線形モデルの未知の母数βの2つの推定量が不偏推定量であることを確認しました。

コード
乱数を発生させて線形モデルのパラメータβの推定量b0,b1をそれぞれ求め、観測データとともにプロットしてみます。推定された直線と真の直線がどのように異なるか視覚的に確認してみます。
# 2016 Q3(1) 2024.11.20
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
n = 50 # サンプルサイズ
true_beta = 2 # 真のβ
sigma = 5 # 誤差の標準偏差
# 1. xi を一様分布から生成
xi = np.random.uniform(1, 10, n)
# 2. εi を正規分布から生成
epsilon_i = np.random.normal(0, sigma, n)
# 3. Yi を計算
Yi = true_beta * xi + epsilon_i
# 4. 推定量 b0, b1 を計算
b0 = np.mean(Yi / xi)
b1 = np.sum(Yi) / np.sum(xi)
# プロット
plt.figure(figsize=(10, 6))
plt.scatter(xi, Yi, label='観測データ ($Y_i$)', color='blue', marker='x')
plt.plot(np.sort(xi), true_beta * np.sort(xi), label=f'真の直線 ($\\beta={true_beta}$)', color='green', linestyle='dashed')
plt.plot(np.sort(xi), b0 * np.sort(xi), label=f'推定直線 ($b_0={b0:.2f}$)', color='red')
plt.plot(np.sort(xi), b1 * np.sort(xi), label=f'推定直線 ($b_1={b1:.2f}$)', color='orange')
plt.xlabel('$x_i$')
plt.ylabel('$Y_i$')
plt.title('線形モデルの推定')
plt.legend()
plt.grid(True)
plt.show()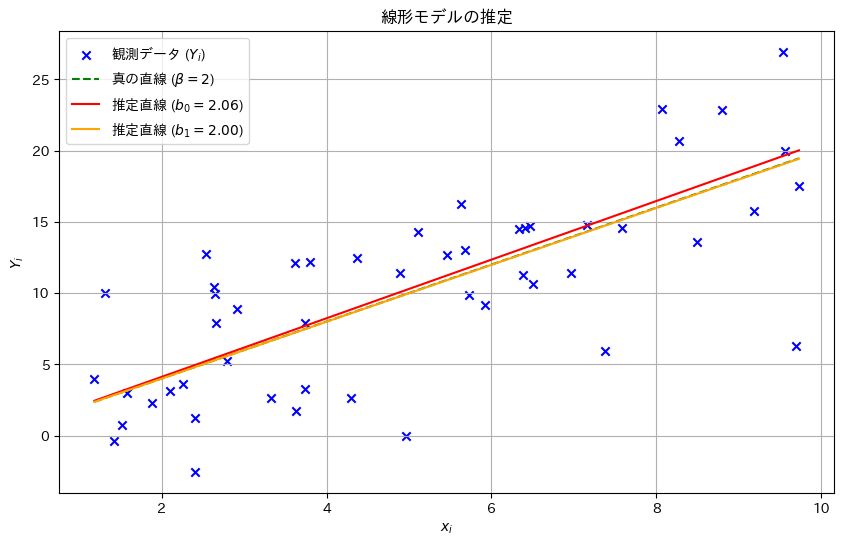
b0とb1は真のβに近い値を取り、直線は概ね一致しました。
次に、サンプル数nを変化させて、推定量b0,b1がどのように変化するのか観察します
# 2016 Q3(1) 2024.11.20
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
n = 50 # サンプルサイズ
true_beta = 2 # 真のβ
sigma = 5 # 誤差の標準偏差
# サンプルサイズを変化させて b0, b1 の期待値を検証
sample_sizes = np.arange(5, 101, 5) # n を 5 から 100 まで 5 刻みで変化
true_beta = 2 # 真のβ
simulations = 1000 # 各 n に対してのシミュレーション回数
b0_means = []
b1_means = []
# 各サンプルサイズ n に対してシミュレーションを実行
for n in sample_sizes:
b0_samples = []
b1_samples = []
for _ in range(simulations):
xi = np.random.uniform(1, 10, n)
epsilon_i = np.random.normal(0, sigma, n)
Yi = true_beta * xi + epsilon_i
b0_samples.append(np.mean(Yi / xi))
b1_samples.append(np.sum(Yi) / np.sum(xi))
b0_means.append(np.mean(b0_samples))
b1_means.append(np.mean(b1_samples))
# 結果をプロット
plt.figure(figsize=(10, 6))
plt.plot(sample_sizes, b0_means, label='$b_0$の期待値', marker='o', linestyle='dashed', color='red')
plt.plot(sample_sizes, b1_means, label='$b_1$の期待値', marker='x', linestyle='dashed', color='orange')
plt.axhline(y=true_beta, color='green', linestyle='solid', label='真の値 $\\beta=2$')
plt.xlabel('サンプルサイズ $n$')
plt.ylabel('推定量の期待値')
plt.title('推定量 $b_0, b_1$ の期待値とサンプルサイズの関係')
plt.legend()
plt.grid(True)
plt.show()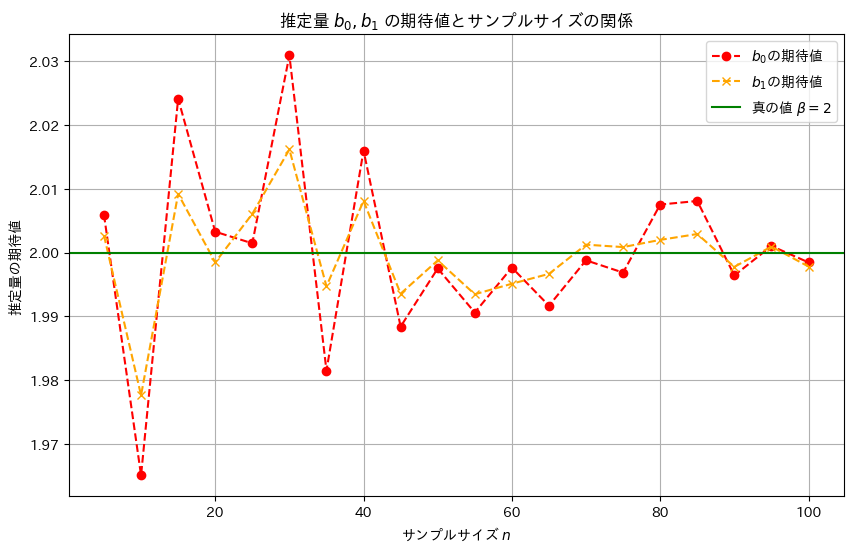
サンプルサイズnが大きくなるほど、推定量b0,b1は真の値βに近づくことが確認できました。また、b1の分散はb0の分散より小さく見え、b1はb0より安定した推定量のようです。
次に、推定量b0,b1の分布を確認してみます。それぞれのヒストグラムを重ねて表示してみます。
# 2016 Q3(1) 2024.11.20
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
n = 100 # サンプルサイズ
true_beta = 2 # 真のβ
sigma = 1 # 誤差の標準偏差
simulations = 10000 # シミュレーション回数
b0_samples = []
b1_samples = []
# シミュレーションを実施
for _ in range(simulations):
xi = np.random.uniform(1, 10, n)
epsilon_i = np.random.normal(0, sigma, n)
Yi = true_beta * xi + epsilon_i
b0_samples.append(np.mean(Yi / xi))
b1_samples.append(np.sum(Yi) / np.sum(xi))
# b0 と b1 の分布を重ねてプロット
plt.figure(figsize=(10, 6))
plt.hist(b0_samples, bins=30, density=True, color='red', alpha=0.5, label='$b_0$')
plt.hist(b1_samples, bins=30, density=True, color='orange', alpha=0.5, label='$b_1$')
plt.axvline(x=true_beta, color='green', linestyle='dashed', label='真の値 $\\beta=2$')
plt.title('$b_0$ と $b_1$ の分布 (n=100)')
plt.xlabel('推定値')
plt.ylabel('頻度')
plt.legend()
plt.grid(True)
plt.show()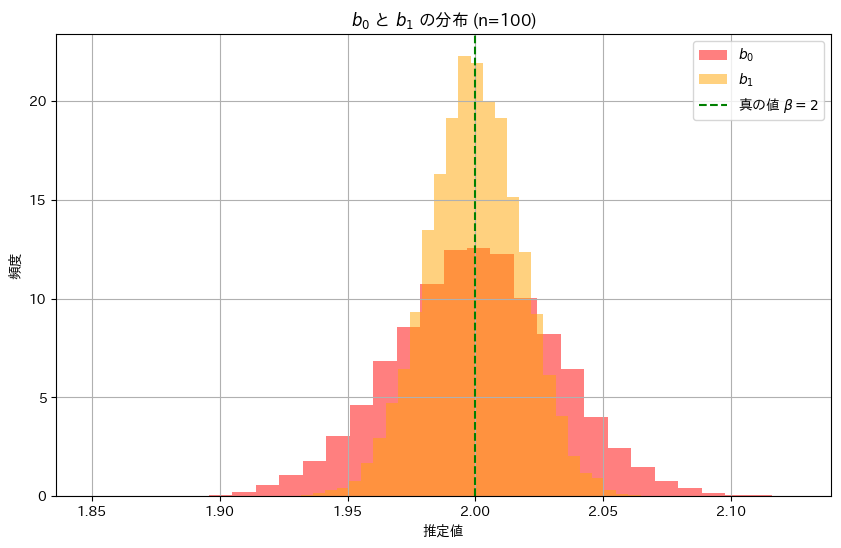
推定量b1の分布は、推定量b0の分布に比べて幅が狭く、b1の分散のほうがb0よりも小さく、安定した推定であることが分かりました。