テレビ番組の視聴満足回数の調査で満足と答えた回数のそれぞれ人数の適合度検定のための尤度比検定量と自由度を求めました。

コード
多項確率 が、
が、 に忠実に基づく場合と、ランダムにノイズを加えた(ズレた)場合についてシミュレーションを行い、尤度比統計量とp-値を計算して比較します。
に忠実に基づく場合と、ランダムにノイズを加えた(ズレた)場合についてシミュレーションを行い、尤度比統計量とp-値を計算して比較します。
# 2014 Q5(3) 2025.1.17
import numpy as np
from scipy.stats import chi2
import matplotlib.pyplot as plt
# シミュレーションの設定
n = 100 # 人数
p_true = 0.6 # 真の成功確率
categories = np.arange(5) # カテゴリ (0~4)
n_simulations = 1000 # シミュレーション回数
# 二項分布モデルに基づく q_j の計算 (忠実な設定)
qj_true = [np.math.comb(4, j) * (p_true ** j) * ((1 - p_true) ** (4 - j)) for j in categories]
# 二項分布に従わない (qj_noisy): q_j をランダムに変更してズラす
qj_noisy = np.array(qj_true) + np.random.uniform(-0.1, 0.1, size=len(qj_true))
qj_noisy = np.clip(qj_noisy, 0, None) # 確率が0未満にならないようにする
qj_noisy = qj_noisy / np.sum(qj_noisy) # 確率なので正規化
# 尤度比統計量を記録するリスト
likelihood_ratio_true = []
p_values_true = []
likelihood_ratio_noisy = []
p_values_noisy = []
for _ in range(n_simulations):
# 忠実なモデルの観測データ
obs_true = np.random.multinomial(n, qj_true)
exp_true = n * np.array(qj_true)
likelihood_stat_true = 2 * np.sum(obs_true * np.log(obs_true / exp_true, where=(obs_true > 0)))
p_val_true = 1 - chi2.cdf(likelihood_stat_true, df=3) # 自由度 = カテゴリ数 - 1 - 推定パラメータ数
likelihood_ratio_true.append(likelihood_stat_true)
p_values_true.append(p_val_true)
# ズレたモデルの観測データ
obs_noisy = np.random.multinomial(n, qj_noisy)
exp_noisy = n * np.array(qj_true) # 忠実な期待値を使用
likelihood_stat_noisy = 2 * np.sum(obs_noisy * np.log(obs_noisy / exp_noisy, where=(obs_noisy > 0)))
p_val_noisy = 1 - chi2.cdf(likelihood_stat_noisy, df=3)
likelihood_ratio_noisy.append(likelihood_stat_noisy)
p_values_noisy.append(p_val_noisy)
# 平均尤度比統計量を計算
mean_likelihood_true = np.mean(likelihood_ratio_true)
mean_likelihood_noisy = np.mean(likelihood_ratio_noisy)
# カイ二乗分布のPDFを計算
x = np.linspace(0, 20, 500) # x軸の範囲
pdf = chi2.pdf(x, df=3) # 自由度3のPDF
# 結果の出力
print(f"忠実なモデルの平均尤度比統計量: {mean_likelihood_true:.4f}")
print(f"忠実なモデルの平均p値: {np.mean(p_values_true):.4f}")
print(f"ズレたモデルの平均尤度比統計量: {mean_likelihood_noisy:.4f}")
print(f"ズレたモデルの平均p値: {np.mean(p_values_noisy):.4f}")
# グラフの描画
plt.figure(figsize=(10, 6))
plt.plot(x, pdf, label="自由度3のカイ二乗分布", linewidth=2)
plt.axvline(mean_likelihood_true, color="blue", linestyle="--", label=f"忠実モデルの平均: {mean_likelihood_true:.2f}")
plt.axvline(mean_likelihood_noisy, color="red", linestyle="--", label=f"ズレモデルの平均: {mean_likelihood_noisy:.2f}")
plt.xlabel("$X^2$ 値", fontsize=12)
plt.ylabel("確率密度", fontsize=12)
plt.title("自由度3のカイ二乗分布と平均尤度比統計量", fontsize=14)
plt.legend(fontsize=12)
plt.grid(alpha=0.5)
plt.show()忠実なモデルの平均尤度比統計量: 3.9418
忠実なモデルの平均p値: 0.3909
ズレたモデルの平均尤度比統計量: 16.7360
ズレたモデルの平均p値: 0.0081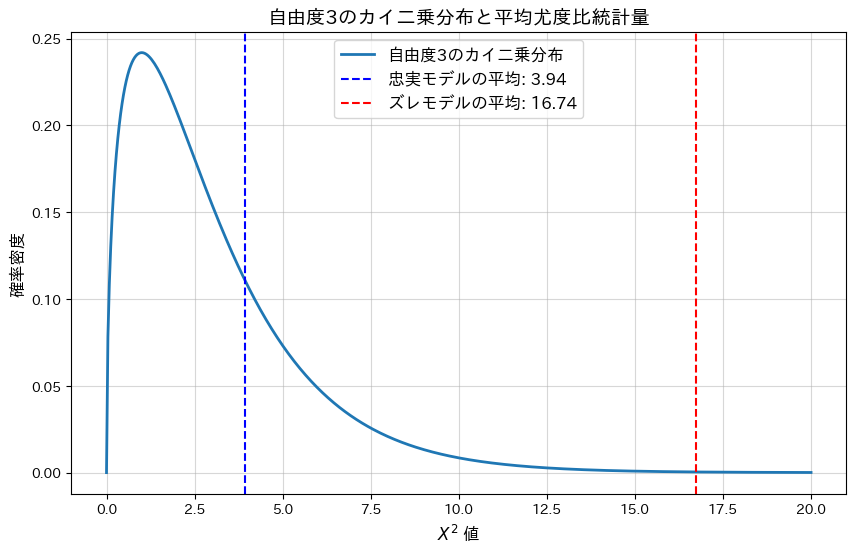
忠実なモデルの平均p-値は大きく、モデルによく適合していることが分かります。一方、ランダムにノイズを加えた(ズレた)モデルではp-値が0.05以下となり、モデルがデータに適合していないことが分かります。