**2 * f_x, (x, 1, sp.oo))
E_X2_simplified = sp.simplify(E_X2)
# 分散 V[X] の計算
V_X = E_X2_simplified - E_X_simplified**2
# 分散をさらに簡略化
V_X_simplified = sp.simplify(V_X)
V_X_factored = sp.factor(V_X_simplified)
# 結果を表示
E_X_simplified,E_X2_simplified,V_X_simplified,V_X_factored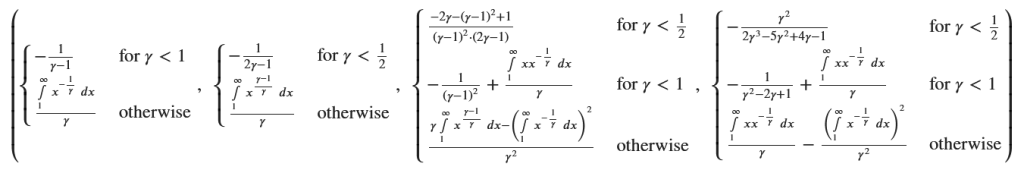
シミュレーションによる計算
# 2022 Q4(2) 2024.8.9
import numpy as np
import scipy.integrate as integrate
# パラメータの設定
gamma = 0.3 # 例として γ = 0.5 を設定
num_samples = 1000000 # サンプル数
# 確率密度関数 f(x) の定義
def pdf(x, gamma):
return (1/gamma) * x**(-(1/gamma + 1))
# 理論的な期待値 E[X] の計算
def theoretical_expected_value(gamma):
if gamma <= 0 or gamma >= 1:
return np.inf
else:
result, _ = integrate.quad(lambda x: x * pdf(x, gamma), 1, np.inf)
return result
# 理論的な分散 V[X] の計算
def theoretical_variance(gamma):
if gamma <= 0 or gamma >= 0.5:
return np.inf
else:
E_X = theoretical_expected_value(gamma)
E_X2, _ = integrate.quad(lambda x: x**2 * pdf(x, gamma), 1, np.inf)
return E_X2 - E_X**2
# シミュレーションによる確率変数 X のサンプリング
samples = (np.random.uniform(size=num_samples))**(-gamma)
# シミュレーションによる期待値 E[X] の推定
E_X_simulation = np.mean(samples)
# シミュレーションによる分散 V[X] の推定
V_X_simulation = np.var(samples)
# 理論値の計算
E_X_theoretical = theoretical_expected_value(gamma)
V_X_theoretical = theoretical_variance(gamma)
# 結果の表示
print(f"シミュレーションによる期待値 E[X]: {E_X_simulation}")
print(f"理論的な期待値 E[X]: {E_X_theoretical}")
print(f"シミュレーションによる分散 V[X]: {V_X_simulation}")
print(f"理論的な分散 V[X]: {V_X_theoretical}")
シミュレーションによる期待値 E[X]: 1.4284089260116615
理論的な期待値 E[X]: 1.4285714285714284
シミュレーションによる分散 V[X]: 0.4593987557711114
理論的な分散 V[X]: 0.459183673469389042022 Q4(1)
ある累積分布関数から確率密度関数を導いてグラフを描画しました。
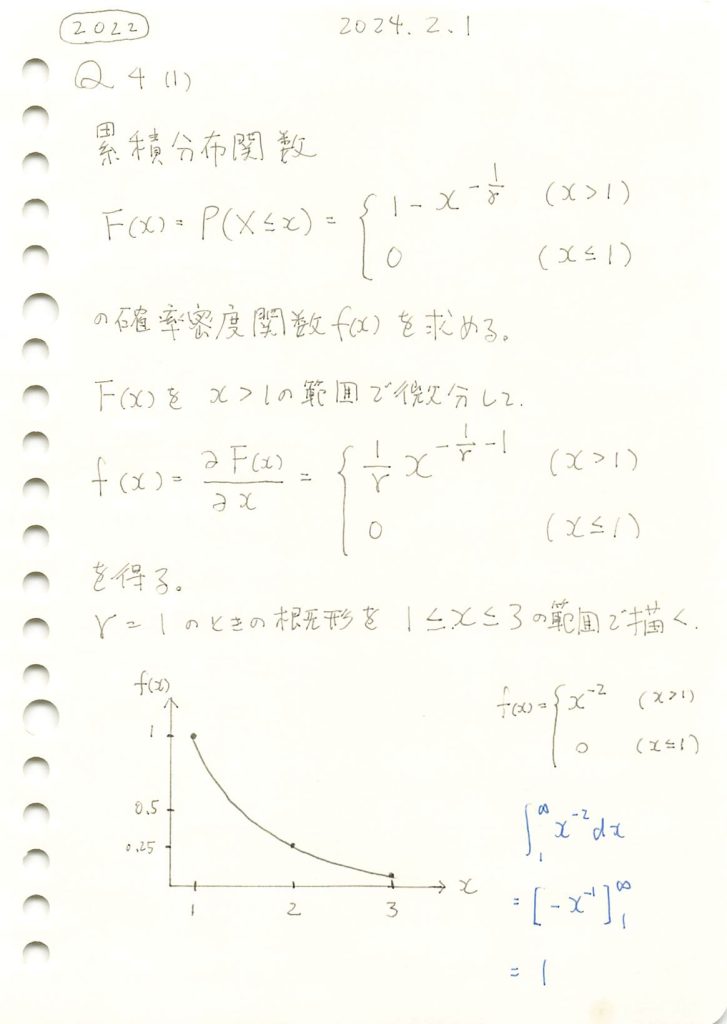
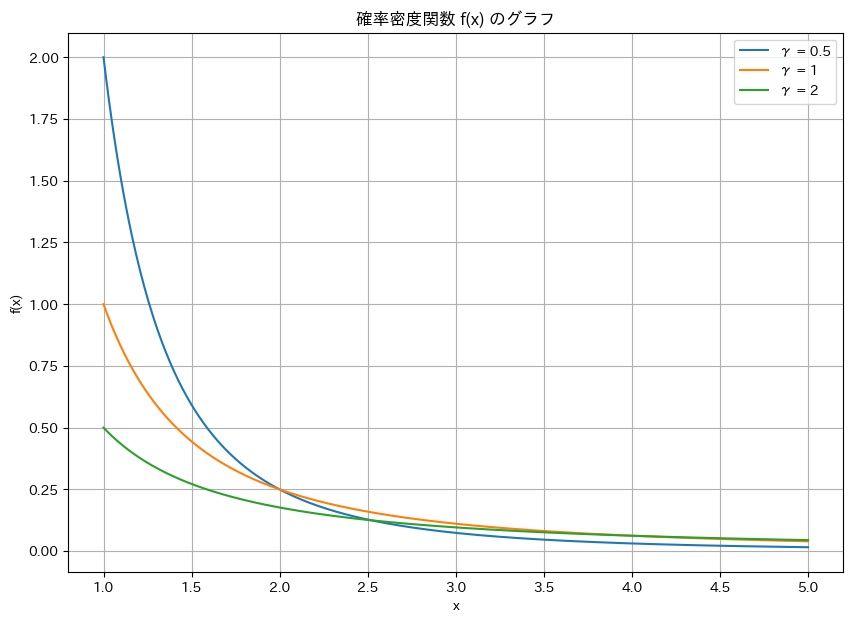
コード
確率密度関数 f(x) の描画
# 2022 Q4(1) 2024.8.8
import numpy as np
import matplotlib.pyplot as plt
def probability_density_function(x, gamma):
if x <= 1:
return 0
else:
return (1/gamma) * x**(-1/gamma-1)
# 配列のγ値に対するベクトル化された関数
def f_array(x, gammas):
y_values = np.zeros((len(gammas), len(x)))
for i, gamma in enumerate(gammas):
y_values[i] = [probability_density_function(xi, gamma) for xi in x]
return y_values
x_values = np.linspace(1.00001, 5, 500)
gammas = [0.5, 1, 2]
y_values_pdf_array = f_array(x_values, gammas)
plt.figure(figsize=(10, 7))
for i, gamma in enumerate(gammas):
plt.plot(x_values, y_values_pdf_array[i], label=f"γ = {gamma}")
plt.title("確率密度関数 f(x) のグラフ")
plt.xlabel("x")
plt.ylabel("f(x)")
plt.grid(True)
plt.legend()
plt.show()
累積分布関数 F(x) の描画
# 2022 Q4(1) 2024.8.8
import numpy as np
import matplotlib.pyplot as plt
# 累積分布関数を定義
def F(x, gamma):
if x <= 1:
return 0
else:
return 1 - x**(-1/gamma)
# 配列のγ値に対するベクトル化された関数
def F_array(x, gammas):
y_values = np.zeros((len(gammas), len(x)))
for i, gamma in enumerate(gammas):
y_values[i] = [F(xi, gamma) for xi in x]
return y_values
x_values = np.linspace(1, 5, 500)
gammas = [0.5, 1, 2]
y_values_array = F_array(x_values, gammas)
plt.figure(figsize=(10, 7))
for i, gamma in enumerate(gammas):
plt.plot(x_values, y_values_array[i], label=f"γ = {gamma}")
plt.title("累積分布関数 F(x) のグラフ")
plt.xlabel("x")
plt.ylabel("F(x)")
plt.grid(True)
plt.legend()
plt.show()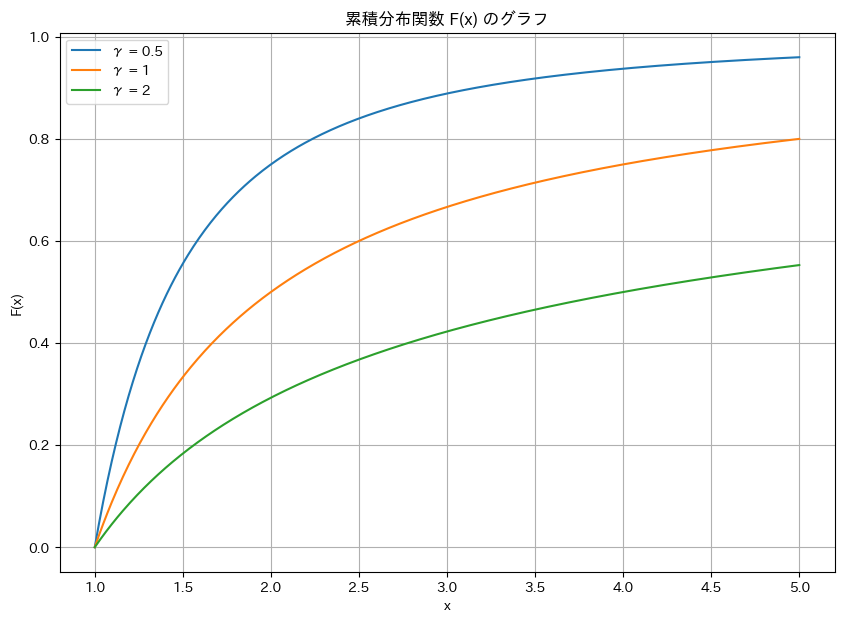
2022 Q3(5)
モーメント法によりガンマポアソン分布のパラメータの推定量を求めました。

コード
数式を使った計算
# 2022 Q3(5) 2024.8.6
from sympy import init_printing
from sympy import symbols, Eq, solve
# これでTexの表示ができる
init_printing()
# 変数の定義
r, p, X_bar, S_squared = symbols('r p X_bar S_squared')
alpha, beta = symbols('alpha beta')
# モーメント法の方程式を定義
# 期待値 E[X] にサンプル平均を一致させる
eq1_correct = Eq(X_bar, alpha / beta)
# 分散 V[X] にサンプル分散を一致させる
eq2_correct = Eq(S_squared, alpha / beta**2 + alpha / beta)
# 方程式を解いて α と β を求める
solutions_correct = solve((eq1_correct, eq2_correct), (alpha, beta))
solutions_correct
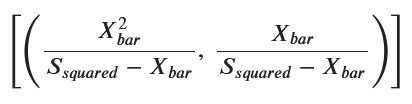
シミュレーションによる計算
# 2022 Q3(5) 2024.8.6
import numpy as np
from scipy.stats import nbinom
# 1. パラメータの設定
alpha_true = 3.0
beta_true = 2.0
# 2. 負の二項分布のパラメータ計算
r = alpha_true
p = beta_true / (beta_true + 1)
# 3. 負の二項分布から乱数を生成
sample_size = 10000
nbinom_samples = nbinom.rvs(r, p, size=sample_size)
# 4. サンプル統計量の計算
X_bar = np.mean(nbinom_samples)
S_squared = np.var(nbinom_samples, ddof=1)
# 5. モーメント法によるパラメータ推定
alpha_estimated = X_bar**2 / (S_squared - X_bar)
beta_estimated = X_bar / (S_squared - X_bar)
# 6. 推定結果の表示
print(f"推定された α: {alpha_estimated}")
print(f"推定された β: {beta_estimated}")
print(f"理論値 α: {alpha_true}")
print(f"理論値 β: {beta_true}")推定された α: 2.93536458612626
推定された β: 1.95157541794180
理論値 α: 3.0
理論値 β: 2.0アルゴリズム
シミュレーションによる計算
パラメータの設定:
- 真のパラメータ
 と
と  を設定する。
を設定する。
負の二項分布のパラメータ計算:
- パラメータ

- パラメータ

負の二項分布から乱数を生成:
- サンプルサイズ
 を設定し、負の二項分布から乱数を生成する。
を設定し、負の二項分布から乱数を生成する。
サンプル統計量の計算:
- サンプル平均
 と分散
と分散  を計算する。
を計算する。
モーメント法によるパラメータ推定:
- 推定された を
 で計算する。
で計算する。 - 推定された を
 で計算する。
で計算する。
推定結果の表示:
- 推定された と を表示する。
- 真の と を表示する。
2022 Q3(4)
条件付き期待値の公式と条件付き分散の公式を使ってガンマポアソン分布の期待値と分散を求めました。

コード
数式を使った計算
# 2022 Q3(4) 2024.8.7
import sympy as sp
# 定義
k, lambda_var = sp.symbols('k lambda')
alpha, beta = sp.symbols('alpha beta', positive=True)
# ポアソン分布の確率質量関数
poisson_pmf = (lambda_var**k * sp.exp(-lambda_var)) / sp.factorial(k)
# ガンマ分布の確率密度関数
gamma_pdf = (beta**alpha / sp.gamma(alpha)) * lambda_var**(alpha - 1) * sp.exp(-beta * lambda_var)
# 周辺分布の計算
marginal_distribution = sp.integrate(poisson_pmf * gamma_pdf, (lambda_var, 0, sp.oo)).simplify()
# 期待値 E[X] の計算
expected_value = sp.summation(k * marginal_distribution, (k, 0, sp.oo)).simplify()
# 分散 V[X] の計算
expected_value_of_square = sp.summation(k**2 * marginal_distribution, (k, 0, sp.oo)).simplify()
variance = (expected_value_of_square - expected_value**2).simplify()
# 結果を表示
results = {
"期待値 E[X]": expected_value,
"分散 V[X]": variance
}
results{'期待値 E[X]': alpha/beta, '分散 V[X]': alpha*(beta + 1)/beta**2}シミュレーションによる計算
import numpy as np
# パラメータの設定
alpha = 3.0
beta = 2.0
sample_size = 10000
# ガンマ分布から λ を生成
lambda_samples = np.random.gamma(alpha, 1/beta, sample_size)
# 生成された λ を使ってポアソン分布から X を生成
poisson_samples = [np.random.poisson(lam) for lam in lambda_samples]
# サンプルの期待値と分散を計算
sample_mean = np.mean(poisson_samples)
sample_variance = np.var(poisson_samples)
# 理論値を計算
theoretical_mean = alpha / beta
theoretical_variance = alpha * (beta + 1) / beta**2
# 結果を表示
results_with_caption = {
"シミュレーションによる期待値": sample_mean,
"理論値による期待値": theoretical_mean,
"シミュレーションによる分散": sample_variance,
"理論値による分散": theoretical_variance
}
results_with_caption{'シミュレーションによる期待値': 1.5027,
'理論値による期待値': 1.5,
'シミュレーションによる分散': 2.31159271,
'理論値による分散': 2.25}2022 Q3(3)
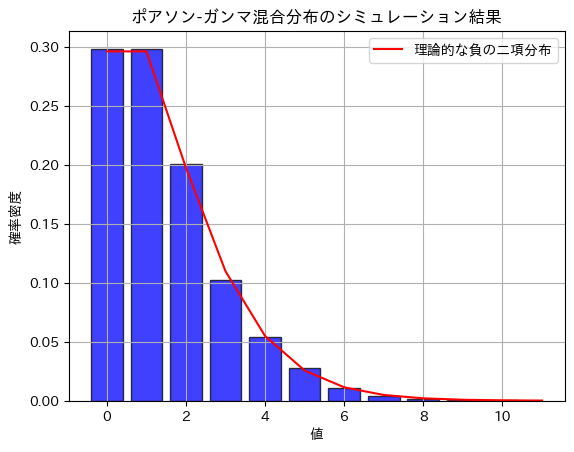
ポアソン分布のパラメータλがガンマ分布に従うと負の二項分布になる。

コード
数式を使った計算
# 2022 Q3(3) 2024.8.5
import sympy as sp
# 定義
k = sp.symbols('k', integer=True)
alpha, beta = sp.symbols('alpha beta', positive=True)
lambda_var = sp.symbols('lambda', positive=True)
# ポアソン分布の確率質量関数
poisson_pmf = (lambda_var**k * sp.exp(-lambda_var)) / sp.factorial(k)
# ガンマ分布の確率密度関数
gamma_pdf = (beta**alpha / sp.gamma(alpha)) * lambda_var**(alpha - 1) * sp.exp(-beta * lambda_var)
# 周辺分布の計算
marginal_distribution = sp.integrate(poisson_pmf * gamma_pdf, (lambda_var, 0, sp.oo)).simplify()
marginal_distribution
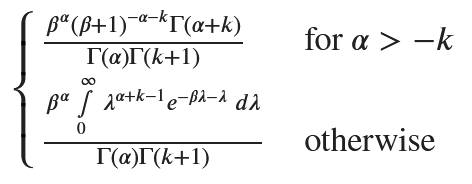
次式と同じなので、負の二項分布となる。
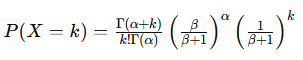
シミュレーションによる計算
# 2022 Q3(3) 2024.8.5
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma, nbinom
# パラメータの設定
alpha = 3.0
beta = 2.0
sample_size = 10000
# ガンマ分布から λ を生成
lambda_samples = np.random.gamma(alpha, 1/beta, sample_size)
# 生成された λ を使ってポアソン分布から X を生成
poisson_samples = [np.random.poisson(lam) for lam in lambda_samples]
# 負の二項分布のパラメータを設定
r = alpha
p = beta / (beta + 1)
# 負の二項分布から理論的な確率質量関数を計算
x = np.arange(0, max(poisson_samples) + 1)
nbinom_pmf = nbinom.pmf(x, r, p)
# ヒストグラムの描画
plt.hist(poisson_samples, bins=np.arange(0, max(poisson_samples) + 1) - 0.5, density=True, alpha=0.75, color='blue', edgecolor='black', rwidth=0.8)
# 理論的な負の二項分布の確率質量関数をプロット
plt.plot(x, nbinom_pmf, 'r', linestyle='-', label='理論的な負の二項分布')
# グラフのタイトルとラベル
plt.title('ポアソン-ガンマ混合分布のシミュレーション結果')
plt.xlabel('値')
plt.ylabel('確率密度')
plt.legend()
# グラフの表示
plt.grid(True)
plt.show()
2022 Q3(2)
ガンマ分布の期待値と分散を求めました。
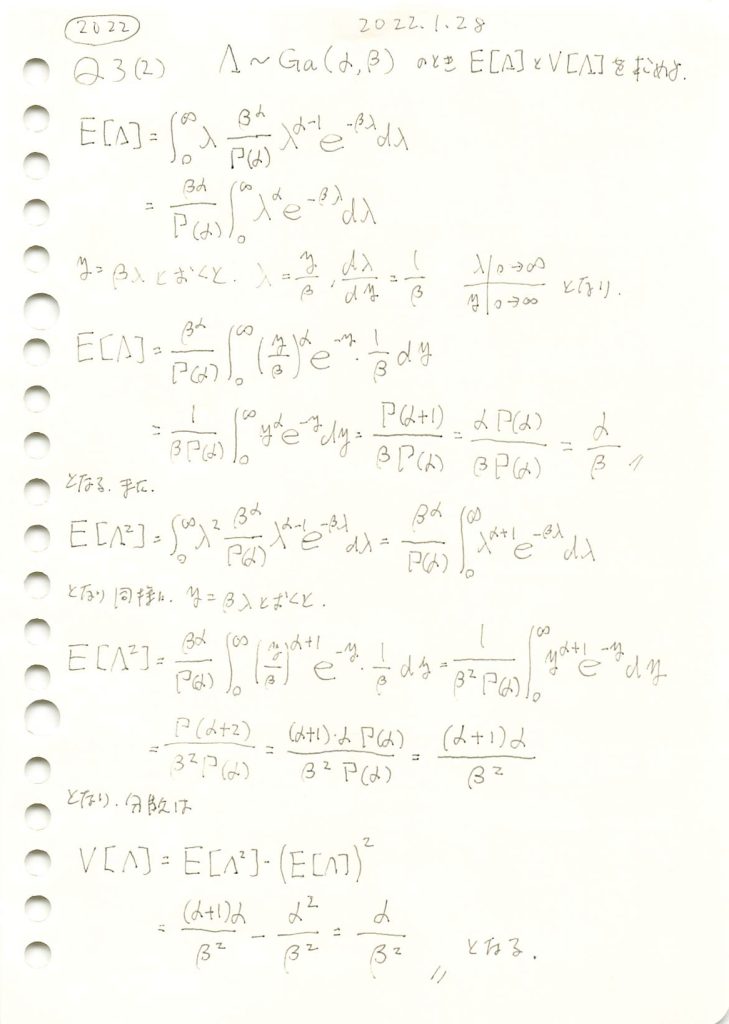
コード
数式を使った計算
## 2022 Q3(2) 2024.8.4
import sympy as sp
# 定義
lambda_var = sp.symbols('lambda')
alpha, beta = sp.symbols('alpha beta', positive=True)
# ガンマ分布の確率密度関数
gamma_pdf = (beta**alpha / sp.gamma(alpha)) * lambda_var**(alpha-1) * sp.exp(-beta * lambda_var)
# 期待値 E[Λ] の計算
expected_value = sp.integrate(lambda_var * gamma_pdf, (lambda_var, 0, sp.oo)).simplify()
# E[Λ^2] の計算
expected_value_Lambda2 = sp.integrate(lambda_var**2 * gamma_pdf, (lambda_var, 0, sp.oo)).simplify()
# 分散 V[Λ] の計算
variance = (expected_value_Lambda2 - expected_value**2).simplify()
# 結果を辞書形式で表示
{
"期待値 E[Λ]": expected_value,
"分散 V[Λ]": variance
}{'期待値 E[Λ]': alpha/beta, '分散 V[Λ]': alpha/beta**2}シミュレーションによる計算
## 2022 Q3(2) 2024.8.4
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
# パラメータ α と β の設定
alpha = 3.0
beta = 2.0
# サンプルサイズ
sample_size = 10000
# ガンマ分布に従う乱数を生成
samples = np.random.gamma(alpha, 1/beta, sample_size)
# 期待値と分散の計算
expected_value = np.mean(samples)
variance = np.var(samples)
# 結果の表示
print(f"期待値のシミュレーション結果: {expected_value}")
print(f"分散のシミュレーション結果: {variance}")
# ヒストグラムの描画
plt.hist(samples, bins=50, density=True, alpha=0.75, color='blue', edgecolor='black')
# 理論的なガンマ分布の確率密度関数をプロット
x = np.linspace(0, max(samples), 100)
gamma_pdf = gamma.pdf(x, alpha, scale=1/beta)
plt.plot(x, gamma_pdf, 'r', linestyle='-', label='理論的なガンマ分布')
# グラフのタイトルとラベル
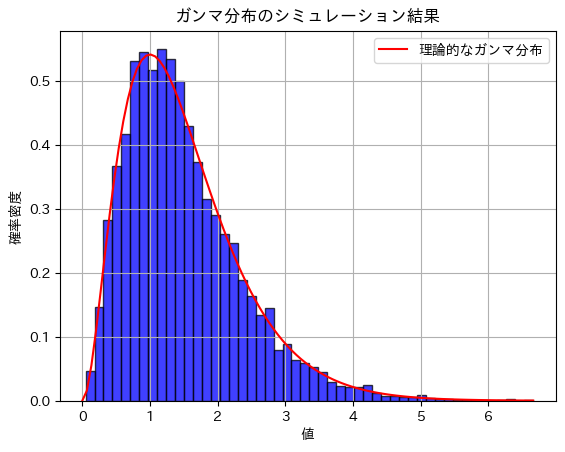
plt.title('ガンマ分布のシミュレーション結果')
plt.xlabel('値')
plt.ylabel('確率密度')
plt.legend()
# グラフの表示
plt.grid(True)
plt.show()期待値のシミュレーション結果: 1.4947527551017439
分散のシミュレーション結果: 0.7452822182213243# パラメータ α と β の設定
alpha = 3.0
beta = 2.0
# 理論値の計算
theoretical_expected_value = alpha / beta
theoretical_variance = alpha / beta**2
# 結果の表示
print(f"理論値 - 期待値: {theoretical_expected_value}")
print(f"理論値 - 分散: {theoretical_variance}")理論値 - 期待値: 1.5
理論値 - 分散: 0.75