独立した二つの自由度1のカイ二乗分布の差を幾何平均と2でスケールした式の確率密度関数を導出しました。

コード
Tについてシミュレーションし、確率密度関数 と一致するか確認をします。
と一致するか確認をします。
# 2017 Q5(3) 2024.11.10
import numpy as np
import matplotlib.pyplot as plt
# サンプルサイズ
n_samples = 100000
# 自由度1のカイ二乗分布からサンプルを生成
X = np.random.chisquare(df=1, size=n_samples)
Y = np.random.chisquare(df=1, size=n_samples)
# 確率変数 T = (X - Y) / (2 * sqrt(X * Y)) の計算
T = (X - Y) / (2 * np.sqrt(X * Y))
# 理論的な確率密度関数 h(t) の定義
def theoretical_h(t):
return 1 / (np.pi * (1 + t**2))
# x 軸の範囲を設定し、h(t) を計算
x = np.linspace(-10, 10, 100)
h_t = theoretical_h(x)
# グラフの描画
plt.hist(T, bins=200, density=True, alpha=0.5, range=(-10, 10), label='シミュレーションによる $T$')
plt.plot(x, h_t, 'r-', label='理論的な $h(t) = \\frac{1}{\\pi(1+t^2)}$')
plt.xlabel('$T$')
plt.ylabel('密度')
plt.legend()
plt.title('確率変数 $T$ のシミュレーションと理論密度関数')
plt.show()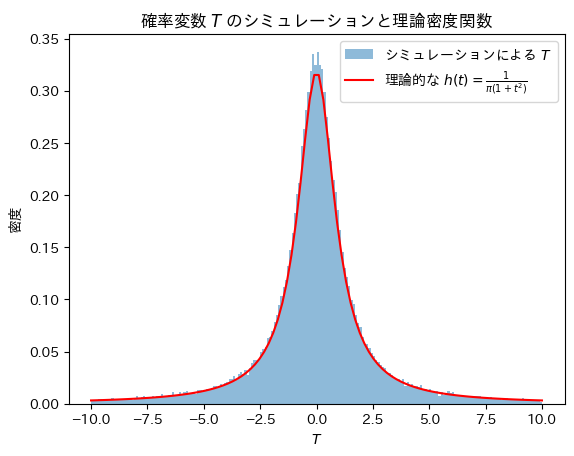
Tの分布は確率密度関数と一致することが確認できました。
なお、Tの分布は標準コーシー分布と呼ばれます。