2021 Q2(3)
離散型確率分布の正規化定数を計算しました。

コード
数式を使った計算
# 2021 Q2(3) 2024.8.23
from sympy import symbols, summation, Eq, solve
# 記号の定義
n = symbols('n', integer=True)
C = symbols('C', real=True)
# 和を計算
sum_expr = summation(C * (n + 1), (n, 0, 100))
# 正規化条件を設定
normalization_condition = Eq(sum_expr, 1)
# C を解く
C_value = solve(normalization_condition, C)[0]
C_value
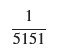
P(N_A = n)のプロット
# 2021 Q2(3) 2024.8.23
import matplotlib.pyplot as plt
import numpy as np
# 正規化定数 C
C_value = 1 / 5151
# n の範囲
n_values = np.arange(0, 101)
# 確率質量関数 P(N_A = n)
pmf_values = C_value * (n_values + 1)
# グラフの描画
plt.figure(figsize=(10, 6))
plt.plot(n_values, pmf_values, 'bo-', label=r'$P(N_A = n) = \frac{1}{5151} \cdot (n + 1)$', markersize=5)
plt.xlabel(r'$n$')
plt.ylabel(r'$P(N_A = n)$')
plt.title(r'確率質量関数 $P(N_A = n)$ のグラフ')
plt.grid(True)
plt.legend()
plt.show()
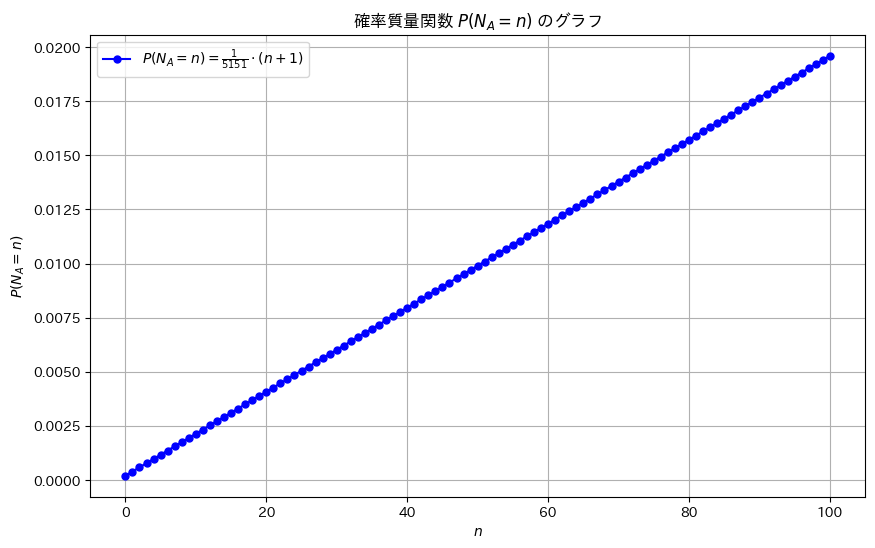
2021 Q2(2)
超幾何分布の当たりの数の推定値を尤度比を使って求めました。

コード
シミュレーションによる計算
# 2021 Q2(2) 2024.8.22
import numpy as np
from scipy.special import comb
# 尤度関数 L(N_A) を定義
def L(NA):
return comb(NA, 4) * comb(100 - NA, 11) / comb(100, 15)
# L(N_A + 1) / L(N_A) を計算し、条件を満たす最小の N_A を探索
# max(0, N_A - 85) ≤ 4 ≤ min(15, N_A) の式に基づき、取り出した豆Aが4粒の場合の N_A の範囲を設定 (4 ≤ N_A ≤ 89)
NA_values = np.arange(4, 90)
ratios = [(L(NA + 1) / L(NA)) for NA in NA_values]
NA_optimal = NA_values[np.where(np.array(ratios) < 1)[0][0]]
print(f"L(N_A + 1) / L(N_A) < 1 となる最小の N_A は {NA_optimal} です。")
L(N_A + 1) / L(N_A) < 1 となる最小の N_A は 26 です。プロット
# 2021 Q2(2) 2024.8.22
import numpy as np
import matplotlib.pyplot as plt
from scipy.special import comb
# 尤度関数 L(N_A) を定義
def L(NA):
return comb(NA, 4) * comb(100 - NA, 11) / comb(100, 15)
# N_A の範囲を設定
NA_values = np.arange(4, 90)
ratios = [(L(NA + 1) / L(NA)) for NA in NA_values]
# グラフの描画
plt.figure(figsize=(10, 6))
plt.plot(NA_values, ratios, 'bo-', label=r'$\frac{L(N_A + 1)}{L(N_A)}$', markersize=8)
plt.axhline(y=1, color='red', linestyle='--', label=r'$1$')
plt.xlabel(r'$N_A$')
plt.ylabel(r'$\frac{L(N_A + 1)}{L(N_A)}$')
plt.title(r'$N_A$ の尤度比 $\frac{L(N_A + 1)}{L(N_A)}$')
plt.legend()
plt.grid(True)
plt.show()
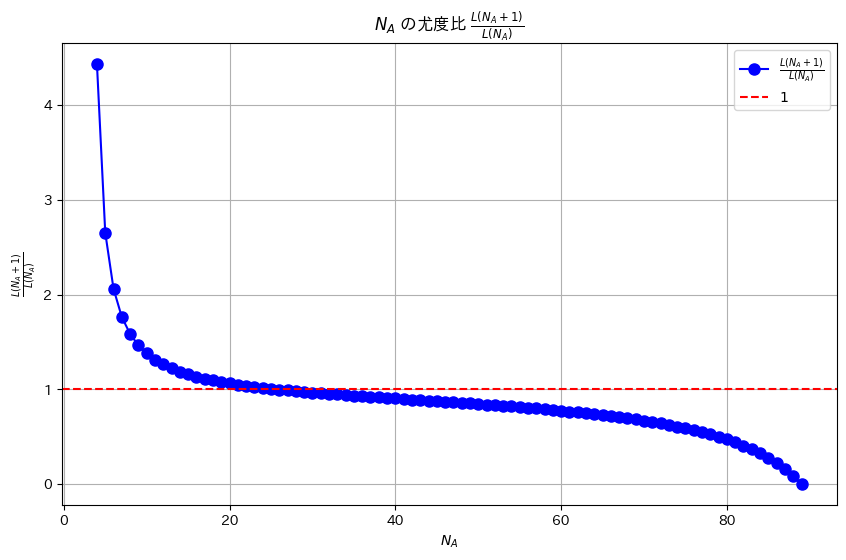
プロット(NA=26付近をズーム)
# 2021 Q2(2) 2024.8.22
import numpy as np
import matplotlib.pyplot as plt
from scipy.special import comb
# 尤度関数 L(N_A) を定義
def L(NA):
return comb(NA, 4) * comb(100 - NA, 11) / comb(100, 15)
# N_A の範囲を設定
NA_values = np.arange(4, 90)
ratios = [(L(NA + 1) / L(NA)) for NA in NA_values]
# 26付近のズームしたグラフを描画
plt.figure(figsize=(10, 6))
plt.plot(NA_values, ratios, 'bo-', label=r'$\frac{L(N_A + 1)}{L(N_A)}$', markersize=8)
plt.axhline(y=1, color='red', linestyle='--', label=r'$1$')
plt.xlabel(r'$N_A$')
plt.ylabel(r'$\frac{L(N_A + 1)}{L(N_A)}$')
plt.title(r'$N_A$ の尤度比 $\frac{L(N_A + 1)}{L(N_A)}$ (25 < $N_A$ < 30)')
plt.xlim(25, 30) # N_A = 26 付近をズーム
plt.ylim(0.95, 1.05) # y軸もズームして見やすく
plt.legend()
plt.grid(True)
plt.show()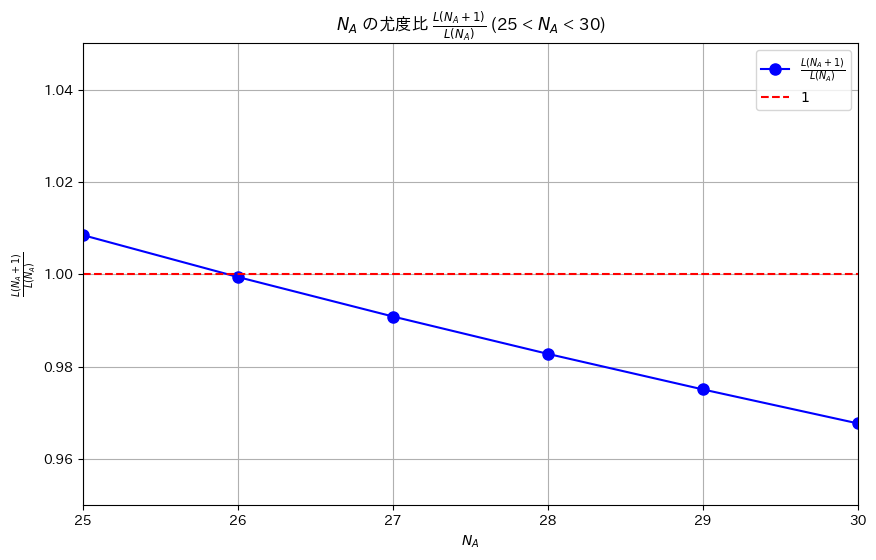
2021 Q2(1)
超幾何分布の問題をやりました。

コード
シミュレーションによる計算
# 2021 Q2(1) 2024.8.21
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import hypergeom
# パラメータの設定
M = 100 # 全体の豆の数
N_A = 30 # 豆Aの数
n = 15 # 抽出する豆の数
x_values = np.arange(0, n+1) # 可能な豆Aの数
# 理論的な超幾何分布のPMFを計算
rv = hypergeom(M, N_A, n)
pmf_theoretical = rv.pmf(x_values)
# 数値シミュレーションの設定
n_simulations = 10000 # シミュレーション回数
simulated_counts = []
# シミュレーションの実行
for _ in range(n_simulations):
# 袋の中の豆を表すリスト(1が豆A、0が豆B)
bag = np.array([1]*N_A + [0]*(M - N_A))
# 無作為に15個抽出
sample = np.random.choice(bag, size=n, replace=False)
# 抽出した中の豆Aの数をカウント
count_A = np.sum(sample)
simulated_counts.append(count_A)
# シミュレーションから得られたPMFを計算
pmf_simulated, bins = np.histogram(simulated_counts, bins=np.arange(-0.5, n+1.5, 1), density=True)
# グラフの描画
plt.figure(figsize=(10, 6))
# 理論的なPMFの描画
plt.plot(x_values, pmf_theoretical, 'bo-', label='理論的PMF', markersize=8)
# シミュレーション結果をヒストグラムとして描画
plt.hist(simulated_counts, bins=np.arange(-0.5, n+1.5, 1), density=True, alpha=0.5, color='red', label='シミュレーション結果')
# グラフの設定
plt.xlabel('豆Aの数')
plt.ylabel('確率')
plt.title('超幾何分布のPMF: 理論とシミュレーションの比較')
plt.legend()
plt.grid(True)
plt.show()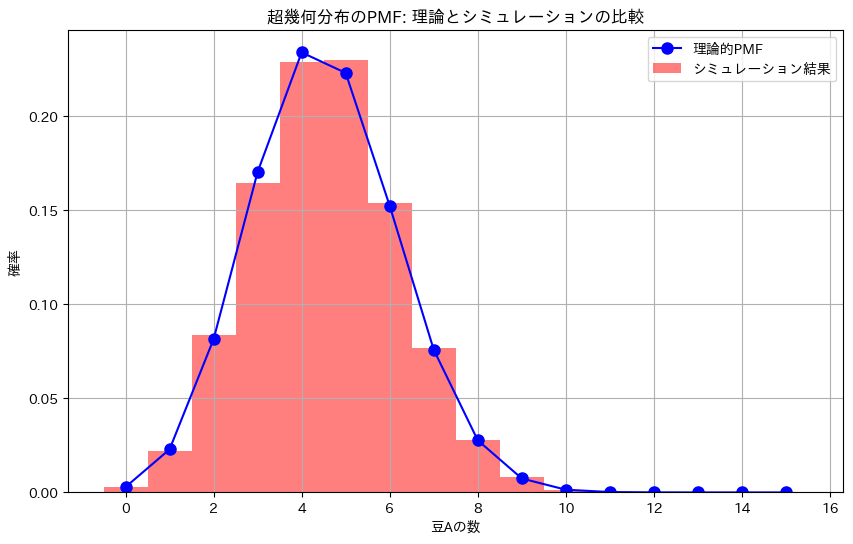
2021 Q1(4)
独立ではない2つの確率変数の積の期待値を求めました。

コード
数式を使った計算
# 2021 Q1(4) 2024.8.20
import sympy as sp
# シンボリック変数の定義
x, y = sp.symbols('x y')
# h(x) の導出
h_x = sp.integrate(sp.exp(-x), (x, 0, x))
# XY の期待値の計算
# h(x) = 1 - exp(-x) を使って E[X * h(X)] を計算する
integral_part1 = sp.integrate(x * h_x * sp.exp(-x), (x, 0, sp.oo))
E_XY_simplified = sp.simplify(integral_part1)
# 結果の表示
display(sp.Eq(sp.Symbol('h(x)'), h_x))
display(sp.Eq(sp.Symbol('E[XY]'), E_XY_simplified))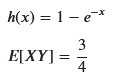
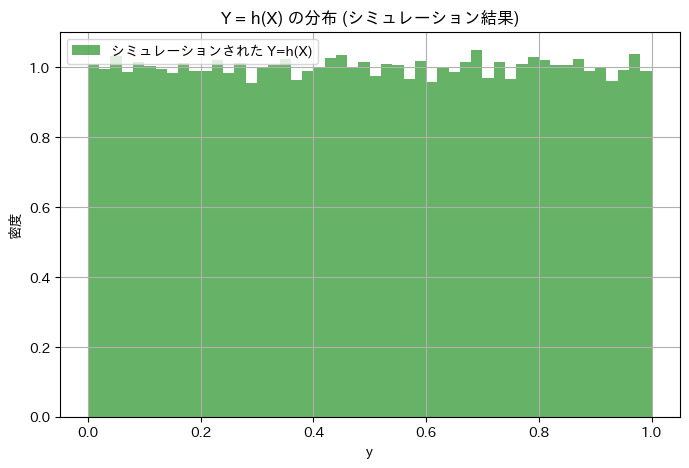
指数分布に従う乱数Xを生成し、Y=h(X)Yが一様分布に従うか確認
import numpy as np
import matplotlib.pyplot as plt
# シミュレーションの設定
num_samples = 100000 # サンプル数
# 指数分布に従う乱数 X を生成
X_samples = np.random.exponential(scale=1.0, size=num_samples)
# 関数 Y = h(X) = 1 - exp(-X) を適用して Y を計算
Y_samples = 1 - np.exp(-X_samples)
# ヒストグラムのプロット
plt.figure(figsize=(8, 5))
plt.hist(Y_samples, bins=50, density=True, alpha=0.6, color='g', label='シミュレーションされた Y=h(X)')
plt.xlabel('y')
plt.ylabel('密度')
plt.title('Y = h(X) の分布 (シミュレーション結果)')
plt.legend()
plt.grid(True)
plt.show()
シミュレーションによるE[XY]の計算
import numpy as np
# シミュレーションの設定
num_samples = 100000 # サンプル数
# 指数分布に従う乱数 X を生成
X_samples = np.random.exponential(scale=1.0, size=num_samples)
# 関数 Y = h(X) = 1 - exp(-X) を適用して Y を計算
Y_samples = 1 - np.exp(-X_samples)
# XY の期待値を計算
XY_samples = X_samples * Y_samples
E_XY_simulation = np.mean(XY_samples)
# 結果の表示
print(f"シミュレーションによる E[XY] = {E_XY_simulation}")
print(f"理論値 E[XY] = 3/4 = {3/4}")シミュレーションによる E[XY] = 0.7473462073557277
理論値 E[XY] = 3/4 = 0.752021 Q1(3)
変数変換を用いて二つの分布の和の確率密度関数を求めました。

コード
数式を使った計算
# 2024 Q1(3) 2024.8.19
import sympy as sp
# シンボリック変数の定義
x, z = sp.symbols('x z')
# 確率密度関数の定義
f_X = sp.exp(-x) # f_X(x) = e^(-x)
f_Y = sp.Piecewise((1, (z - x >= 0) & (z - x <= 1)), (0, True)) # f_Y(z - x) for 0 < z - x < 1
# 一般的な積分の設定
f_Z_integral = sp.integrate(f_X * f_Y, (x, 0, z))
# 結果の簡略化
f_Z_general = sp.simplify(f_Z_integral)
# 結果の表示
display(f_Z_general)
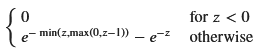
簡単のため、zの範囲を指定して再度計算
# 2024 Q1(3) 2024.8.19
import sympy as sp
# シンボリック変数の定義
x, z = sp.symbols('x z')
# 確率密度関数の定義
f_X = sp.exp(-x) # f_X(x) = e^(-x)
f_Y = 1 # f_Y(y) = 1 (0 < y < 1)
# 各範囲での計算
# 1. z <= 0 の場合
f_Z_1 = 0 # z <= 0 の場合は f_Z(z) = 0
# 2. 0 < z <= 1 の場合
f_Z_2_integral = sp.integrate(f_X * f_Y, (x, 0, z))
f_Z_2 = sp.simplify(f_Z_2_integral)
# 3. z > 1 の場合
f_Z_3_integral = sp.integrate(f_X * f_Y, (x, z-1, z))
f_Z_3 = sp.simplify(f_Z_3_integral)
# 結果の表示
print(f"f_Z(z) for z <= 0:")
display(f_Z_1)
print(f"f_Z(z) for 0 < z <= 1:")
display(f_Z_2)
print(f"f_Z(z) for z > 1:")
display(f_Z_3)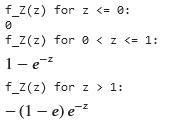
プロット
import numpy as np
import matplotlib.pyplot as plt
from scipy.integrate import quad
# 確率密度関数 f_X(x) と f_Y(y)
def f_X(x):
return np.exp(-x) if x > 0 else 0
def f_Y(y):
return 1 if 0 < y < 1 else 0
# Z = X + Y の確率密度関数 f_Z(z) の計算
def f_Z(z):
integrand = lambda x: f_X(x) * f_Y(z - x)
return quad(integrand, max(0, z-1), z)[0] #積分範囲を限定する場合
#return quad(integrand, 0, z, epsabs=1e-8, epsrel=1e-8)[0] #積分範囲を広くする場合
# z の範囲を設定し、f_Z(z) を計算
z_values = np.linspace(0, 5, 1000) # 増加させたサンプル数
f_Z_values = np.array([f_Z(z) for z in z_values])
# グラフの描画
plt.plot(z_values, f_Z_values, label='f_Z(z) = X + Y')
plt.xlabel('z')
plt.ylabel('確率密度')
plt.title('X + Y の確率密度関数')
plt.legend()
plt.grid(True)
plt.show()
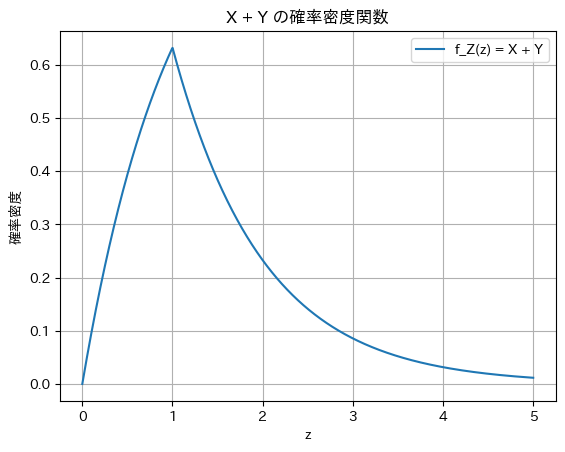
2021 Q1(1)(2)
指数分布と一様分布の期待値と、それらが独立な場合の積の期待値を求めました。
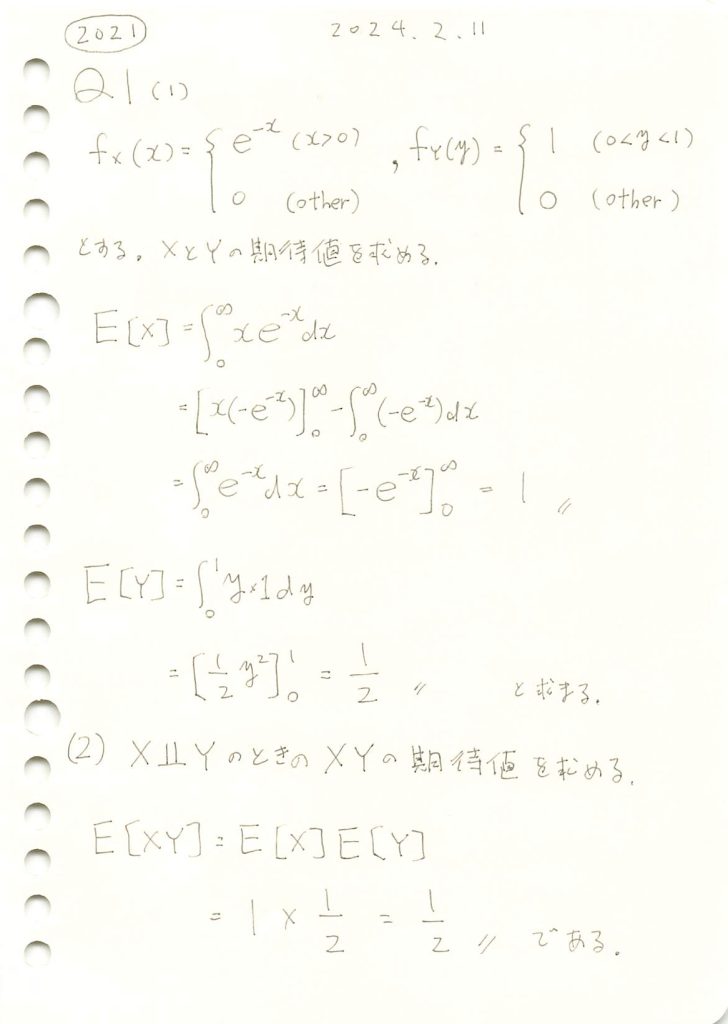
コード
数式を使った計算
# 2021 Q1(1)(2) 2024.8.18
import numpy as np
from scipy.integrate import quad
# Xの期待値の計算
def fx(x):
return x * np.exp(-x)
E_X, _ = quad(fx, 0, np.inf)
# Yの期待値の計算
def fy(y):
return y
E_Y, _ = quad(fy, 0, 1)
# XYの期待値の計算(独立の場合)
E_XY = E_X * E_Y
print(f"E[X] = {E_X}")
print(f"E[Y] = {E_Y}")
print(f"E[XY] (独立の場合) = {E_XY}")
E[X] = 0.9999999999999998
E[Y] = 0.5
E[XY] (独立の場合) = 0.4999999999999999シミュレーションによる計算
# 2021 Q1(1)(2) 2024.8.18
import numpy as np
# シミュレーションの設定
num_samples = 1000000 # サンプル数
# Xの乱数生成(指数分布)
X_samples = np.random.exponential(scale=1.0, size=num_samples)
# Yの乱数生成(一様分布)
Y_samples = np.random.uniform(0, 1, size=num_samples)
# (1) XとYの期待値の計算
E_X_simulation = np.mean(X_samples)
E_Y_simulation = np.mean(Y_samples)
# (2) XYの期待値の計算(独立な場合)
E_XY_simulation = np.mean(X_samples * Y_samples)
print(f"E[X] = {E_X_simulation}")
print(f"E[Y] = {E_Y_simulation}")
print(f"E[XY] = {E_XY_simulation}")
E[X] = 1.0001064255963075
E[Y] = 0.4998284579940602
E[XY] = 0.49980383195826882022 Q5(5)
欠損値がある場合の、分散分析に於けるF検定の影響に関する問をもう一問やりました。

コード
シミュレーションによる計算
# 2022 Q5(5) 2024.8.17
import numpy as np
# シミュレーションの設定
np.random.seed(42)
n = 5 # サンプル数
X = np.random.normal(10, 2, n) # Xの観測値
# Y1が非常に大きな値を取るケースを考慮
Y = np.random.normal(15, 2, n)
Y[0] = 1000 # Y1が非常に大きな値を取る設定
# 全体平均とY2:nの平均
Y_bar = np.mean(Y) # 全体の平均
Y_bar_2n = np.mean(Y[1:]) # Y2:n の平均
X_bar_2n = np.mean(X[1:]) # X2:n の平均
# θの推定値
theta_hat = Y_bar_2n - X_bar_2n
# SAの計算(Y1を含める場合)
SA_with_Y1 = np.sum(((X[1:] + Y[1:] - theta_hat) / 2 - X_bar_2n) ** 2) + (Y[0] - Y_bar) ** 2
SA_with_Y1 += np.sum(((X[1:] + Y[1:] + theta_hat) / 2 - Y_bar) ** 2)
# SAの計算(Y1を除く場合)
SA_without_Y1 = np.sum(((X[1:] + Y[1:] - theta_hat) / 2 - X_bar_2n) ** 2)
SA_without_Y1 += np.sum(((X[1:] + Y[1:] + theta_hat) / 2 - Y_bar_2n) ** 2)
# 結果を表示
{
"Y1を含めた場合の要因A平方和 (SA)": SA_with_Y1,
"Y1を除いた場合の要因A平方和 (SA)": SA_without_Y1
}{'Y1を含めた場合の要因A平方和 (SA)': 774276.0933538243,
'Y1を除いた場合の要因A平方和 (SA)': 1.6720954914667048}2022 Q5(4)
欠損値がある場合の、分散分析に於けるF検定の影響に関する問をやりました。

コード
シミュレーションによる計算
# 2022 Q5(4) 2024.8.16
import numpy as np
# シミュレーションのための設定
np.random.seed(42)
n = 5 # サンプル数
X = np.random.normal(10, 2, n) # Xの観測値
Y = np.random.normal(15, 2, n) # Yの観測値
# ケース1: Y1を含めた場合の計算
mu_0_1 = Y[0] # Y1に対応する μ_0
mu_i_with_Y1 = (X[1:] + Y[1:]) / 2 # 残りの μ_i の計算
SE_with_Y1 = np.sum((X[1:] - mu_i_with_Y1) ** 2) + np.sum((Y[1:] - mu_i_with_Y1) ** 2)
# Y1に対する特別な処理
SE_with_Y1 += (Y[0] - mu_0_1) ** 2 # Y1 の影響を追加
# ケース2: Y1を除いた場合の計算
mu_i_without_Y1 = (X[1:] + Y[1:]) / 2 # Y1を除いた場合の μ_i の計算
SE_without_Y1 = np.sum((X[1:] - mu_i_without_Y1) ** 2) + np.sum((Y[1:] - mu_i_without_Y1) ** 2)
# 要因Bに関する平方和(SB)の計算
mu_B_with_Y1 = np.mean(Y[1:]) # Y1を含めた場合のBの平均
mu_B_without_Y1 = np.mean(Y[1:]) # Y1を除いた場合のBの平均
# Y1専用の平均を計算してY1の寄与を計算
mu_0_Y1 = Y[0] # Y1専用の平均はY1自体
SB_with_Y1 = np.sum((Y[1:] - mu_B_with_Y1) ** 2)
SB_with_Y1 += (Y[0] - mu_0_Y1) ** 2 # Y1の寄与を専用の平均で追加
SB_without_Y1 = np.sum((Y[1:] - mu_B_without_Y1) ** 2)
# 結果を表示
{
"Y1を含めた場合の残差平方和 (SE)": SE_with_Y1,
"Y1を除いた場合の残差平方和 (SE)": SE_without_Y1,
"Y1を含めた場合の要因B平方和 (SB)": SB_with_Y1,
"Y1を除いた場合の要因B平方和 (SB)": SB_without_Y1,
}{'Y1を含めた場合の残差平方和 (SE)': 71.28917221001626,
'Y1を除いた場合の残差平方和 (SE)': 71.28917221001626,
'Y1を含めた場合の要因B平方和 (SB)': 8.53547835010338,
'Y1を除いた場合の要因B平方和 (SB)': 8.53547835010338}コメント
Y[0] – mu_0_1 と Y[0] – mu_0_Y1 が0になるので、Y1の有無が結果に影響しない。
2022 Q5(3)
分散分析の各要因の効果を検定する検定量と帰無分布を求めました。

コード
シミュレーションによる計算
# 2022 Q5(3) 2024.8.15
import numpy as np
import pandas as pd
import scipy.stats as stats
# シミュレーションのための設定
np.random.seed(42)
n = 10 # 因子Aの水準数
mu_A = [5, 10, 15] # 因子Aの水準ごとの平均
mu_B = [7, 12] # 因子Bの水準ごとの平均
sigma = 2 # 標準偏差
n_samples = n * 2 # 各水準ごとのサンプル数
# データ生成
data = np.zeros((n, 2))
for i in range(n):
data[i, 0] = np.random.normal(mu_A[i % len(mu_A)], sigma) # 因子A
data[i, 1] = np.random.normal(mu_B[i % len(mu_B)], sigma) # 因子B
# データフレームにまとめる
df = pd.DataFrame(data, columns=['A', 'B'])
# 全平均
m = df.mean().mean()
# 各水準での平均
m_Ai = df['A'].mean()
m_Bj = df['B'].mean()
# 偏差平方和の計算
SA = np.sum((df['A'] - m_Ai) ** 2)
SB = np.sum((df['B'] - m_Bj) ** 2)
SE = np.sum((df.values - m_Ai - m_Bj + m) ** 2)
# 自由度
phi_A = n - 1
phi_B = 1
phi_E = n - 1
# 分散分析の統計量
F_A = (SA / phi_A) / (SE / phi_E)
F_B = (SB / phi_B) / (SE / phi_E)
# p値の計算
p_A = 1 - stats.f.cdf(F_A, phi_A, phi_E)
p_B = 1 - stats.f.cdf(F_B, phi_B, phi_E)
# 結果の表示
{
"F_A": F_A,
"p_A": p_A,
"F_B": F_B,
"p_B": p_B,
"SA": SA,
"SB": SB,
"SE": SE,
"df_A": phi_A,
"df_B": phi_B,
"df_E": phi_E
}{'F_A': 0.5528514017044434,
'p_A': 0.8047382043674255,
'F_B': 4.023821861099081,
'p_B': 0.07582222108466219,
'SA': 139.17265361165713,
'SB': 112.54902298706004,
'SE': 251.73609614190576,
'df_A': 9,
'df_B': 1,
'df_E': 9}2022 Q5(2)
分散分析モデルのパラメータを求める問題をやりました。

コード
# 2022 Q5(2) 2024.8.14
import sympy as sp
# サンプル数を具体的な数値に設定
n = 3 # 例として n = 3 とする
# シンボリック変数の定義
mu = sp.symbols(f'mu_1:{n+1}') # mu_1, mu_2, mu_3 を定義
theta, nu = sp.symbols('theta nu')
a = sp.symbols(f'a_1:{n+1}') # a_1, a_2, a_3 を定義
b1, b2 = sp.symbols('b1 b2')
# 制約条件
constraint_a = sp.Eq(sum(a), 0)
constraint_b = sp.Eq(b1 + b2, 0)
# Z_{i1} = X_i の関係式
eq1 = sp.Eq(nu + a[0] + b1, mu[0])
# Z_{i2} = Y_i の関係式
eq2 = sp.Eq(nu + a[0] + b2, mu[0] + theta)
# b1, b2 の解を求める
solution_b = sp.solve([constraint_b, b2 - b1 - theta], (b1, b2))
b1_solution = solution_b[b1]
b2_solution = solution_b[b2]
# νとa_iを求めるための方程式
nu_a_eq = eq1.subs({b1: b1_solution})
# νを求める
nu_solution = sp.solve(nu_a_eq, nu)[0]
# a_iの解
a_solution = [mu[i] - sp.symbols('mu_bar') for i in range(n)]
# 結果を表示
display(nu_solution, a_solution, b1_solution, b2_solution)

